 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove the autonomy of the SE2(3) group based Extended Kalman Filter for Integrated Navigation: Application
Jan 25, 2026One of the core advantages of SE2(3) Lie group framework for navigation modeling lies in the autonomy of error propagation. In the previous paper, the theoretical analysis of autonomy property of navigation model in inertial, earth and world frames was given. A construction method for SE2(3) group navigation model is proposed to improve the non-inertial navigation model toward full autonomy. This paper serves as a counterpart to previous paper and conducts the real-world strapdown inertial navigation system (SINS)/odometer(ODO) experiments as well as Monte-Carlo simulations to demonstrate the performance of improved SE2(3) group based high-precision navigation models.
CSASN: A Multitask Attention-Based Framework for Heterogeneous Thyroid Carcinoma Classification in Ultrasound Images
May 04, 2025Heterogeneous morphological features and data imbalance pose significant challenges in rare thyroid carcinoma classification using ultrasound imaging. To address this issue, we propose a novel multitask learning framework, Channel-Spatial Attention Synergy Network (CSASN), which integrates a dual-branch feature extractor - combining EfficientNet for local spatial encoding and ViT for global semantic modeling, with a cascaded channel-spatial attention refinement module. A residual multiscale classifier and dynamically weighted loss function further enhance classification stability and accuracy. Trained on a multicenter dataset comprising more than 2000 patients from four clinical institutions, our framework leverages a residual multiscale classifier and dynamically weighted loss function to enhance classification stability and accuracy. Extensive ablation studies demonstrate that each module contributes significantly to model performance, particularly in recognizing rare subtypes such as FTC and MTC carcinomas. Experimental results show that CSASN outperforms existing single-stream CNN or Transformer-based models, achieving a superior balance between precision and recall under class-imbalanced conditions. This framework provides a promising strategy for AI-assisted thyroid cancer diagnosis.
Detection of Disease on Nasal Breath Sound by New Lightweight Architecture: Using COVID-19 as An Example
Apr 01, 2025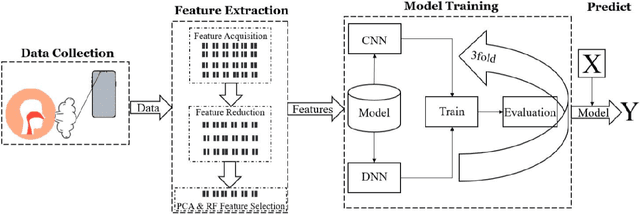



Background. Infectious diseases, particularly COVID-19, continue to be a significant global health issue. Although many countries have reduced or stopped large-scale testing measures, the detection of such diseases remains a propriety. Objective. This study aims to develop a novel, lightweight deep neural network for efficient, accurate, and cost-effective detection of COVID-19 using a nasal breathing audio data collected via smartphones. Methodology. Nasal breathing audio from 128 patients diagnosed with the Omicron variant was collected. Mel-Frequency Cepstral Coefficients (MFCCs), a widely used feature in speech and sound analysis, were employed for extracting important characteristics from the audio signals. Additional feature selection was performed using Random Forest (RF) and Principal Component Analysis (PCA) for dimensionality reduction. A Dense-ReLU-Dropout model was trained with K-fold cross-validation (K=3), and performance metrics like accuracy, precision, recall, and F1-score were used to evaluate the model. Results. The proposed model achieved 97% accuracy in detecting COVID-19 from nasal breathing sounds, outperforming state-of-the-art methods such as those by [23] and [13]. Our Dense-ReLU-Dropout model, using RF and PCA for feature selection, achieves high accuracy with greater computational efficiency compared to existing methods that require more complex models or larger datasets. Conclusion. The findings suggest that the proposed method holds significant potential for clinical implementation, advancing smartphone-based diagnostics in infectious diseases. The Dense-ReLU-Dropout model, combined with innovative feature processing techniques, offers a promising approach for efficient and accurate COVID-19 detection, showcasing the capabilities of mobile device-based diagnostics
An Efficient Hierarchical Preconditioner-Learner Architecture for Reconstructing Multi-scale Basis Functions of High-dimensional Subsurface Fluid Flow
Nov 01, 2024Modeling subsurface fluid flow in porous media is crucial for applications such as oil and gas exploration. However, the inherent heterogeneity and multi-scale characteristics of these systems pose significant challenges in accurately reconstructing fluid flow behaviors. To address this issue, we proposed Fourier Preconditioner-based Hierarchical Multiscale Net (FP-HMsNet), an efficient hierarchical preconditioner-learner architecture that combines Fourier Neural Operators (FNO) with multi-scale neural networks to reconstruct multi-scale basis functions of high-dimensional subsurface fluid flow. Using a dataset comprising 102,757 training samples, 34,252 validation samples, and 34,254 test samples, we ensured the reliability and generalization capability of the model. Experimental results showed that FP-HMsNet achieved an MSE of 0.0036, an MAE of 0.0375, and an R2 of 0.9716 on the testing set, significantly outperforming existing models and demonstrating exceptional accuracy and generalization ability. Additionally, robustness tests revealed that the model maintained stability under various levels of noise interference. Ablation studies confirmed the critical contribution of the preconditioner and multi-scale pathways to the model's performance. Compared to current models, FP-HMsNet not only achieved lower errors and higher accuracy but also demonstrated faster convergence and improved computational efficiency, establishing itself as the state-of-the-art (SOTA) approach. This model offers a novel method for efficient and accurate subsurface fluid flow modeling, with promising potential for more complex real-world applications.
SAM-Driven Weakly Supervised Nodule Segmentation with Uncertainty-Aware Cross Teaching
Jul 18, 2024



Automated nodule segmentation is essential for computer-assisted diagnosis in ultrasound images. Nevertheless, most existing methods depend on precise pixel-level annotations by medical professionals, a process that is both costly and labor-intensive. Recently, segmentation foundation models like SAM have shown impressive generalizability on natural images, suggesting their potential as pseudo-labelers. However, accurate prompts remain crucial for their success in medical images. In this work, we devise a novel weakly supervised framework that effectively utilizes the segmentation foundation model to generate pseudo-labels from aspect ration annotations for automatic nodule segmentation. Specifically, we develop three types of bounding box prompts based on scalable shape priors, followed by an adaptive pseudo-label selection module to fully exploit the prediction capabilities of the foundation model for nodules. We also present a SAM-driven uncertainty-aware cross-teaching strategy. This approach integrates SAM-based uncertainty estimation and label-space perturbations into cross-teaching to mitigate the impact of pseudo-label inaccuracies on model training. Extensive experiments on two clinically collected ultrasound datasets demonstrate the superior performance of our proposed method.
Ultrasound Nodule Segmentation Using Asymmetric Learning with Simple Clinical Annotation
Apr 23, 2024Recent advances in deep learning have greatly facilitated the automated segmentation of ultrasound images, which is essential for nodule morphological analysis. Nevertheless, most existing methods depend on extensive and precise annotations by domain experts, which are labor-intensive and time-consuming. In this study, we suggest using simple aspect ratio annotations directly from ultrasound clinical diagnoses for automated nodule segmentation. Especially, an asymmetric learning framework is developed by extending the aspect ratio annotations with two types of pseudo labels, i.e., conservative labels and radical labels, to train two asymmetric segmentation networks simultaneously. Subsequently, a conservative-radical-balance strategy (CRBS) strategy is proposed to complementally combine radical and conservative labels. An inconsistency-aware dynamically mixed pseudo-labels supervision (IDMPS) module is introduced to address the challenges of over-segmentation and under-segmentation caused by the two types of labels. To further leverage the spatial prior knowledge provided by clinical annotations, we also present a novel loss function namely the clinical anatomy prior loss. Extensive experiments on two clinically collected ultrasound datasets (thyroid and breast) demonstrate the superior performance of our proposed method, which can achieve comparable and even better performance than fully supervised methods using ground truth annotations.