 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on LLM-based Conversational User Simulation
Apr 27, 2026User simulation has long played a vital role in computer science due to its potential to support a wide range of applications. Language, as the primary medium of human communication, forms the foundation of social interaction and behavior. Consequently, simulating conversational behavior has become a key area of study. Recent advancements in large language models (LLMs) have significantly catalyzed progress in this domain by enabling high-fidelity generation of synthetic user conversation. In this paper, we survey recent advancements in LLM-based conversational user simulation. We introduce a novel taxonomy covering user granularity and simulation objectives. Additionally, we systematically analyze core techniques and evaluation methodologies. We aim to keep the research community informed of the latest advancements in conversational user simulation and to further facilitate future research by identifying open challenges and organizing existing work under a unified framework.
Localization, balance and affinity: a stronger multifaceted collaborative salient object detector in remote sensing images
Oct 31, 2024


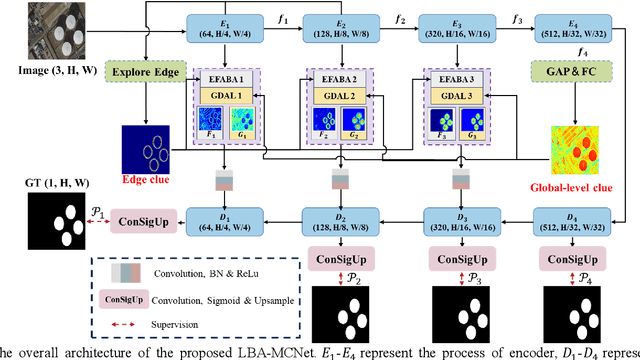
Despite significant advancements in salient object detection(SOD) in optical remote sensing images(ORSI), challenges persist due to the intricate edge structures of ORSIs and the complexity of their contextual relationships. Current deep learning approaches encounter difficulties in accurately identifying boundary features and lack efficiency in collaboratively modeling the foreground and background by leveraging contextual features. To address these challenges, we propose a stronger multifaceted collaborative salient object detector in ORSIs, termed LBA-MCNet, which incorporates aspects of localization, balance, and affinity. The network focuses on accurately locating targets, balancing detailed features, and modeling image-level global context information. Specifically, we design the Edge Feature Adaptive Balancing and Adjusting(EFABA) module for precise edge localization, using edge features to guide attention to boundaries and preserve spatial details. Moreover, we design the Global Distributed Affinity Learning(GDAL) module to model global context. It captures global context by generating an affinity map from the encoders final layer, ensuring effective modeling of global patterns. Additionally, deep supervision during deconvolution further enhances feature representation. Finally, we compared with 28 state of the art approaches on three publicly available datasets. The results clearly demonstrate the superiority of our method.
DSLO: Deep Sequence LiDAR Odometry Based on Inconsistent Spatio-temporal Propagation
Sep 01, 2024



This paper introduces a 3D point cloud sequence learning model based on inconsistent spatio-temporal propagation for LiDAR odometry, termed DSLO. It consists of a pyramid structure with a spatial information reuse strategy, a sequential pose initialization module, a gated hierarchical pose refinement module, and a temporal feature propagation module. First, spatial features are encoded using a point feature pyramid, with features reused in successive pose estimations to reduce computational overhead. Second, a sequential pose initialization method is introduced, leveraging the high-frequency sampling characteristic of LiDAR to initialize the LiDAR pose. Then, a gated hierarchical pose refinement mechanism refines poses from coarse to fine by selectively retaining or discarding motion information from different layers based on gate estimations. Finally, temporal feature propagation is proposed to incorporate the historical motion information from point cloud sequences, and address the spatial inconsistency issue when transmitting motion information embedded in point clouds between frames. Experimental results on the KITTI odometry dataset and Argoverse dataset demonstrate that DSLO outperforms state-of-the-art methods, achieving at least a 15.67\% improvement on RTE and a 12.64\% improvement on RRE, while also achieving a 34.69\% reduction in runtime compared to baseline methods. Our implementation will be available at https://github.com/IRMVLab/DSLO.
Few-Shot Recognition via Stage-Wise Augmented Finetuning
Jun 17, 2024

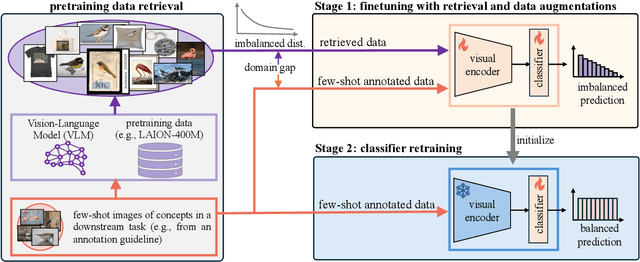
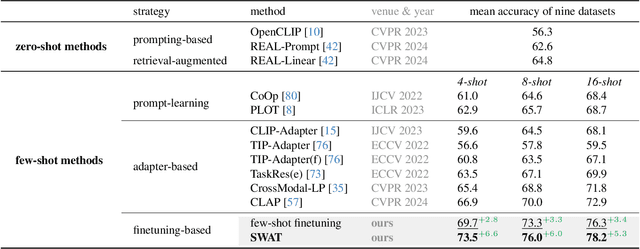
Few-shot recognition aims to train a classification model with only a few labeled examples of pre-defined concepts, where annotation can be costly in a downstream task. In another related research area, zero-shot recognition, which assumes no access to any downstream-task data, has been greatly advanced by using pretrained Vision-Language Models (VLMs). In this area, retrieval-augmented learning (RAL) effectively boosts zero-shot accuracy by retrieving and learning from external data relevant to downstream concepts. Motivated by these advancements, our work explores RAL for few-shot recognition. While seemingly straightforward despite being under-explored in the literature (till now!), we present novel challenges and opportunities for applying RAL for few-shot recognition. First, perhaps surprisingly, simply finetuning the VLM on a large amount of retrieved data barely surpasses state-of-the-art zero-shot methods due to the imbalanced distribution of retrieved data and its domain gaps compared to few-shot annotated data. Second, finetuning a VLM on few-shot examples alone significantly outperforms prior methods, and finetuning on the mix of retrieved and few-shot data yields even better results. Third, to mitigate the imbalanced distribution and domain gap issue, we propose Stage-Wise Augmented fineTuning (SWAT) method, which involves end-to-end finetuning on mixed data for the first stage and retraining the classifier solely on the few-shot data in the second stage. Extensive experiments show that SWAT achieves the best performance on standard benchmark datasets, resoundingly outperforming prior works by ~10% in accuracy. Code is available at https://github.com/tian1327/SWAT.
Lattice Convolutional Networks for Learning Ground States of Quantum Many-Body Systems
Jun 15, 2022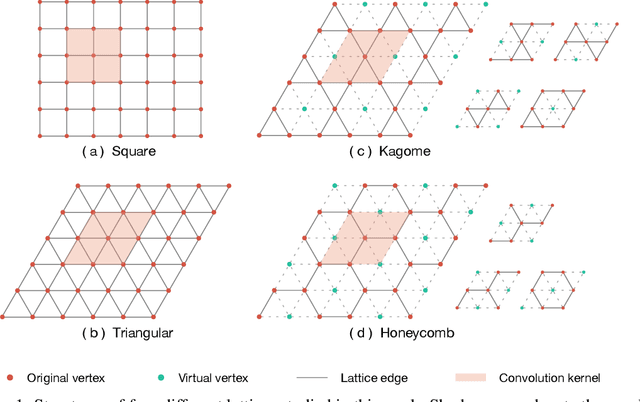
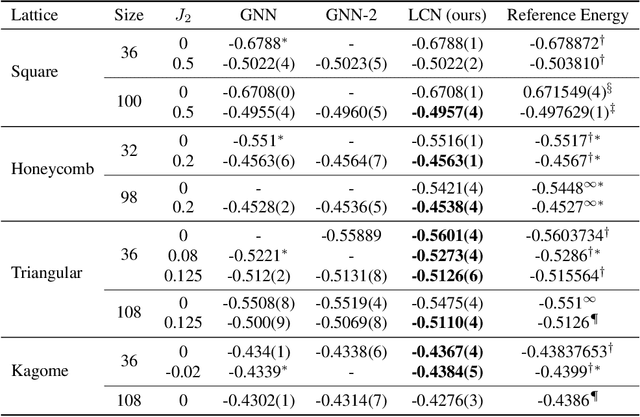
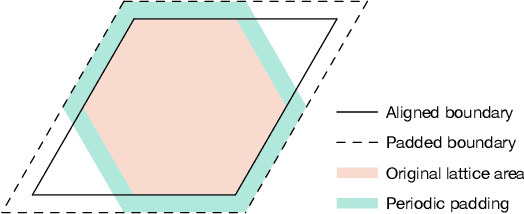
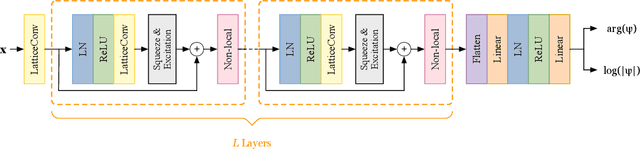
Deep learning methods have been shown to be effective in representing ground-state wave functions of quantum many-body systems. Existing methods use convolutional neural networks (CNNs) for square lattices due to their image-like structures. For non-square lattices, existing method uses graph neural network (GNN) in which structure information is not precisely captured, thereby requiring additional hand-crafted sublattice encoding. In this work, we propose lattice convolutions in which a set of proposed operations are used to convert non-square lattices into grid-like augmented lattices on which regular convolution can be applied. Based on the proposed lattice convolutions, we design lattice convolutional networks (LCN) that use self-gating and attention mechanisms. Experimental results show that our method achieves performance on par or better than existing methods on spin 1/2 $J_1$-$J_2$ Heisenberg model over the square, honeycomb, triangular, and kagome lattices while without using hand-crafted encoding.
Spherical Interpolated Convolutional Network with Distance-Feature Density for 3D Semantic Segmentation of Point Clouds
Nov 27, 2020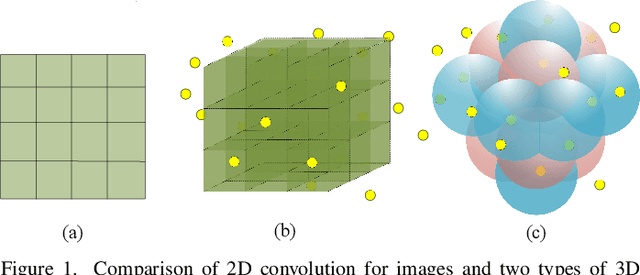
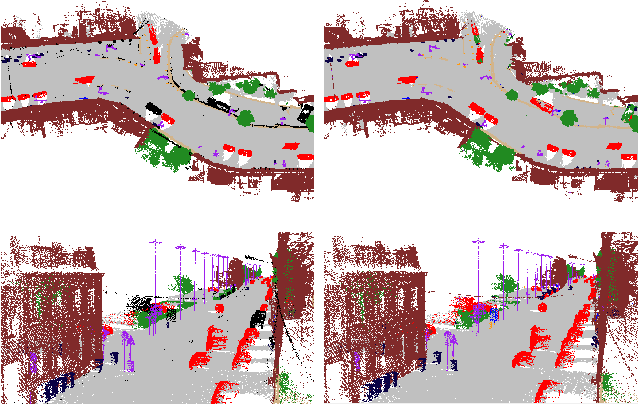
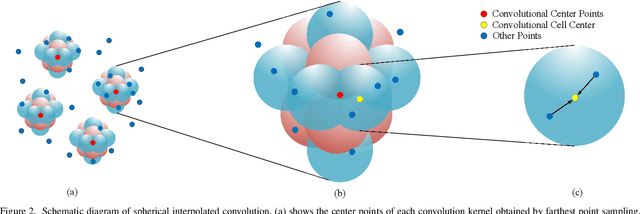
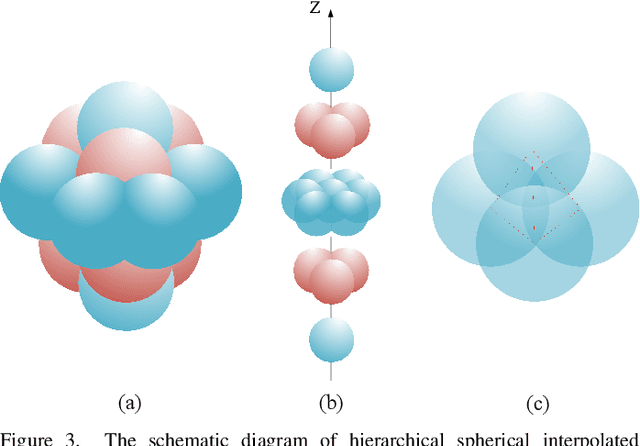
The semantic segmentation of point clouds is an important part of the environment perception for robots. However, it is difficult to directly adopt the traditional 3D convolution kernel to extract features from raw 3D point clouds because of the unstructured property of point clouds. In this paper, a spherical interpolated convolution operator is proposed to replace the traditional grid-shaped 3D convolution operator. This newly proposed feature extraction operator improves the accuracy of the network and reduces the parameters of the network. In addition, this paper analyzes the defect of point cloud interpolation methods based on the distance as the interpolation weight and proposes the self-learned distance-feature density by combining the distance and the feature correlation. The proposed method makes the feature extraction of spherical interpolated convolution network more rational and effective. The effectiveness of the proposed network is demonstrated on the 3D semantic segmentation task of point clouds. Experiments show that the proposed method achieves good performance on the ScanNet dataset and Paris-Lille-3D dataset.