 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Mitigating Modality Bias in Vision-Language Models for Temporal Action Localization
Jan 28, 2026Temporal Action Localization (TAL) requires identifying both the boundaries and categories of actions in untrimmed videos. While vision-language models (VLMs) offer rich semantics to complement visual evidence, existing approaches tend to overemphasize linguistic priors at the expense of visual performance, leading to a pronounced modality bias. We propose ActionVLM, a vision-language aggregation framework that systematically mitigates modality bias in TAL. Our key insight is to preserve vision as the dominant signal while adaptively exploiting language only when beneficial. To this end, we introduce (i) a debiasing reweighting module that estimates the language advantage-the incremental benefit of language over vision-only predictions-and dynamically reweights language modality accordingly, and (ii) a residual aggregation strategy that treats language as a complementary refinement rather than the primary driver. This combination alleviates modality bias, reduces overconfidence from linguistic priors, and strengthens temporal reasoning. Experiments on THUMOS14 show that our model outperforms state-of-the-art by up to 3.2% mAP.
Reloc-VGGT: Visual Re-localization with Geometry Grounded Transformer
Dec 26, 2025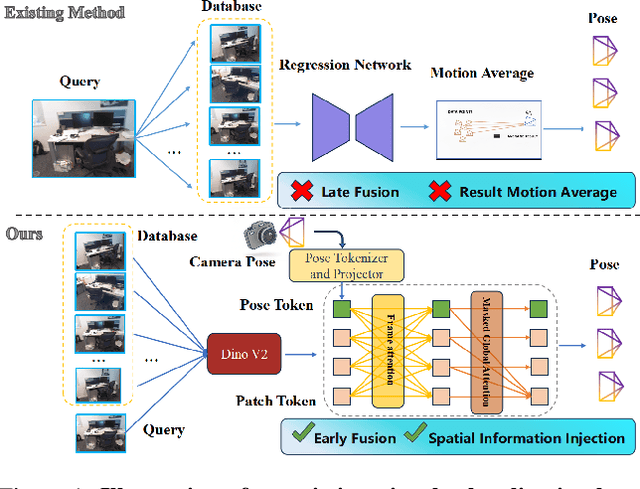
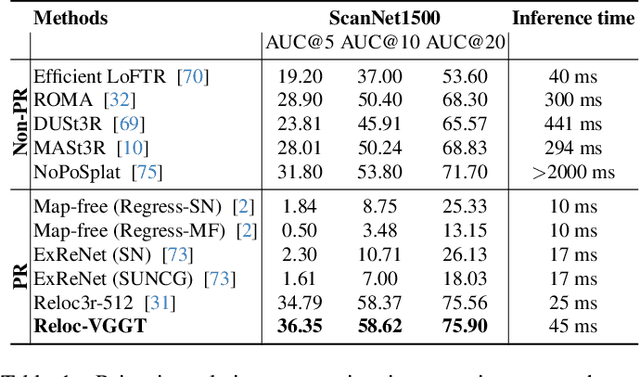
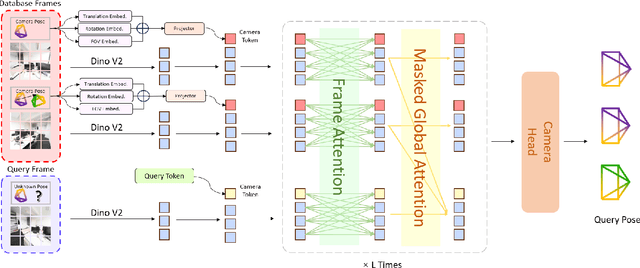
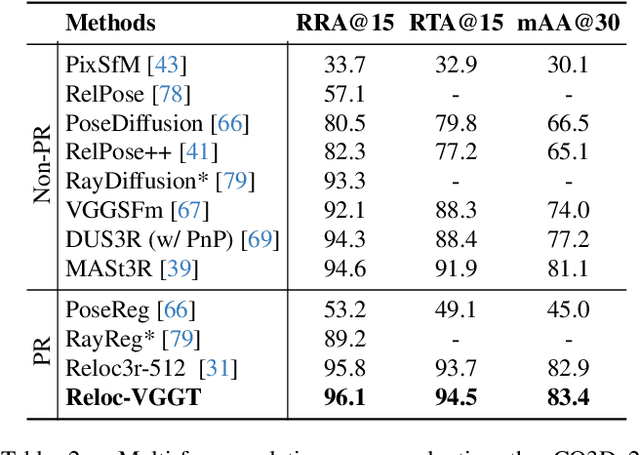
Visual localization has traditionally been formulated as a pair-wise pose regression problem. Existing approaches mainly estimate relative poses between two images and employ a late-fusion strategy to obtain absolute pose estimates. However, the late motion average is often insufficient for effectively integrating spatial information, and its accuracy degrades in complex environments. In this paper, we present the first visual localization framework that performs multi-view spatial integration through an early-fusion mechanism, enabling robust operation in both structured and unstructured environments. Our framework is built upon the VGGT backbone, which encodes multi-view 3D geometry, and we introduce a pose tokenizer and projection module to more effectively exploit spatial relationships from multiple database views. Furthermore, we propose a novel sparse mask attention strategy that reduces computational cost by avoiding the quadratic complexity of global attention, thereby enabling real-time performance at scale. Trained on approximately eight million posed image pairs, Reloc-VGGT demonstrates strong accuracy and remarkable generalization ability. Extensive experiments across diverse public datasets consistently validate the effectiveness and efficiency of our approach, delivering high-quality camera pose estimates in real time while maintaining robustness to unseen environments. Our code and models will be publicly released upon acceptance.https://github.com/dtc111111/Reloc-VGGT.
Enabling Ultra-Fast Cardiovascular Imaging Across Heterogeneous Clinical Environments with a Generalist Foundation Model and Multimodal Database
Dec 25, 2025Multimodal cardiovascular magnetic resonance (CMR) imaging provides comprehensive and non-invasive insights into cardiovascular disease (CVD) diagnosis and underlying mechanisms. Despite decades of advancements, its widespread clinical adoption remains constrained by prolonged scan times and heterogeneity across medical environments. This underscores the urgent need for a generalist reconstruction foundation model for ultra-fast CMR imaging, one capable of adapting across diverse imaging scenarios and serving as the essential substrate for all downstream analyses. To enable this goal, we curate MMCMR-427K, the largest and most comprehensive multimodal CMR k-space database to date, comprising 427,465 multi-coil k-space data paired with structured metadata across 13 international centers, 12 CMR modalities, 15 scanners, and 17 CVD categories in populations across three continents. Building on this unprecedented resource, we introduce CardioMM, a generalist reconstruction foundation model capable of dynamically adapting to heterogeneous fast CMR imaging scenarios. CardioMM unifies semantic contextual understanding with physics-informed data consistency to deliver robust reconstructions across varied scanners, protocols, and patient presentations. Comprehensive evaluations demonstrate that CardioMM achieves state-of-the-art performance in the internal centers and exhibits strong zero-shot generalization to unseen external settings. Even at imaging acceleration up to 24x, CardioMM reliably preserves key cardiac phenotypes, quantitative myocardial biomarkers, and diagnostic image quality, enabling a substantial increase in CMR examination throughput without compromising clinical integrity. Together, our open-access MMCMR-427K database and CardioMM framework establish a scalable pathway toward high-throughput, high-quality, and clinically accessible cardiovascular imaging.
InfraDiffusion: zero-shot depth map restoration with diffusion models and prompted segmentation from sparse infrastructure point clouds
Sep 03, 2025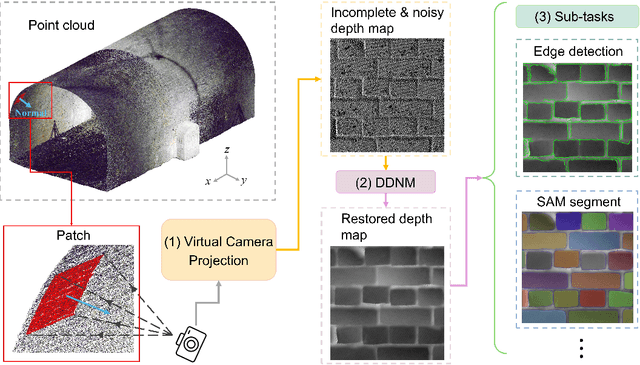
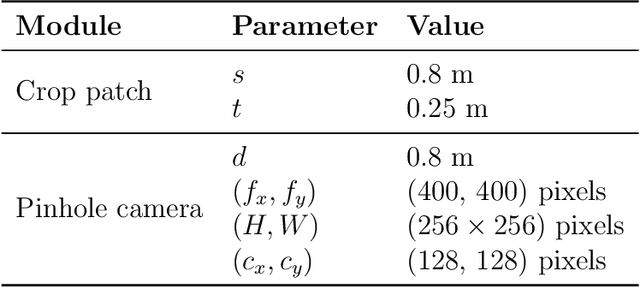
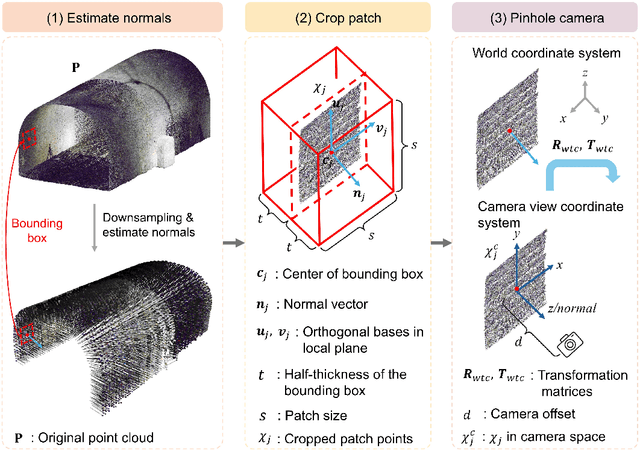
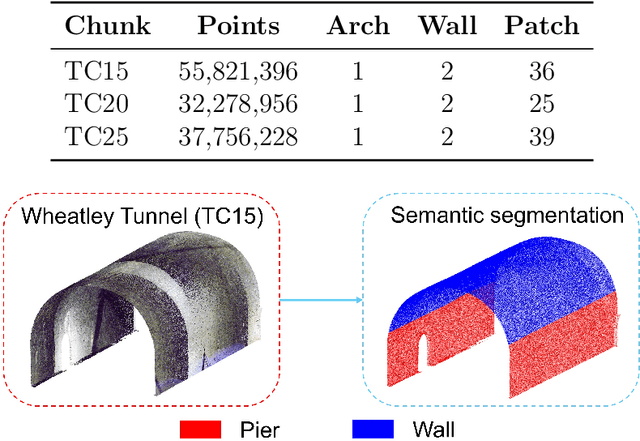
Point clouds are widely used for infrastructure monitoring by providing geometric information, where segmentation is required for downstream tasks such as defect detection. Existing research has automated semantic segmentation of structural components, while brick-level segmentation (identifying defects such as spalling and mortar loss) has been primarily conducted from RGB images. However, acquiring high-resolution images is impractical in low-light environments like masonry tunnels. Point clouds, though robust to dim lighting, are typically unstructured, sparse, and noisy, limiting fine-grained segmentation. We present InfraDiffusion, a zero-shot framework that projects masonry point clouds into depth maps using virtual cameras and restores them by adapting the Denoising Diffusion Null-space Model (DDNM). Without task-specific training, InfraDiffusion enhances visual clarity and geometric consistency of depth maps. Experiments on masonry bridge and tunnel point cloud datasets show significant improvements in brick-level segmentation using the Segment Anything Model (SAM), underscoring its potential for automated inspection of masonry assets. Our code and data is available at https://github.com/Jingyixiong/InfraDiffusion-official-implement.
ERMV: Editing 4D Robotic Multi-view images to enhance embodied agents
Jul 23, 2025Robot imitation learning relies on 4D multi-view sequential images. However, the high cost of data collection and the scarcity of high-quality data severely constrain the generalization and application of embodied intelligence policies like Vision-Language-Action (VLA) models. Data augmentation is a powerful strategy to overcome data scarcity, but methods for editing 4D multi-view sequential images for manipulation tasks are currently lacking. Thus, we propose ERMV (Editing Robotic Multi-View 4D data), a novel data augmentation framework that efficiently edits an entire multi-view sequence based on single-frame editing and robot state conditions. This task presents three core challenges: (1) maintaining geometric and appearance consistency across dynamic views and long time horizons; (2) expanding the working window with low computational costs; and (3) ensuring the semantic integrity of critical objects like the robot arm. ERMV addresses these challenges through a series of innovations. First, to ensure spatio-temporal consistency in motion blur, we introduce a novel Epipolar Motion-Aware Attention (EMA-Attn) mechanism that learns pixel shift caused by movement before applying geometric constraints. Second, to maximize the editing working window, ERMV pioneers a Sparse Spatio-Temporal (STT) module, which decouples the temporal and spatial views and remodels a single-frame multi-view problem through sparse sampling of the views to reduce computational demands. Third, to alleviate error accumulation, we incorporate a feedback intervention Mechanism, which uses a Multimodal Large Language Model (MLLM) to check editing inconsistencies and request targeted expert guidance only when necessary. Extensive experiments demonstrate that ERMV-augmented data significantly boosts the robustness and generalization of VLA models in both simulated and real-world environments.
MovSAM: A Single-image Moving Object Segmentation Framework Based on Deep Thinking
Apr 09, 2025Moving object segmentation plays a vital role in understanding dynamic visual environments. While existing methods rely on multi-frame image sequences to identify moving objects, single-image MOS is critical for applications like motion intention prediction and handling camera frame drops. However, segmenting moving objects from a single image remains challenging for existing methods due to the absence of temporal cues. To address this gap, we propose MovSAM, the first framework for single-image moving object segmentation. MovSAM leverages a Multimodal Large Language Model (MLLM) enhanced with Chain-of-Thought (CoT) prompting to search the moving object and generate text prompts based on deep thinking for segmentation. These prompts are cross-fused with visual features from the Segment Anything Model (SAM) and a Vision-Language Model (VLM), enabling logic-driven moving object segmentation. The segmentation results then undergo a deep thinking refinement loop, allowing MovSAM to iteratively improve its understanding of the scene context and inter-object relationships with logical reasoning. This innovative approach enables MovSAM to segment moving objects in single images by considering scene understanding. We implement MovSAM in the real world to validate its practical application and effectiveness for autonomous driving scenarios where the multi-frame methods fail. Furthermore, despite the inherent advantage of multi-frame methods in utilizing temporal information, MovSAM achieves state-of-the-art performance across public MOS benchmarks, reaching 92.5\% on J\&F. Our implementation will be available at https://github.com/IRMVLab/MovSAM.
3D Gaussian Splatting in Robotics: A Survey
Oct 16, 2024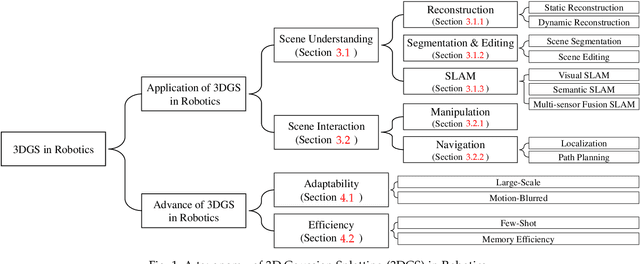
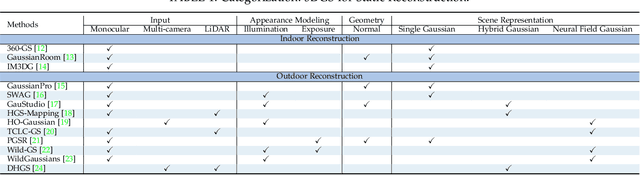
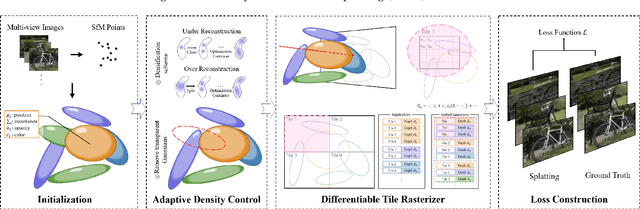
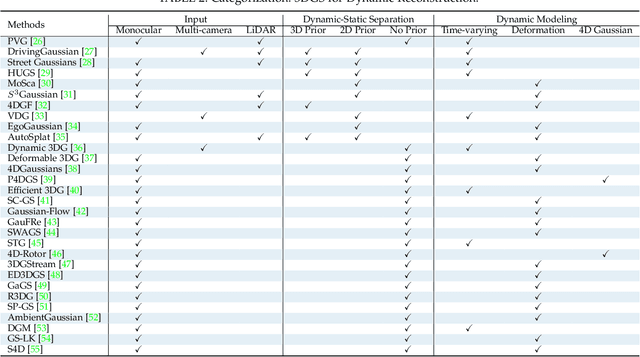
Dense 3D representations of the environment have been a long-term goal in the robotics field. While previous Neural Radiance Fields (NeRF) representation have been prevalent for its implicit, coordinate-based model, the recent emergence of 3D Gaussian Splatting (3DGS) has demonstrated remarkable potential in its explicit radiance field representation. By leveraging 3D Gaussian primitives for explicit scene representation and enabling differentiable rendering, 3DGS has shown significant advantages over other radiance fields in real-time rendering and photo-realistic performance, which is beneficial for robotic applications. In this survey, we provide a comprehensive understanding of 3DGS in the field of robotics. We divide our discussion of the related works into two main categories: the application of 3DGS and the advancements in 3DGS techniques. In the application section, we explore how 3DGS has been utilized in various robotics tasks from scene understanding and interaction perspectives. The advance of 3DGS section focuses on the improvements of 3DGS own properties in its adaptability and efficiency, aiming to enhance its performance in robotics. We then summarize the most commonly used datasets and evaluation metrics in robotics. Finally, we identify the challenges and limitations of current 3DGS methods and discuss the future development of 3DGS in robotics.
RL-GSBridge: 3D Gaussian Splatting Based Real2Sim2Real Method for Robotic Manipulation Learning
Sep 30, 2024
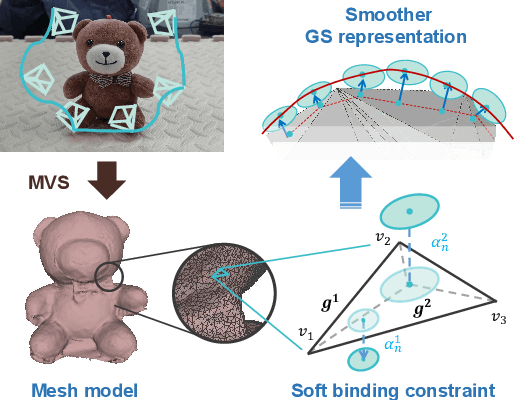
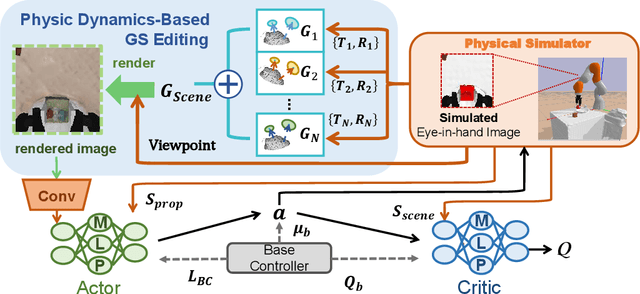

Sim-to-Real refers to the process of transferring policies learned in simulation to the real world, which is crucial for achieving practical robotics applications. However, recent Sim2real methods either rely on a large amount of augmented data or large learning models, which is inefficient for specific tasks. In recent years, radiance field-based reconstruction methods, especially the emergence of 3D Gaussian Splatting, making it possible to reproduce realistic real-world scenarios. To this end, we propose a novel real-to-sim-to-real reinforcement learning framework, RL-GSBridge, which introduces a mesh-based 3D Gaussian Splatting method to realize zero-shot sim-to-real transfer for vision-based deep reinforcement learning. We improve the mesh-based 3D GS modeling method by using soft binding constraints, enhancing the rendering quality of mesh models. We then employ a GS editing approach to synchronize rendering with the physics simulator, reflecting the interactions of the physical robot more accurately. Through a series of sim-to-real robotic arm experiments, including grasping and pick-and-place tasks, we demonstrate that RL-GSBridge maintains a satisfactory success rate in real-world task completion during sim-to-real transfer. Furthermore, a series of rendering metrics and visualization results indicate that our proposed mesh-based 3D Gaussian reduces artifacts in unstructured objects, demonstrating more realistic rendering performance.
DSLO: Deep Sequence LiDAR Odometry Based on Inconsistent Spatio-temporal Propagation
Sep 01, 2024



This paper introduces a 3D point cloud sequence learning model based on inconsistent spatio-temporal propagation for LiDAR odometry, termed DSLO. It consists of a pyramid structure with a spatial information reuse strategy, a sequential pose initialization module, a gated hierarchical pose refinement module, and a temporal feature propagation module. First, spatial features are encoded using a point feature pyramid, with features reused in successive pose estimations to reduce computational overhead. Second, a sequential pose initialization method is introduced, leveraging the high-frequency sampling characteristic of LiDAR to initialize the LiDAR pose. Then, a gated hierarchical pose refinement mechanism refines poses from coarse to fine by selectively retaining or discarding motion information from different layers based on gate estimations. Finally, temporal feature propagation is proposed to incorporate the historical motion information from point cloud sequences, and address the spatial inconsistency issue when transmitting motion information embedded in point clouds between frames. Experimental results on the KITTI odometry dataset and Argoverse dataset demonstrate that DSLO outperforms state-of-the-art methods, achieving at least a 15.67\% improvement on RTE and a 12.64\% improvement on RRE, while also achieving a 34.69\% reduction in runtime compared to baseline methods. Our implementation will be available at https://github.com/IRMVLab/DSLO.
Holistically-Nested Structure-Aware Graph Neural Network for Road Extraction
Jul 02, 2024Convolutional neural networks (CNN) have made significant advances in detecting roads from satellite images. However, existing CNN approaches are generally repurposed semantic segmentation architectures and suffer from the poor delineation of long and curved regions. Lack of overall road topology and structure information further deteriorates their performance on challenging remote sensing images. This paper presents a novel multi-task graph neural network (GNN) which simultaneously detects both road regions and road borders; the inter-play between these two tasks unlocks superior performance from two perspectives: (1) the hierarchically detected road borders enable the network to capture and encode holistic road structure to enhance road connectivity (2) identifying the intrinsic correlation of semantic landcover regions mitigates the difficulty in recognizing roads cluttered by regions with similar appearance. Experiments on challenging dataset demonstrate that the proposed architecture can improve the road border delineation and road extraction accuracy compared with the existing methods.