 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspherical Energy Transformer with Recurrent Depth
Feb 17, 2025



Transformer-based foundation models have achieved unprecedented success with a gigantic amount of parameters and computational resources. Yet, the core building blocks of these models, the Transformer layers, and how they are arranged and configured are primarily engineered from the bottom up and driven by heuristics. For advancing next-generation architectures, it demands exploring a prototypical model that is amenable to high interpretability and of practical competence. To this end, we take a step from the top-down view and design neural networks from an energy minimization perspective. Specifically, to promote isotropic token distribution on the sphere, we formulate a modified Hopfield energy function on the subspace-embedded hypersphere, based on which Transformer layers with symmetric structures are designed as the iterative optimization for the energy function. By integrating layers with the same parameters, we propose \textit{Hyper-Spherical Energy Transformer} (Hyper-SET), an alternative to the vanilla Transformer with recurrent depth. This design inherently provides greater interpretability and allows for scaling to deeper layers without a significant increase in the number of parameters. We also empirically demonstrate that Hyper-SET achieves comparable or even superior performance on both synthetic and real-world tasks, such as solving Sudoku and masked image modeling, while utilizing fewer parameters.
An In-depth Investigation of Sparse Rate Reduction in Transformer-like Models
Nov 26, 2024Deep neural networks have long been criticized for being black-box. To unveil the inner workings of modern neural architectures, a recent work \cite{yu2024white} proposed an information-theoretic objective function called Sparse Rate Reduction (SRR) and interpreted its unrolled optimization as a Transformer-like model called Coding Rate Reduction Transformer (CRATE). However, the focus of the study was primarily on the basic implementation, and whether this objective is optimized in practice and its causal relationship to generalization remain elusive. Going beyond this study, we derive different implementations by analyzing layer-wise behaviors of CRATE, both theoretically and empirically. To reveal the predictive power of SRR on generalization, we collect a set of model variants induced by varied implementations and hyperparameters and evaluate SRR as a complexity measure based on its correlation with generalization. Surprisingly, we find out that SRR has a positive correlation coefficient and outperforms other baseline measures, such as path-norm and sharpness-based ones. Furthermore, we show that generalization can be improved using SRR as regularization on benchmark image classification datasets. We hope this paper can shed light on leveraging SRR to design principled models and study their generalization ability.
What Matters for 3D Scene Flow Network
Jul 19, 2022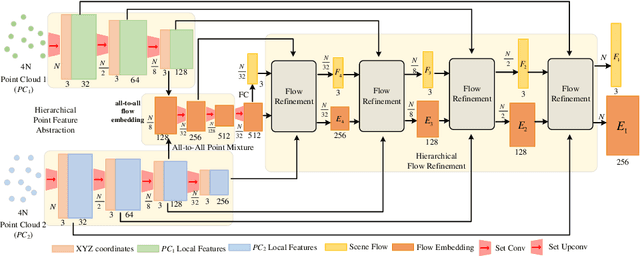
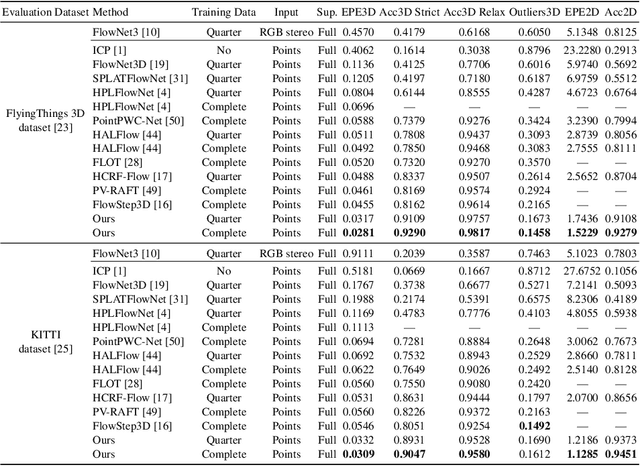


3D scene flow estimation from point clouds is a low-level 3D motion perception task in computer vision. Flow embedding is a commonly used technique in scene flow estimation, and it encodes the point motion between two consecutive frames. Thus, it is critical for the flow embeddings to capture the correct overall direction of the motion. However, previous works only search locally to determine a soft correspondence, ignoring the distant points that turn out to be the actual matching ones. In addition, the estimated correspondence is usually from the forward direction of the adjacent point clouds, and may not be consistent with the estimated correspondence acquired from the backward direction. To tackle these problems, we propose a novel all-to-all flow embedding layer with backward reliability validation during the initial scene flow estimation. Besides, we investigate and compare several design choices in key components of the 3D scene flow network, including the point similarity calculation, input elements of predictor, and predictor & refinement level design. After carefully choosing the most effective designs, we are able to present a model that achieves the state-of-the-art performance on FlyingThings3D and KITTI Scene Flow datasets. Our proposed model surpasses all existing methods by at least 38.2% on FlyingThings3D dataset and 24.7% on KITTI Scene Flow dataset for EPE3D metric. We release our codes at https://github.com/IRMVLab/3DFlow.
Residual 3D Scene Flow Learning with Context-Aware Feature Extraction
Sep 10, 2021

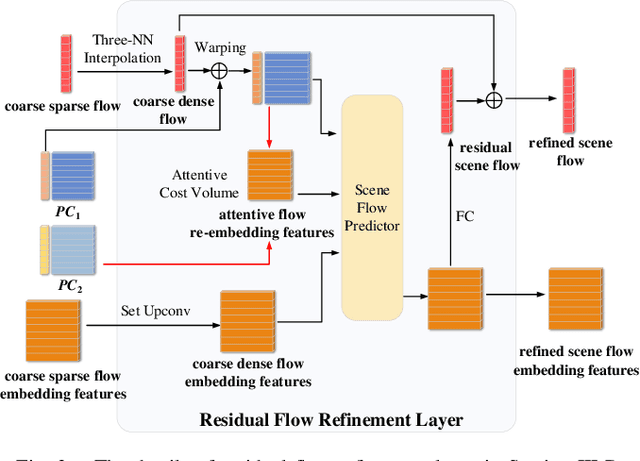

Scene flow estimation is the task to predict the point-wise 3D displacement vector between two consecutive frames of point clouds, which has important application in fields such as service robots and autonomous driving. Although many previous works have explored greatly on scene flow estimation based on point clouds, we point out two problems that have not been noticed or well solved before: 1) Points of adjacent frames in repetitive patterns may be wrongly associated due to similar spatial structure in their neighbourhoods; 2) Scene flow between adjacent frames of point clouds with long-distance movement may be inaccurately estimated. To solve the first problem, we propose a novel context-aware set conv layer to exploit contextual structure information of Euclidean space and learn soft aggregation weights for local point features. Our design is inspired by human perception of contextual structure information during scene understanding. We incorporate the context-aware set conv layer in a context-aware point feature pyramid module of 3D point clouds for scene flow estimation. For the second problem, we propose an explicit residual flow learning structure in the residual flow refinement layer to cope with long-distance movement. The experiments and ablation study on FlyingThings3D and KITTI scene flow datasets demonstrate the effectiveness of each proposed component and that we solve problem of ambiguous inter-frame association and long-distance movement estimation. Quantitative results on both FlyingThings3D and KITTI scene flow datasets show that our method achieves state-of-the-art performance, surpassing all other previous works to the best of our knowledge by at least 25%.