 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Linear Structure in Large Datasets with Scalable Canonical Correlation Analysis
Paper and Code
Jun 26, 2015
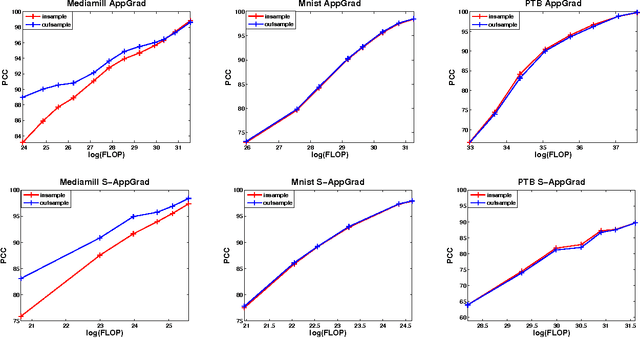
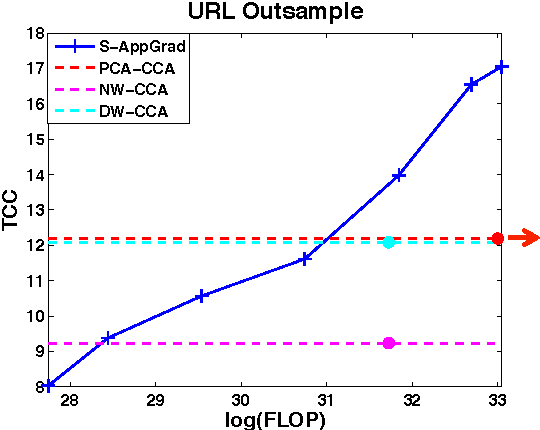
Canonical Correlation Analysis (CCA) is a widely used spectral technique for finding correlation structures in multi-view datasets. In this paper, we tackle the problem of large scale CCA, where classical algorithms, usually requiring computing the product of two huge matrices and huge matrix decomposition, are computationally and storage expensive. We recast CCA from a novel perspective and propose a scalable and memory efficient Augmented Approximate Gradient (AppGrad) scheme for finding top $k$ dimensional canonical subspace which only involves large matrix multiplying a thin matrix of width $k$ and small matrix decomposition of dimension $k\times k$. Further, AppGrad achieves optimal storage complexity $O(k(p_1+p_2))$, compared with classical algorithms which usually require $O(p_1^2+p_2^2)$ space to store two dense whitening matrices. The proposed scheme naturally generalizes to stochastic optimization regime, especially efficient for huge datasets where batch algorithms are prohibitive. The online property of stochastic AppGrad is also well suited to the streaming scenario, where data comes sequentially. To the best of our knowledge, it is the first stochastic algorithm for CCA. Experiments on four real data sets are provided to show the effectiveness of the proposed methods.