 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
Articulat3D: Reconstructing Articulated Digital Twins From Monocular Videos with Geometric and Motion Constraints
Mar 12, 2026Building high-fidelity digital twins of articulated objects from visual data remains a central challenge. Existing approaches depend on multi-view captures of the object in discrete, static states, which severely constrains their real-world scalability. In this paper, we introduce Articulat3D, a novel framework that constructs such digital twins from casually captured monocular videos by jointly enforcing explicit 3D geometric and motion constraints. We first propose Motion Prior-Driven Initialization, which leverages 3D point tracks to exploit the low-dimensional structure of articulated motion. By modeling scene dynamics with a compact set of motion bases, we facilitate soft decomposition of the scene into multiple rigidly-moving groups. Building on this initialization, we introduce Geometric and Motion Constraints Refinement, which enforces physically plausible articulation through learnable kinematic primitives parameterized by a joint axis, a pivot point, and per-frame motion scalars, yielding reconstructions that are both geometrically accurate and temporally coherent. Extensive experiments demonstrate that Articulat3D achieves state-of-the-art performance on synthetic benchmarks and real-world casually captured monocular videos, significantly advancing the feasibility of digital twin creation under uncontrolled real-world conditions. Our project page is at https://maxwell-zhao.github.io/Articulat3D.
Divide, Conquer and Unite: Hierarchical Style-Recalibrated Prototype Alignment for Federated Medical Image Segmentation
Nov 14, 2025Federated learning enables multiple medical institutions to train a global model without sharing data, yet feature heterogeneity from diverse scanners or protocols remains a major challenge. Many existing works attempt to address this issue by leveraging model representations (e.g., mean feature vectors) to correct local training; however, they often face two key limitations: 1) Incomplete Contextual Representation Learning: Current approaches primarily focus on final-layer features, overlooking critical multi-level cues and thus diluting essential context for accurate segmentation. 2) Layerwise Style Bias Accumulation: Although utilizing representations can partially align global features, these methods neglect domain-specific biases within intermediate layers, allowing style discrepancies to build up and reduce model robustness. To address these challenges, we propose FedBCS to bridge feature representation gaps via domain-invariant contextual prototypes alignment. Specifically, we introduce a frequency-domain adaptive style recalibration into prototype construction that not only decouples content-style representations but also learns optimal style parameters, enabling more robust domain-invariant prototypes. Furthermore, we design a context-aware dual-level prototype alignment method that extracts domain-invariant prototypes from different layers of both encoder and decoder and fuses them with contextual information for finer-grained representation alignment. Extensive experiments on two public datasets demonstrate that our method exhibits remarkable performance.
pFedSAM: Personalized Federated Learning of Segment Anything Model for Medical Image Segmentation
Sep 19, 2025Medical image segmentation is crucial for computer-aided diagnosis, yet privacy constraints hinder data sharing across institutions. Federated learning addresses this limitation, but existing approaches often rely on lightweight architectures that struggle with complex, heterogeneous data. Recently, the Segment Anything Model (SAM) has shown outstanding segmentation capabilities; however, its massive encoder poses significant challenges in federated settings. In this work, we present the first personalized federated SAM framework tailored for heterogeneous data scenarios in medical image segmentation. Our framework integrates two key innovations: (1) a personalized strategy that aggregates only the global parameters to capture cross-client commonalities while retaining the designed L-MoE (Localized Mixture-of-Experts) component to preserve domain-specific features; and (2) a decoupled global-local fine-tuning mechanism that leverages a teacher-student paradigm via knowledge distillation to bridge the gap between the global shared model and the personalized local models, thereby mitigating overgeneralization. Extensive experiments on two public datasets validate that our approach significantly improves segmentation performance, achieves robust cross-domain adaptation, and reduces communication overhead.
Towards Affordance-Aware Robotic Dexterous Grasping with Human-like Priors
Aug 12, 2025A dexterous hand capable of generalizable grasping objects is fundamental for the development of general-purpose embodied AI. However, previous methods focus narrowly on low-level grasp stability metrics, neglecting affordance-aware positioning and human-like poses which are crucial for downstream manipulation. To address these limitations, we propose AffordDex, a novel framework with two-stage training that learns a universal grasping policy with an inherent understanding of both motion priors and object affordances. In the first stage, a trajectory imitator is pre-trained on a large corpus of human hand motions to instill a strong prior for natural movement. In the second stage, a residual module is trained to adapt these general human-like motions to specific object instances. This refinement is critically guided by two components: our Negative Affordance-aware Segmentation (NAA) module, which identifies functionally inappropriate contact regions, and a privileged teacher-student distillation process that ensures the final vision-based policy is highly successful. Extensive experiments demonstrate that AffordDex not only achieves universal dexterous grasping but also remains remarkably human-like in posture and functionally appropriate in contact location. As a result, AffordDex significantly outperforms state-of-the-art baselines across seen objects, unseen instances, and even entirely novel categories.
ActiveSSF: An Active-Learning-Guided Self-Supervised Framework for Long-Tailed Megakaryocyte Classification
Feb 12, 2025Precise classification of megakaryocytes is crucial for diagnosing myelodysplastic syndromes. Although self-supervised learning has shown promise in medical image analysis, its application to classifying megakaryocytes in stained slides faces three main challenges: (1) pervasive background noise that obscures cellular details, (2) a long-tailed distribution that limits data for rare subtypes, and (3) complex morphological variations leading to high intra-class variability. To address these issues, we propose the ActiveSSF framework, which integrates active learning with self-supervised pretraining. Specifically, our approach employs Gaussian filtering combined with K-means clustering and HSV analysis (augmented by clinical prior knowledge) for accurate region-of-interest extraction; an adaptive sample selection mechanism that dynamically adjusts similarity thresholds to mitigate class imbalance; and prototype clustering on labeled samples to overcome morphological complexity. Experimental results on clinical megakaryocyte datasets demonstrate that ActiveSSF not only achieves state-of-the-art performance but also significantly improves recognition accuracy for rare subtypes. Moreover, the integration of these advanced techniques further underscores the practical potential of ActiveSSF in clinical settings. To foster further research, the code and datasets will be publicly released in the future.
Automated 3D Physical Simulation of Open-world Scene with Gaussian Splatting
Nov 19, 2024
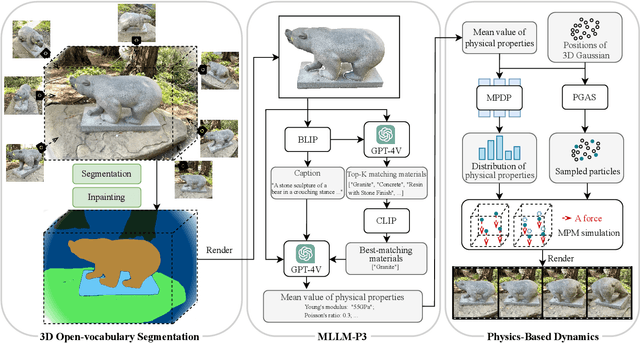
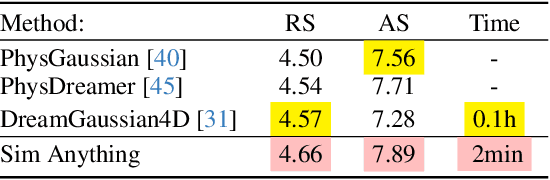
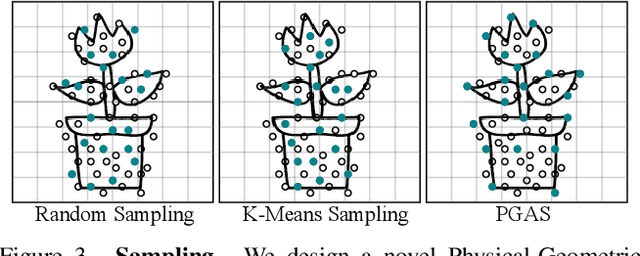
Recent advancements in 3D generation models have opened new possibilities for simulating dynamic 3D object movements and customizing behaviors, yet creating this content remains challenging. Current methods often require manual assignment of precise physical properties for simulations or rely on video generation models to predict them, which is computationally intensive. In this paper, we rethink the usage of multi-modal large language model (MLLM) in physics-based simulation, and present Sim Anything, a physics-based approach that endows static 3D objects with interactive dynamics. We begin with detailed scene reconstruction and object-level 3D open-vocabulary segmentation, progressing to multi-view image in-painting. Inspired by human visual reasoning, we propose MLLM-based Physical Property Perception (MLLM-P3) to predict mean physical properties of objects in a zero-shot manner. Based on the mean values and the object's geometry, the Material Property Distribution Prediction model (MPDP) model then estimates the full distribution, reformulating the problem as probability distribution estimation to reduce computational costs. Finally, we simulate objects in an open-world scene with particles sampled via the Physical-Geometric Adaptive Sampling (PGAS) strategy, efficiently capturing complex deformations and significantly reducing computational costs. Extensive experiments and user studies demonstrate our Sim Anything achieves more realistic motion than state-of-the-art methods within 2 minutes on a single GPU.
SG-GS: Photo-realistic Animatable Human Avatars with Semantically-Guided Gaussian Splatting
Aug 19, 2024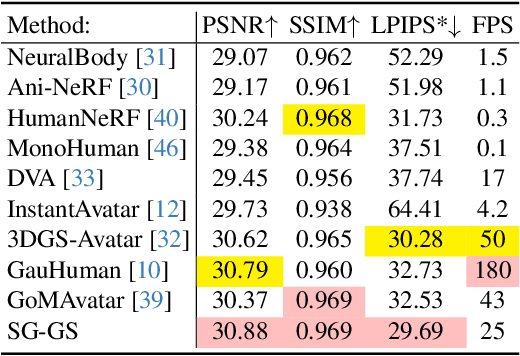
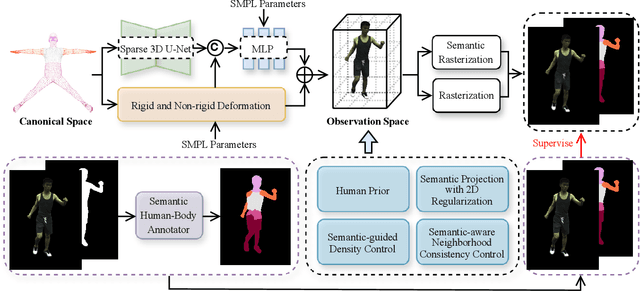
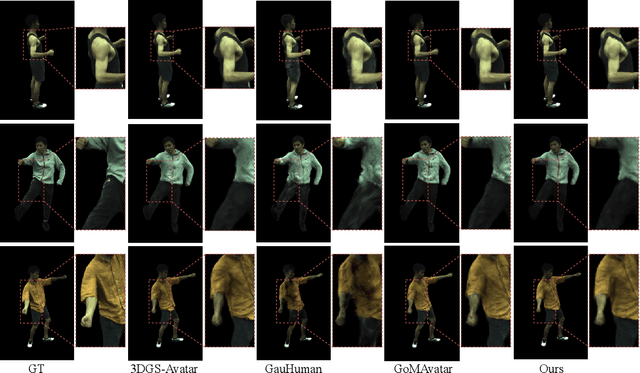
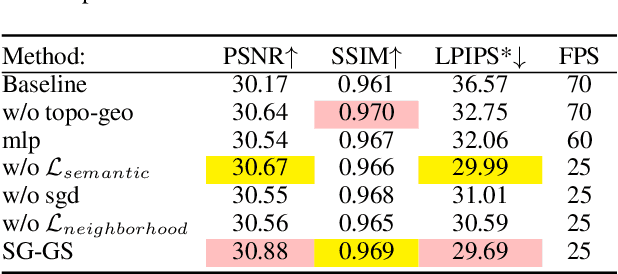
Reconstructing photo-realistic animatable human avatars from monocular videos remains challenging in computer vision and graphics. Recently, methods using 3D Gaussians to represent the human body have emerged, offering faster optimization and real-time rendering. However, due to ignoring the crucial role of human body semantic information which represents the intrinsic structure and connections within the human body, they fail to achieve fine-detail reconstruction of dynamic human avatars. To address this issue, we propose SG-GS, which uses semantics-embedded 3D Gaussians, skeleton-driven rigid deformation, and non-rigid cloth dynamics deformation to create photo-realistic animatable human avatars from monocular videos. We then design a Semantic Human-Body Annotator (SHA) which utilizes SMPL's semantic prior for efficient body part semantic labeling. The generated labels are used to guide the optimization of Gaussian semantic attributes. To address the limited receptive field of point-level MLPs for local features, we also propose a 3D network that integrates geometric and semantic associations for human avatar deformation. We further implement three key strategies to enhance the semantic accuracy of 3D Gaussians and rendering quality: semantic projection with 2D regularization, semantic-guided density regularization and semantic-aware regularization with neighborhood consistency. Extensive experiments demonstrate that SG-GS achieves state-of-the-art geometry and appearance reconstruction performance.
SAM-Driven Weakly Supervised Nodule Segmentation with Uncertainty-Aware Cross Teaching
Jul 18, 2024



Automated nodule segmentation is essential for computer-assisted diagnosis in ultrasound images. Nevertheless, most existing methods depend on precise pixel-level annotations by medical professionals, a process that is both costly and labor-intensive. Recently, segmentation foundation models like SAM have shown impressive generalizability on natural images, suggesting their potential as pseudo-labelers. However, accurate prompts remain crucial for their success in medical images. In this work, we devise a novel weakly supervised framework that effectively utilizes the segmentation foundation model to generate pseudo-labels from aspect ration annotations for automatic nodule segmentation. Specifically, we develop three types of bounding box prompts based on scalable shape priors, followed by an adaptive pseudo-label selection module to fully exploit the prediction capabilities of the foundation model for nodules. We also present a SAM-driven uncertainty-aware cross-teaching strategy. This approach integrates SAM-based uncertainty estimation and label-space perturbations into cross-teaching to mitigate the impact of pseudo-label inaccuracies on model training. Extensive experiments on two clinically collected ultrasound datasets demonstrate the superior performance of our proposed method.
HFGS: 4D Gaussian Splatting with Emphasis on Spatial and Temporal High-Frequency Components for Endoscopic Scene Reconstruction
May 29, 2024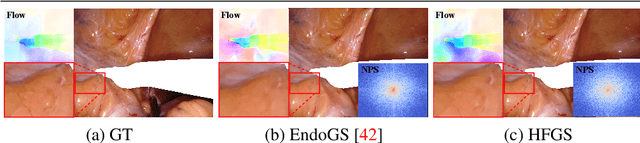
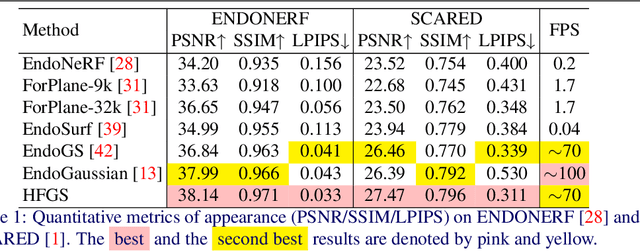
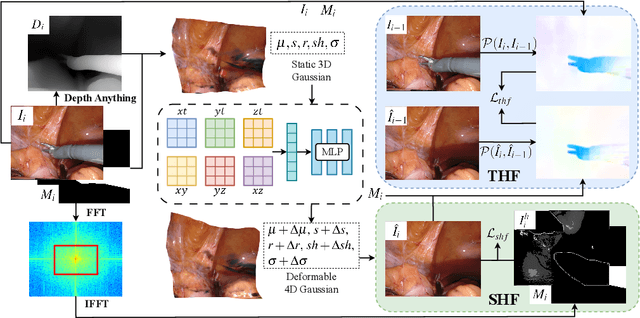
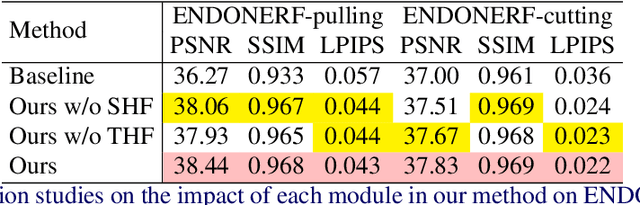
Robot-assisted minimally invasive surgery benefits from enhancing dynamic scene reconstruction, as it improves surgical outcomes. While Neural Radiance Fields (NeRF) have been effective in scene reconstruction, their slow inference speeds and lengthy training durations limit their applicability. To overcome these limitations, 3D Gaussian Splatting (3D-GS) based methods have emerged as a recent trend, offering rapid inference capabilities and superior 3D quality. However, these methods still struggle with under-reconstruction in both static and dynamic scenes. In this paper, we propose HFGS, a novel approach for deformable endoscopic reconstruction that addresses these challenges from spatial and temporal frequency perspectives. Our approach incorporates deformation fields to better handle dynamic scenes and introduces Spatial High-Frequency Emphasis Reconstruction (SHF) to minimize discrepancies in spatial frequency spectra between the rendered image and its ground truth. Additionally, we introduce Temporal High-Frequency Emphasis Reconstruction (THF) to enhance dynamic awareness in neural rendering by leveraging flow priors, focusing optimization on motion-intensive parts. Extensive experiments on two widely used benchmarks demonstrate that HFGS achieves superior rendering quality. Our code will be available.