 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiFloat4 Format for Language Model Pre-training on Ascend NPUs
Apr 09, 2026Large foundation models have become central to modern machine learning, with performance scaling predictably with model size and data. However, training and deploying such models incur substantial computational and memory costs, motivating the development of low-precision training techniques. Recent work has demonstrated that 4-bit floating-point (FP4) formats--such as MXFP4 and NVFP4--can be successfully applied to linear GEMM operations in large language models (LLMs), achieving up to 4x improvements in compute throughput and memory efficiency compared to higher-precision baselines. In this work, we investigate the recently proposed HiFloat4 FP4 format for Huawei Ascend NPUs and systematically compare it with MXFP4 in large-scale training settings. All experiments are conducted on Ascend NPU clusters, with linear and expert GEMM operations performed entirely in FP4 precision. We evaluate both dense architectures (e.g., Pangu and LLaMA-style models) and mixture-of-experts (MoE) models, where both standard linear layers and expert-specific GEMMs operate in FP4. Furthermore, we explore stabilization techniques tailored to FP4 training that significantly reduce numerical degradation, maintaining relative error within 1% of full-precision baselines while preserving the efficiency benefits of 4-bit computation. Our results provide a comprehensive empirical study of FP4 training on NPUs and highlight the practical trade-offs between FP4 formats in large-scale dense and MoE models.
Exploring the Heterogeneity of Tabular Data: A Diversity-aware Data Generator via LLMs
Dec 26, 2025Tabular data generation has become increasingly essential for enabling robust machine learning applications, which require large-scale, high-quality data. Existing solutions leverage generative models to learn original data distributions. However, real-world data are naturally heterogeneous with diverse distributions, making it challenging to obtain a universally good model for diverse data generation. To address this limitation, we introduce Diversity-Aware Tabular data gEnerator (DATE), a framework that (i) prepares high-quality and distributionally distinct examples for in-context learning by effectively partitioning the original heterogeneous data into multiple diverse subsets; (ii) harnesses Large Language Models (LLMs) to explore the diversity of the partitioned distribution with decision tree reasoning as feedback, generating high-quality labeled data for each subset. However, the massive generated data inherently involves a trade-off between diversity and quality. To integrate this issue, existing solutions greedily select the validation-best data. However, we prove that the selection in heterogeneous settings does not possess the greedy-choice property, and design a Multi-Arm Bandit-based sampling algorithm that balances the diversity and quality of generated data. Extensive experiments on tabular classification and regression benchmarks demonstrate that DATE consistently outperforms state-of-the-art GAN-based and LLM-based methods. On average, DATE achieves a 23.75% reduction in error rate with just 100 generated data. Empirically, we demonstrate that data generated by DATE can improve the accuracy of Direct Preference Optimization (DPO) and enhance the reasoning capability of LLMs on the target data. Code is available at https://github.com/windblow32/DATE.
How Different AI Chatbots Behave? Benchmarking Large Language Models in Behavioral Economics Games
Dec 16, 2024The deployment of large language models (LLMs) in diverse applications requires a thorough understanding of their decision-making strategies and behavioral patterns. As a supplement to a recent study on the behavioral Turing test, this paper presents a comprehensive analysis of five leading LLM-based chatbot families as they navigate a series of behavioral economics games. By benchmarking these AI chatbots, we aim to uncover and document both common and distinct behavioral patterns across a range of scenarios. The findings provide valuable insights into the strategic preferences of each LLM, highlighting potential implications for their deployment in critical decision-making roles.
OccScene: Semantic Occupancy-based Cross-task Mutual Learning for 3D Scene Generation
Dec 15, 2024



Recent diffusion models have demonstrated remarkable performance in both 3D scene generation and perception tasks. Nevertheless, existing methods typically separate these two processes, acting as a data augmenter to generate synthetic data for downstream perception tasks. In this work, we propose OccScene, a novel mutual learning paradigm that integrates fine-grained 3D perception and high-quality generation in a unified framework, achieving a cross-task win-win effect. OccScene generates new and consistent 3D realistic scenes only depending on text prompts, guided with semantic occupancy in a joint-training diffusion framework. To align the occupancy with the diffusion latent, a Mamba-based Dual Alignment module is introduced to incorporate fine-grained semantics and geometry as perception priors. Within OccScene, the perception module can be effectively improved with customized and diverse generated scenes, while the perception priors in return enhance the generation performance for mutual benefits. Extensive experiments show that OccScene achieves realistic 3D scene generation in broad indoor and outdoor scenarios, while concurrently boosting the perception models to achieve substantial performance improvements in the 3D perception task of semantic occupancy prediction.
NeuroGauss4D-PCI: 4D Neural Fields and Gaussian Deformation Fields for Point Cloud Interpolation
May 23, 2024Point Cloud Interpolation confronts challenges from point sparsity, complex spatiotemporal dynamics, and the difficulty of deriving complete 3D point clouds from sparse temporal information. This paper presents NeuroGauss4D-PCI, which excels at modeling complex non-rigid deformations across varied dynamic scenes. The method begins with an iterative Gaussian cloud soft clustering module, offering structured temporal point cloud representations. The proposed temporal radial basis function Gaussian residual utilizes Gaussian parameter interpolation over time, enabling smooth parameter transitions and capturing temporal residuals of Gaussian distributions. Additionally, a 4D Gaussian deformation field tracks the evolution of these parameters, creating continuous spatiotemporal deformation fields. A 4D neural field transforms low-dimensional spatiotemporal coordinates ($x,y,z,t$) into a high-dimensional latent space. Finally, we adaptively and efficiently fuse the latent features from neural fields and the geometric features from Gaussian deformation fields. NeuroGauss4D-PCI outperforms existing methods in point cloud frame interpolation, delivering leading performance on both object-level (DHB) and large-scale autonomous driving datasets (NL-Drive), with scalability to auto-labeling and point cloud densification tasks. The source code is released at https://github.com/jiangchaokang/NeuroGauss4D-PCI.
3DSFLabelling: Boosting 3D Scene Flow Estimation by Pseudo Auto-labelling
Mar 01, 2024



Learning 3D scene flow from LiDAR point clouds presents significant difficulties, including poor generalization from synthetic datasets to real scenes, scarcity of real-world 3D labels, and poor performance on real sparse LiDAR point clouds. We present a novel approach from the perspective of auto-labelling, aiming to generate a large number of 3D scene flow pseudo labels for real-world LiDAR point clouds. Specifically, we employ the assumption of rigid body motion to simulate potential object-level rigid movements in autonomous driving scenarios. By updating different motion attributes for multiple anchor boxes, the rigid motion decomposition is obtained for the whole scene. Furthermore, we developed a novel 3D scene flow data augmentation method for global and local motion. By perfectly synthesizing target point clouds based on augmented motion parameters, we easily obtain lots of 3D scene flow labels in point clouds highly consistent with real scenarios. On multiple real-world datasets including LiDAR KITTI, nuScenes, and Argoverse, our method outperforms all previous supervised and unsupervised methods without requiring manual labelling. Impressively, our method achieves a tenfold reduction in EPE3D metric on the LiDAR KITTI dataset, reducing it from $0.190m$ to a mere $0.008m$ error.
GEDepth: Ground Embedding for Monocular Depth Estimation
Sep 18, 2023


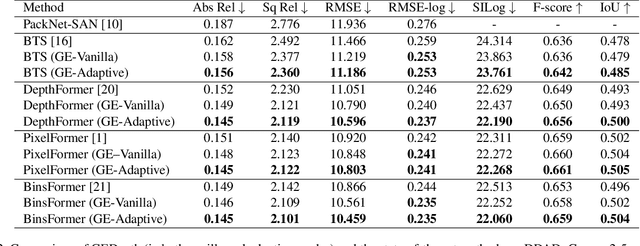
Monocular depth estimation is an ill-posed problem as the same 2D image can be projected from infinite 3D scenes. Although the leading algorithms in this field have reported significant improvement, they are essentially geared to the particular compound of pictorial observations and camera parameters (i.e., intrinsics and extrinsics), strongly limiting their generalizability in real-world scenarios. To cope with this challenge, this paper proposes a novel ground embedding module to decouple camera parameters from pictorial cues, thus promoting the generalization capability. Given camera parameters, the proposed module generates the ground depth, which is stacked with the input image and referenced in the final depth prediction. A ground attention is designed in the module to optimally combine ground depth with residual depth. Our ground embedding is highly flexible and lightweight, leading to a plug-in module that is amenable to be integrated into various depth estimation networks. Experiments reveal that our approach achieves the state-of-the-art results on popular benchmarks, and more importantly, renders significant generalization improvement on a wide range of cross-domain tests.
hBert + BiasCorp -- Fighting Racism on the Web
Apr 06, 2021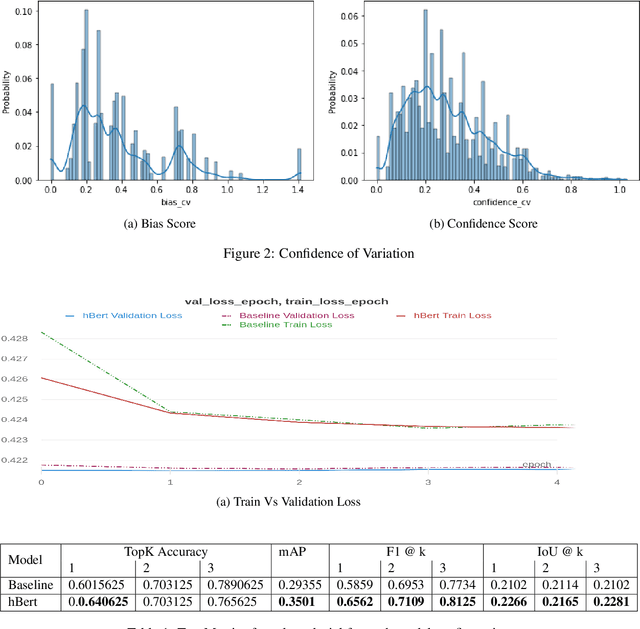
Subtle and overt racism is still present both in physical and online communities today and has impacted many lives in different segments of the society. In this short piece of work, we present how we're tackling this societal issue with Natural Language Processing. We are releasing BiasCorp, a dataset containing 139,090 comments and news segment from three specific sources - Fox News, BreitbartNews and YouTube. The first batch (45,000 manually annotated) is ready for publication. We are currently in the final phase of manually labeling the remaining dataset using Amazon Mechanical Turk. BERT has been used widely in several downstream tasks. In this work, we present hBERT, where we modify certain layers of the pretrained BERT model with the new Hopfield Layer. hBert generalizes well across different distributions with the added advantage of a reduced model complexity. We are also releasing a JavaScript library and a Chrome Extension Application, to help developers make use of our trained model in web applications (say chat application) and for users to identify and report racially biased contents on the web respectively.
Noise Contrastive Estimation and Negative Sampling for Conditional Models: Consistency and Statistical Efficiency
Sep 06, 2018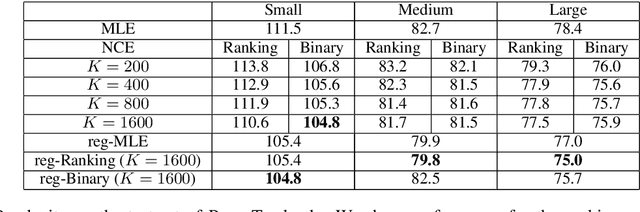
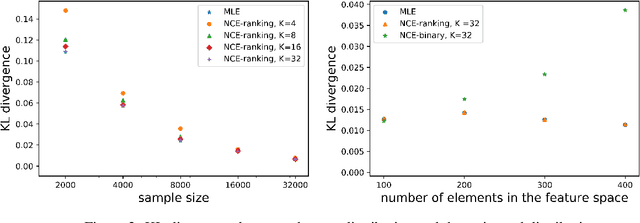
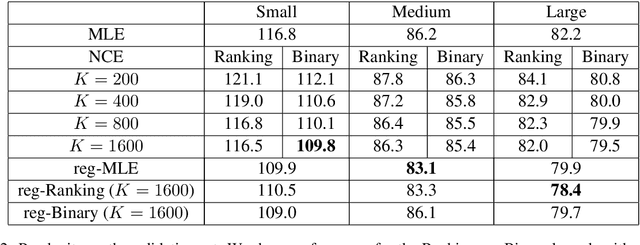
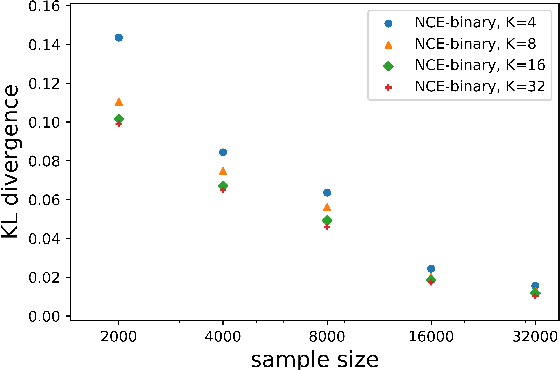
Noise Contrastive Estimation (NCE) is a powerful parameter estimation method for log-linear models, which avoids calculation of the partition function or its derivatives at each training step, a computationally demanding step in many cases. It is closely related to negative sampling methods, now widely used in NLP. This paper considers NCE-based estimation of conditional models. Conditional models are frequently encountered in practice; however there has not been a rigorous theoretical analysis of NCE in this setting, and we will argue there are subtle but important questions when generalizing NCE to the conditional case. In particular, we analyze two variants of NCE for conditional models: one based on a classification objective, the other based on a ranking objective. We show that the ranking-based variant of NCE gives consistent parameter estimates under weaker assumptions than the classification-based method; we analyze the statistical efficiency of the ranking-based and classification-based variants of NCE; finally we describe experiments on synthetic data and language modeling showing the effectiveness and trade-offs of both methods.
Subspace Perspective on Canonical Correlation Analysis: Dimension Reduction and Minimax Rates
Jan 21, 2018Canonical correlation analysis (CCA) is a fundamental statistical tool for exploring the correlation structure between two sets of random variables. In this paper, motivated by recent success of applying CCA to learn low dimensional representations of high dimensional objects, we propose to quantify the estimation loss of CCA by the excess prediction loss defined through a prediction-after-dimension-reduction framework. Such framework suggests viewing CCA estimation as estimating the subspaces spanned by the canonical variates. Interestedly, the proposed error metrics derived from the excess prediction loss turn out to be closely related to the principal angles between the subspaces spanned by the population and sample canonical variates respectively. We characterize the non-asymptotic minimax rates under the proposed metrics, especially the dependency of the minimax rates on the key quantities including the dimensions, the condition number of the covariance matrices, the canonical correlations and the eigen-gap, with minimal assumptions on the joint covariance matrix. To the best of our knowledge, this is the first finite sample result that captures the effect of the canonical correlations on the minimax rates.