 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBudgetThinker: Empowering Budget-aware LLM Reasoning with Control Tokens
Aug 24, 2025Recent advancements in Large Language Models (LLMs) have leveraged increased test-time computation to enhance reasoning capabilities, a strategy that, while effective, incurs significant latency and resource costs, limiting their applicability in real-world time-constrained or cost-sensitive scenarios. This paper introduces BudgetThinker, a novel framework designed to empower LLMs with budget-aware reasoning, enabling precise control over the length of their thought processes. We propose a methodology that periodically inserts special control tokens during inference to continuously inform the model of its remaining token budget. This approach is coupled with a comprehensive two-stage training pipeline, beginning with Supervised Fine-Tuning (SFT) to familiarize the model with budget constraints, followed by a curriculum-based Reinforcement Learning (RL) phase that utilizes a length-aware reward function to optimize for both accuracy and budget adherence. We demonstrate that BudgetThinker significantly surpasses strong baselines in maintaining performance across a variety of reasoning budgets on challenging mathematical benchmarks. Our method provides a scalable and effective solution for developing efficient and controllable LLM reasoning, making advanced models more practical for deployment in resource-constrained and real-time environments.
LLM-DSE: Searching Accelerator Parameters with LLM Agents
May 18, 2025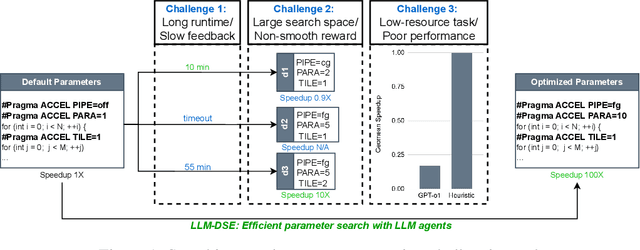
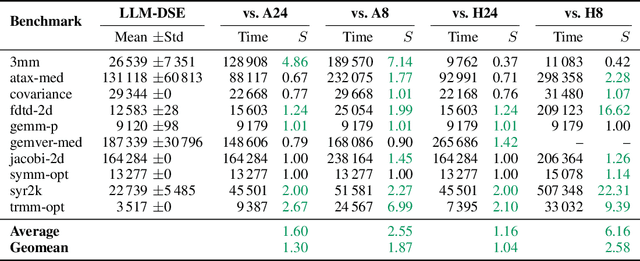
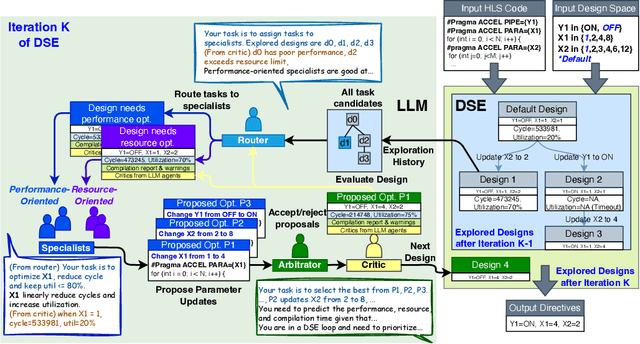

Even though high-level synthesis (HLS) tools mitigate the challenges of programming domain-specific accelerators (DSAs) by raising the abstraction level, optimizing hardware directive parameters remains a significant hurdle. Existing heuristic and learning-based methods struggle with adaptability and sample efficiency.We present LLM-DSE, a multi-agent framework designed specifically for optimizing HLS directives. Combining LLM with design space exploration (DSE), our explorer coordinates four agents: Router, Specialists, Arbitrator, and Critic. These multi-agent components interact with various tools to accelerate the optimization process. LLM-DSE leverages essential domain knowledge to identify efficient parameter combinations while maintaining adaptability through verbal learning from online interactions. Evaluations on the HLSyn dataset demonstrate that LLM-DSE achieves substantial $2.55\times$ performance gains over state-of-the-art methods, uncovering novel designs while reducing runtime. Ablation studies validate the effectiveness and necessity of the proposed agent interactions. Our code is open-sourced here: https://github.com/Nozidoali/LLM-DSE.
DSLO: Deep Sequence LiDAR Odometry Based on Inconsistent Spatio-temporal Propagation
Sep 01, 2024



This paper introduces a 3D point cloud sequence learning model based on inconsistent spatio-temporal propagation for LiDAR odometry, termed DSLO. It consists of a pyramid structure with a spatial information reuse strategy, a sequential pose initialization module, a gated hierarchical pose refinement module, and a temporal feature propagation module. First, spatial features are encoded using a point feature pyramid, with features reused in successive pose estimations to reduce computational overhead. Second, a sequential pose initialization method is introduced, leveraging the high-frequency sampling characteristic of LiDAR to initialize the LiDAR pose. Then, a gated hierarchical pose refinement mechanism refines poses from coarse to fine by selectively retaining or discarding motion information from different layers based on gate estimations. Finally, temporal feature propagation is proposed to incorporate the historical motion information from point cloud sequences, and address the spatial inconsistency issue when transmitting motion information embedded in point clouds between frames. Experimental results on the KITTI odometry dataset and Argoverse dataset demonstrate that DSLO outperforms state-of-the-art methods, achieving at least a 15.67\% improvement on RTE and a 12.64\% improvement on RRE, while also achieving a 34.69\% reduction in runtime compared to baseline methods. Our implementation will be available at https://github.com/IRMVLab/DSLO.
LHMap-loc: Cross-Modal Monocular Localization Using LiDAR Point Cloud Heat Map
Mar 11, 2024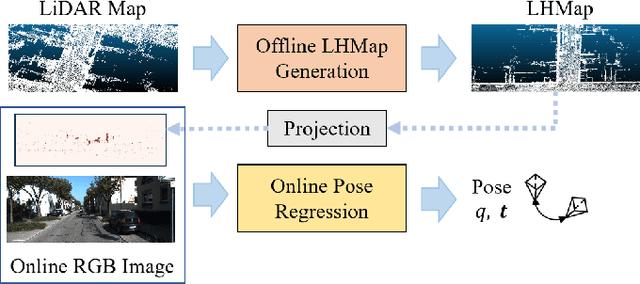
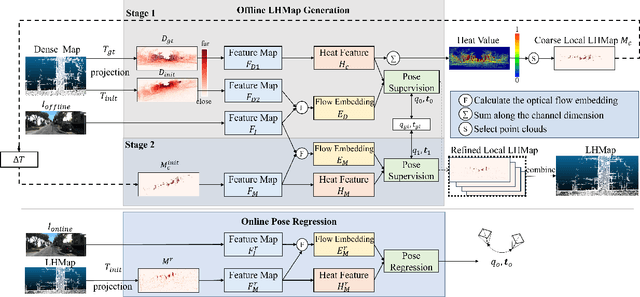
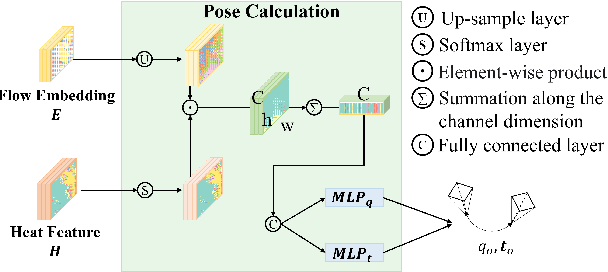

Localization using a monocular camera in the pre-built LiDAR point cloud map has drawn increasing attention in the field of autonomous driving and mobile robotics. However, there are still many challenges (e.g. difficulties of map storage, poor localization robustness in large scenes) in accurately and efficiently implementing cross-modal localization. To solve these problems, a novel pipeline termed LHMap-loc is proposed, which achieves accurate and efficient monocular localization in LiDAR maps. Firstly, feature encoding is carried out on the original LiDAR point cloud map by generating offline heat point clouds, by which the size of the original LiDAR map is compressed. Then, an end-to-end online pose regression network is designed based on optical flow estimation and spatial attention to achieve real-time monocular visual localization in a pre-built map. In addition, a series of experiments have been conducted to prove the effectiveness of the proposed method. Our code is available at: https://github.com/IRMVLab/LHMap-loc.
DELFlow: Dense Efficient Learning of Scene Flow for Large-Scale Point Clouds
Aug 09, 2023



Point clouds are naturally sparse, while image pixels are dense. The inconsistency limits feature fusion from both modalities for point-wise scene flow estimation. Previous methods rarely predict scene flow from the entire point clouds of the scene with one-time inference due to the memory inefficiency and heavy overhead from distance calculation and sorting involved in commonly used farthest point sampling, KNN, and ball query algorithms for local feature aggregation. To mitigate these issues in scene flow learning, we regularize raw points to a dense format by storing 3D coordinates in 2D grids. Unlike the sampling operation commonly used in existing works, the dense 2D representation 1) preserves most points in the given scene, 2) brings in a significant boost of efficiency, and 3) eliminates the density gap between points and pixels, allowing us to perform effective feature fusion. We also present a novel warping projection technique to alleviate the information loss problem resulting from the fact that multiple points could be mapped into one grid during projection when computing cost volume. Sufficient experiments demonstrate the efficiency and effectiveness of our method, outperforming the prior-arts on the FlyingThings3D and KITTI dataset.
Pseudo-LiDAR for Visual Odometry
Sep 04, 2022
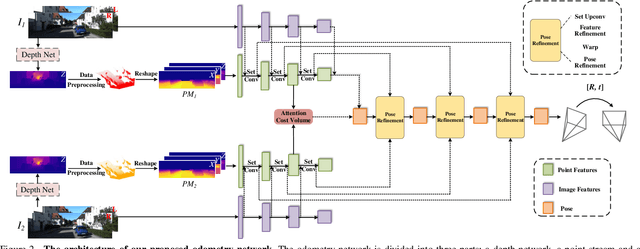
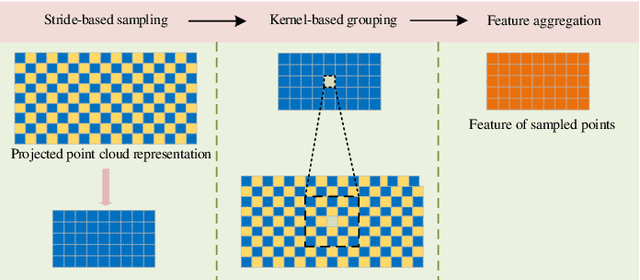
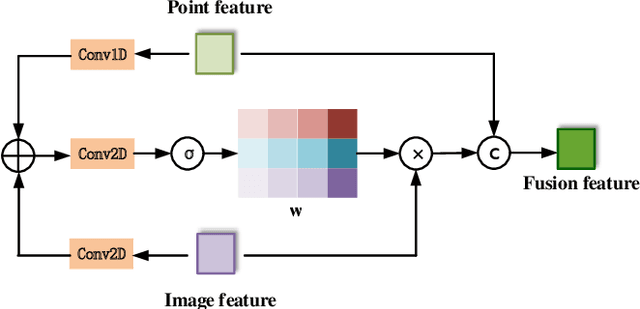
In the existing methods, LiDAR odometry shows superior performance, but visual odometry is still widely used for its price advantage. Conventionally, the task of visual odometry mainly rely on the input of continuous images. However, it is very complicated for the odometry network to learn the epipolar geometry information provided by the images. In this paper, the concept of pseudo-LiDAR is introduced into the odometry to solve this problem. The pseudo-LiDAR point cloud back-projects the depth map generated by the image into the 3D point cloud, which changes the way of image representation. Compared with the stereo images, the pseudo-LiDAR point cloud generated by the stereo matching network can get the explicit 3D coordinates. Since the 6 Degrees of Freedom (DoF) pose transformation occurs in 3D space, the 3D structure information provided by the pseudo-LiDAR point cloud is more direct than the image. Compared with sparse LiDAR, the pseudo-LiDAR has a denser point cloud. In order to make full use of the rich point cloud information provided by the pseudo-LiDAR, a projection-aware dense odometry pipeline is adopted. Most previous LiDAR-based algorithms sampled 8192 points from the point cloud as input to the odometry network. The projection-aware dense odometry pipeline takes all the pseudo-LiDAR point clouds generated from the images except for the error points as the input to the network. While making full use of the 3D geometric information in the images, the semantic information in the images is also used in the odometry task. The fusion of 2D-3D is achieved in an image-only based odometry. Experiments on the KITTI dataset prove the effectiveness of our method. To the best of our knowledge, this is the first visual odometry method using pseudo-LiDAR.
Efficient 3D Deep LiDAR Odometry
Nov 03, 2021
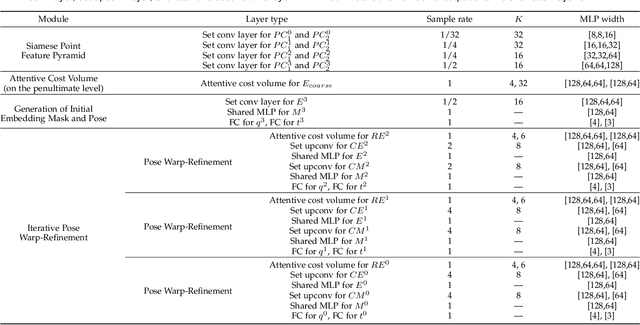

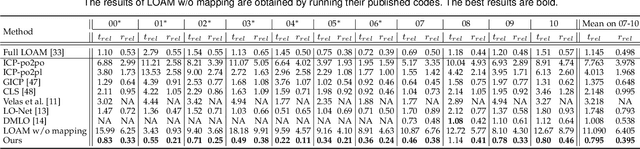
An efficient 3D point cloud learning architecture, named PWCLO-Net, for LiDAR odometry is first proposed in this paper. In this architecture, the projection-aware representation of the 3D point cloud is proposed to organize the raw 3D point cloud into an ordered data form to achieve efficiency. The Pyramid, Warping, and Cost volume (PWC) structure for the LiDAR odometry task is built to estimate and refine the pose in a coarse-to-fine approach hierarchically and efficiently. A projection-aware attentive cost volume is built to directly associate two discrete point clouds and obtain embedding motion patterns. Then, a trainable embedding mask is proposed to weigh the local motion patterns to regress the overall pose and filter outlier points. The trainable pose warp-refinement module is iteratively used with embedding mask optimized hierarchically to make the pose estimation more robust for outliers. The entire architecture is holistically optimized end-to-end to achieve adaptive learning of cost volume and mask, and all operations involving point cloud sampling and grouping are accelerated by projection-aware 3D feature learning methods. The superior performance and effectiveness of our LiDAR odometry architecture are demonstrated on KITTI odometry dataset. Our method outperforms all recent learning-based methods and even the geometry-based approach, LOAM with mapping optimization, on most sequences of KITTI odometry dataset.
Residual 3D Scene Flow Learning with Context-Aware Feature Extraction
Sep 10, 2021

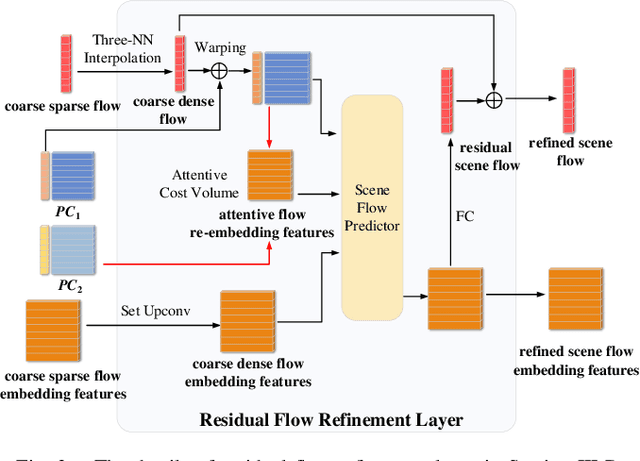

Scene flow estimation is the task to predict the point-wise 3D displacement vector between two consecutive frames of point clouds, which has important application in fields such as service robots and autonomous driving. Although many previous works have explored greatly on scene flow estimation based on point clouds, we point out two problems that have not been noticed or well solved before: 1) Points of adjacent frames in repetitive patterns may be wrongly associated due to similar spatial structure in their neighbourhoods; 2) Scene flow between adjacent frames of point clouds with long-distance movement may be inaccurately estimated. To solve the first problem, we propose a novel context-aware set conv layer to exploit contextual structure information of Euclidean space and learn soft aggregation weights for local point features. Our design is inspired by human perception of contextual structure information during scene understanding. We incorporate the context-aware set conv layer in a context-aware point feature pyramid module of 3D point clouds for scene flow estimation. For the second problem, we propose an explicit residual flow learning structure in the residual flow refinement layer to cope with long-distance movement. The experiments and ablation study on FlyingThings3D and KITTI scene flow datasets demonstrate the effectiveness of each proposed component and that we solve problem of ambiguous inter-frame association and long-distance movement estimation. Quantitative results on both FlyingThings3D and KITTI scene flow datasets show that our method achieves state-of-the-art performance, surpassing all other previous works to the best of our knowledge by at least 25%.
PWCLO-Net: Deep LiDAR Odometry in 3D Point Clouds Using Hierarchical Embedding Mask Optimization
Dec 02, 2020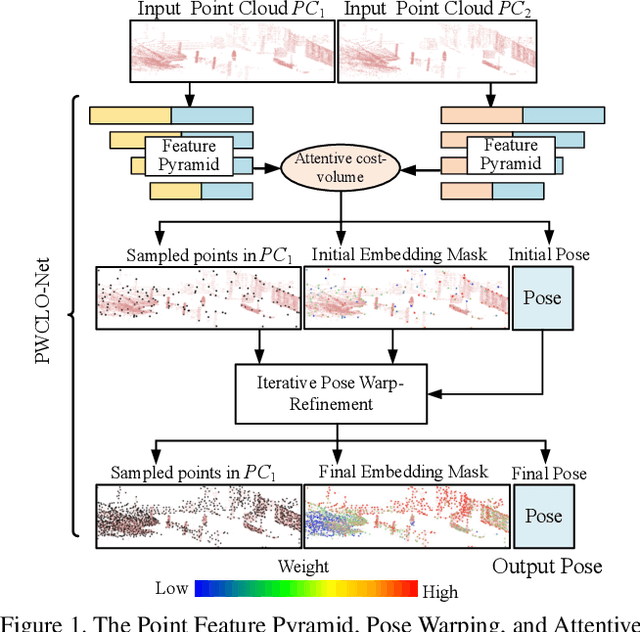



A novel 3D point cloud learning model for deep LiDAR odometry, named PWCLO-Net, using hierarchical embedding mask optimization is proposed in this paper. In this model, the Pyramid, Warping, and Cost volume (PWC) structure for the LiDAR Odometry task is built to hierarchically refine the estimated pose in a coarse-to-fine approach. An attentive cost volume is built to associate two point clouds and obtain the embedding motion information. Then, a novel trainable embedding mask is proposed to weight the cost volume of all points to the overall pose information and filter outlier points. The estimated current pose is used to warp the first point cloud to bridge the distance to the second point cloud, and then the cost volume of the residual motion is built. At the same time, the embedding mask is optimized hierarchically from coarse to fine to obtain more accurate filtering information for pose refinement. The pose warp-refinement process is repeatedly used to make the pose estimation more robust for outliers. The superior performance and effectiveness of our LiDAR odometry model are demonstrated on the KITTI odometry dataset. Our method outperforms all recent learning-based methods and outperforms the geometry-based approach, LOAM with mapping optimization, on most sequences of the KITTI odometry dataset.
Hierarchical Attention Learning of Scene Flow in 3D Point Clouds
Oct 12, 2020



Scene flow represents the 3D motion of every point in the dynamic environments. Like the optical flow that represents the motion of pixels in 2D images, 3D motion representation of scene flow benefits many applications, such as autonomous driving and service robot. This paper studies the problem of scene flow estimation from two consecutive 3D point clouds. In this paper, a novel hierarchical neural network with double attention is proposed for learning the correlation of point features in adjacent frames and refining scene flow from coarse to fine layer by layer. The proposed network has a new more-for-less hierarchical architecture. The more-for-less means that the number of input points is greater than the number of output points for scene flow estimation, which brings more input information and balances the precision and resource consumption. In this hierarchical architecture, scene flow of different levels is generated and supervised respectively. A novel attentive embedding module is introduced to aggregate the features of adjacent points using a double attention method in a patch-to-patch manner. The proper layers for flow embedding and flow supervision are carefully considered in our network designment. Experiments show that the proposed network outperforms the state-of-the-art performance of 3D scene flow estimation on the FlyingThings3D and KITTI Scene Flow 2015 datasets. We also apply the proposed network to realistic LiDAR odometry task, which is an key problem in autonomous driving. The experiment results demonstrate that our proposed network can outperform the ICP-based method and shows the good practical application ability.