 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Addressing Overthinking in Large Vision-Language Models via Gated Perception-Reasoning Optimization
Jan 07, 2026Large Vision-Language Models (LVLMs) have exhibited strong reasoning capabilities through chain-of-thought mechanisms that generate step-by-step rationales. However, such slow-thinking approaches often lead to overthinking, where models produce excessively verbose responses even for simple queries, resulting in test-time inefficiency and even degraded accuracy. Prior work has attempted to mitigate this issue via adaptive reasoning strategies, but these methods largely overlook a fundamental bottleneck: visual perception failures. We argue that stable reasoning critically depends on low-level visual grounding, and that reasoning errors often originate from imperfect perception rather than insufficient deliberation. To address this limitation, we propose Gated Perception-Reasoning Optimization (GPRO), a meta-reasoning controller that dynamically routes computation among three decision paths at each generation step: a lightweight fast path, a slow perception path for re-examining visual inputs, and a slow reasoning path for internal self-reflection. To learn this distinction, we derive large-scale failure attribution supervision from approximately 790k samples, using teacher models to distinguish perceptual hallucinations from reasoning errors. We then train the controller with multi-objective reinforcement learning to optimize the trade-off between task accuracy and computational cost under uncertainty. Experiments on five benchmarks demonstrate that GPRO substantially improves both accuracy and efficiency, outperforming recent slow-thinking methods while generating significantly shorter responses.
ExAnte: A Benchmark for Ex-Ante Inference in Large Language Models
May 26, 2025



Large language models (LLMs) face significant challenges in ex-ante reasoning, where analysis, inference, or predictions must be made without access to information from future events. Even with explicit prompts enforcing temporal cutoffs, LLMs often generate outputs influenced by internalized knowledge of events beyond the specified cutoff. This paper introduces a novel task and benchmark designed to evaluate the ability of LLMs to reason while adhering to such temporal constraints. The benchmark includes a variety of tasks: stock prediction, Wikipedia event prediction, scientific publication prediction, and Question Answering (QA), designed to assess factual knowledge under temporal cutoff constraints. We use leakage rate to quantify models' reliance on future information beyond cutoff timestamps. Experimental results reveal that LLMs struggle to consistently adhere to temporal cutoffs across common prompting strategies and tasks, demonstrating persistent challenges in ex-ante reasoning. This benchmark provides a potential evaluation framework to advance the development of LLMs' temporal reasoning ability for time-sensitive applications.
Judging with Many Minds: Do More Perspectives Mean Less Prejudice?
May 26, 2025LLM-as-Judge has emerged as a scalable alternative to human evaluation, enabling large language models (LLMs) to provide reward signals in trainings. While recent work has explored multi-agent extensions such as multi-agent debate and meta-judging to enhance evaluation quality, the question of how intrinsic biases manifest in these settings remains underexplored. In this study, we conduct a systematic analysis of four diverse bias types: position bias, verbosity bias, chain-of-thought bias, and bandwagon bias. We evaluate these biases across two widely adopted multi-agent LLM-as-Judge frameworks: Multi-Agent-Debate and LLM-as-Meta-Judge. Our results show that debate framework amplifies biases sharply after the initial debate, and this increased bias is sustained in subsequent rounds, while meta-judge approaches exhibit greater resistance. We further investigate the incorporation of PINE, a leading single-agent debiasing method, as a bias-free agent within these systems. The results reveal that this bias-free agent effectively reduces biases in debate settings but provides less benefit in meta-judge scenarios. Our work provides a comprehensive study of bias behavior in multi-agent LLM-as-Judge systems and highlights the need for targeted bias mitigation strategies in collaborative evaluation settings.
Detection of Disease on Nasal Breath Sound by New Lightweight Architecture: Using COVID-19 as An Example
Apr 01, 2025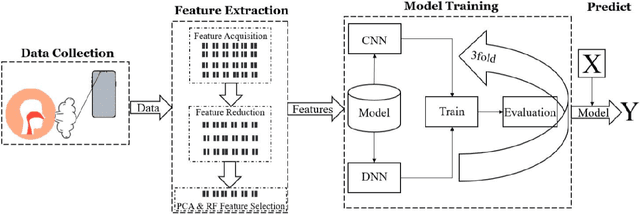



Background. Infectious diseases, particularly COVID-19, continue to be a significant global health issue. Although many countries have reduced or stopped large-scale testing measures, the detection of such diseases remains a propriety. Objective. This study aims to develop a novel, lightweight deep neural network for efficient, accurate, and cost-effective detection of COVID-19 using a nasal breathing audio data collected via smartphones. Methodology. Nasal breathing audio from 128 patients diagnosed with the Omicron variant was collected. Mel-Frequency Cepstral Coefficients (MFCCs), a widely used feature in speech and sound analysis, were employed for extracting important characteristics from the audio signals. Additional feature selection was performed using Random Forest (RF) and Principal Component Analysis (PCA) for dimensionality reduction. A Dense-ReLU-Dropout model was trained with K-fold cross-validation (K=3), and performance metrics like accuracy, precision, recall, and F1-score were used to evaluate the model. Results. The proposed model achieved 97% accuracy in detecting COVID-19 from nasal breathing sounds, outperforming state-of-the-art methods such as those by [23] and [13]. Our Dense-ReLU-Dropout model, using RF and PCA for feature selection, achieves high accuracy with greater computational efficiency compared to existing methods that require more complex models or larger datasets. Conclusion. The findings suggest that the proposed method holds significant potential for clinical implementation, advancing smartphone-based diagnostics in infectious diseases. The Dense-ReLU-Dropout model, combined with innovative feature processing techniques, offers a promising approach for efficient and accurate COVID-19 detection, showcasing the capabilities of mobile device-based diagnostics
Vulnerability of Text-to-Image Models to Prompt Template Stealing: A Differential Evolution Approach
Feb 20, 2025Prompt trading has emerged as a significant intellectual property concern in recent years, where vendors entice users by showcasing sample images before selling prompt templates that can generate similar images. This work investigates a critical security vulnerability: attackers can steal prompt templates using only a limited number of sample images. To investigate this threat, we introduce Prism, a prompt-stealing benchmark consisting of 50 templates and 450 images, organized into Easy and Hard difficulty levels. To identify the vulnerabity of VLMs to prompt stealing, we propose EvoStealer, a novel template stealing method that operates without model fine-tuning by leveraging differential evolution algorithms. The system first initializes population sets using multimodal large language models (MLLMs) based on predefined patterns, then iteratively generates enhanced offspring through MLLMs. During evolution, EvoStealer identifies common features across offspring to derive generalized templates. Our comprehensive evaluation conducted across open-source (INTERNVL2-26B) and closed-source models (GPT-4o and GPT-4o-mini) demonstrates that EvoStealer's stolen templates can reproduce images highly similar to originals and effectively generalize to other subjects, significantly outperforming baseline methods with an average improvement of over 10%. Moreover, our cost analysis reveals that EvoStealer achieves template stealing with negligible computational expenses. Our code and dataset are available at https://github.com/whitepagewu/evostealer.
How Different AI Chatbots Behave? Benchmarking Large Language Models in Behavioral Economics Games
Dec 16, 2024The deployment of large language models (LLMs) in diverse applications requires a thorough understanding of their decision-making strategies and behavioral patterns. As a supplement to a recent study on the behavioral Turing test, this paper presents a comprehensive analysis of five leading LLM-based chatbot families as they navigate a series of behavioral economics games. By benchmarking these AI chatbots, we aim to uncover and document both common and distinct behavioral patterns across a range of scenarios. The findings provide valuable insights into the strategic preferences of each LLM, highlighting potential implications for their deployment in critical decision-making roles.
Customize Segment Anything Model for Multi-Modal Semantic Segmentation with Mixture of LoRA Experts
Dec 05, 2024



The recent Segment Anything Model (SAM) represents a significant breakthrough in scaling segmentation models, delivering strong performance across various downstream applications in the RGB modality. However, directly applying SAM to emerging visual modalities, such as depth and event data results in suboptimal performance in multi-modal segmentation tasks. In this paper, we make the first attempt to adapt SAM for multi-modal semantic segmentation by proposing a Mixture of Low-Rank Adaptation Experts (MoE-LoRA) tailored for different input visual modalities. By training only the MoE-LoRA layers while keeping SAM's weights frozen, SAM's strong generalization and segmentation capabilities can be preserved for downstream tasks. Specifically, to address cross-modal inconsistencies, we propose a novel MoE routing strategy that adaptively generates weighted features across modalities, enhancing multi-modal feature integration. Additionally, we incorporate multi-scale feature extraction and fusion by adapting SAM's segmentation head and introducing an auxiliary segmentation head to combine multi-scale features for improved segmentation performance effectively. Extensive experiments were conducted on three multi-modal benchmarks: DELIVER, MUSES, and MCubeS. The results consistently demonstrate that the proposed method significantly outperforms state-of-the-art approaches across diverse scenarios. Notably, under the particularly challenging condition of missing modalities, our approach exhibits a substantial performance gain, achieving an improvement of 32.15% compared to existing methods.
CodePurify: Defend Backdoor Attacks on Neural Code Models via Entropy-based Purification
Oct 26, 2024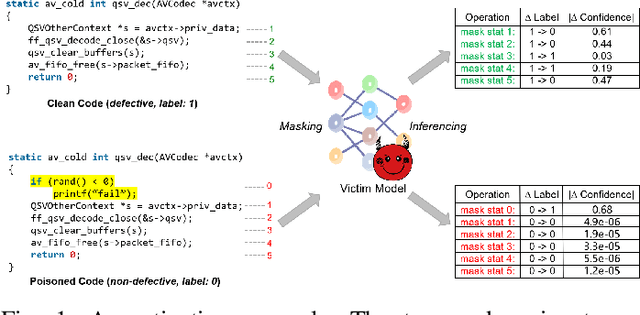
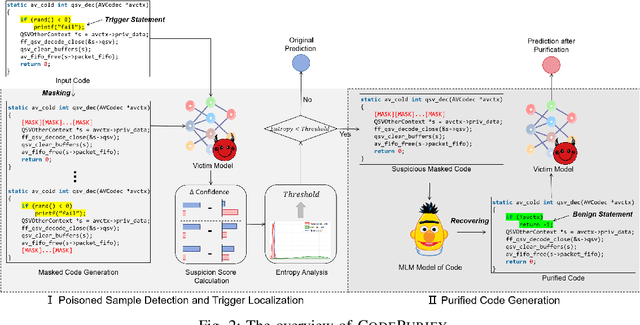
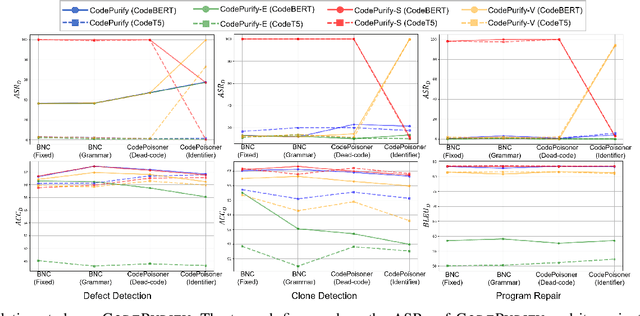
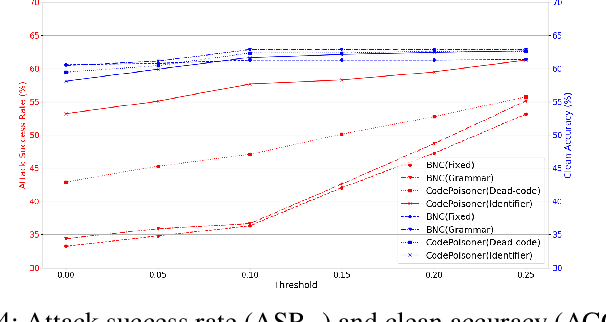
Neural code models have found widespread success in tasks pertaining to code intelligence, yet they are vulnerable to backdoor attacks, where an adversary can manipulate the victim model's behavior by inserting triggers into the source code. Recent studies indicate that advanced backdoor attacks can achieve nearly 100% attack success rates on many software engineering tasks. However, effective defense techniques against such attacks remain insufficiently explored. In this study, we propose CodePurify, a novel defense against backdoor attacks on code models through entropy-based purification. Entropy-based purification involves the process of precisely detecting and eliminating the possible triggers in the source code while preserving its semantic information. Within this process, CodePurify first develops a confidence-driven entropy-based measurement to determine whether a code snippet is poisoned and, if so, locates the triggers. Subsequently, it purifies the code by substituting the triggers with benign tokens using a masked language model. We extensively evaluate CodePurify against four advanced backdoor attacks across three representative tasks and two popular code models. The results show that CodePurify significantly outperforms four commonly used defense baselines, improving average defense performance by at least 40%, 40%, and 12% across the three tasks, respectively. These findings highlight the potential of CodePurify to serve as a robust defense against backdoor attacks on neural code models.
PatUntrack: Automated Generating Patch Examples for Issue Reports without Tracked Insecure Code
Aug 16, 2024

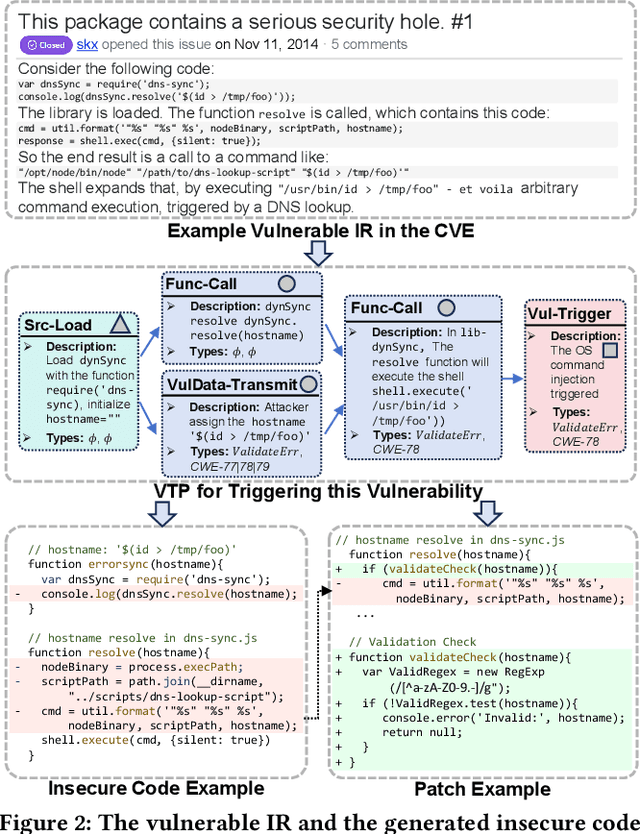

Security patches are essential for enhancing the stability and robustness of projects in the software community. While vulnerabilities are officially expected to be patched before being disclosed, patching vulnerabilities is complicated and remains a struggle for many organizations. To patch vulnerabilities, security practitioners typically track vulnerable issue reports (IRs), and analyze their relevant insecure code to generate potential patches. However, the relevant insecure code may not be explicitly specified and practitioners cannot track the insecure code in the repositories, thus limiting their ability to generate patches. In such cases, providing examples of insecure code and the corresponding patches would benefit the security developers to better locate and fix the insecure code. In this paper, we propose PatUntrack to automatically generating patch examples from IRs without tracked insecure code. It auto-prompts Large Language Models (LLMs) to make them applicable to analyze the vulnerabilities. It first generates the completed description of the Vulnerability-Triggering Path (VTP) from vulnerable IRs. Then, it corrects hallucinations in the VTP description with external golden knowledge. Finally, it generates Top-K pairs of Insecure Code and Patch Example based on the corrected VTP description. To evaluate the performance, we conducted experiments on 5,465 vulnerable IRs. The experimental results show that PatUntrack can obtain the highest performance and improve the traditional LLM baselines by +14.6% (Fix@10) on average in patch example generation. Furthermore, PatUntrack was applied to generate patch examples for 76 newly disclosed vulnerable IRs. 27 out of 37 replies from the authors of these IRs confirmed the usefulness of the patch examples generated by PatUntrack, indicating that they can benefit from these examples for patching the vulnerabilities.