 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstand and Accelerate Memory Processing Pipeline for Disaggregated LLM Inference
Mar 30, 2026Modern large language models (LLMs) increasingly depends on efficient long-context processing and generation mechanisms, including sparse attention, retrieval-augmented generation (RAG), and compressed contextual memory, to support complex reasoning. We show that these optimizations can be unified into a four-step memory processing pipeline: Prepare Memory, Compute Relevancy, Retrieval, and Apply to Inference. Through systematic profiling, we identify a 22%-97% memory processing overhead in LLM inference and strong heterogeneity in its computational characteristics. Motivated by this insight, we argue that \textbf{heterogeneous systems} are well-suited to accelerate memory processing and thus end-to-end inference. We demonstrate this approach on a GPU-FPGA system by offloading sparse, irregular, and memory-bounded operations to FPGAs while retaining compute-intensive operations on GPUs. Evaluated on an AMD MI210 GPU and an Alveo U55C FPGA, our system is $1.04\sim2.2\times$ faster and requires $1.11\sim4.7\times$ less energy across multiple LLM inference optimizations than the GPU baseline (similar results hold on NVIDIA A100). These results establish heterogeneous systems as a practical direction for efficient LLM memory processing and inform future heterogeneous hardware design.
AI+HW 2035: Shaping the Next Decade
Mar 05, 2026Artificial intelligence (AI) and hardware (HW) are advancing at unprecedented rates, yet their trajectories have become inseparably intertwined. The global research community lacks a cohesive, long-term vision to strategically coordinate the development of AI and HW. This fragmentation constrains progress toward holistic, sustainable, and adaptive AI systems capable of learning, reasoning, and operating efficiently across cloud, edge, and physical environments. The future of AI depends not only on scaling intelligence, but on scaling efficiency, achieving exponential gains in intelligence per joule, rather than unbounded compute consumption. Addressing this grand challenge requires rethinking the entire computing stack. This vision paper lays out a 10-year roadmap for AI+HW co-design and co-development, spanning algorithms, architectures, systems, and sustainability. We articulate key insights that redefine scaling around energy efficiency, system-level integration, and cross-layer optimization. We identify key challenges and opportunities, candidly assess potential obstacles and pitfalls, and propose integrated solutions grounded in algorithmic innovation, hardware advances, and software abstraction. Looking ahead, we define what success means in 10 years: achieving a 1000x improvement in efficiency for AI training and inference; enabling energy-aware, self-optimizing systems that seamlessly span cloud, edge, and physical AI; democratizing access to advanced AI infrastructure; and embedding human-centric principles into the design of intelligent systems. Finally, we outline concrete action items for academia, industry, government, and the broader community, calling for coordinated national initiatives, shared infrastructure, workforce development, cross-agency collaboration, and sustained public-private partnerships to ensure that AI+HW co-design becomes a unifying long-term mission.
ARLArena: A Unified Framework for Stable Agentic Reinforcement Learning
Feb 25, 2026Agentic reinforcement learning (ARL) has rapidly gained attention as a promising paradigm for training agents to solve complex, multi-step interactive tasks. Despite encouraging early results, ARL remains highly unstable, often leading to training collapse. This instability limits scalability to larger environments and longer interaction horizons, and constrains systematic exploration of algorithmic design choices. In this paper, we first propose ARLArena, a stable training recipe and systematic analysis framework that examines training stability in a controlled and reproducible setting. ARLArena first constructs a clean and standardized testbed. Then, we decompose policy gradient into four core design dimensions and assess the performance and stability of each dimension. Through this fine-grained analysis, we distill a unified perspective on ARL and propose SAMPO, a stable agentic policy optimization method designed to mitigate the dominant sources of instability in ARL. Empirically, SAMPO achieves consistently stable training and strong performance across diverse agentic tasks. Overall, this study provides a unifying policy gradient perspective for ARL and offers practical guidance for building stable and reproducible LLM-based agent training pipelines.
FlexLLM: Composable HLS Library for Flexible Hybrid LLM Accelerator Design
Jan 22, 2026We present FlexLLM, a composable High-Level Synthesis (HLS) library for rapid development of domain-specific LLM accelerators. FlexLLM exposes key architectural degrees of freedom for stage-customized inference, enabling hybrid designs that tailor temporal reuse and spatial dataflow differently for prefill and decode, and provides a comprehensive quantization suite to support accurate low-bit deployment. Using FlexLLM, we build a complete inference system for the Llama-3.2 1B model in under two months with only 1K lines of code. The system includes: (1) a stage-customized accelerator with hardware-efficient quantization (12.68 WikiText-2 PPL) surpassing SpinQuant baseline, and (2) a Hierarchical Memory Transformer (HMT) plug-in for efficient long-context processing. On the AMD U280 FPGA at 16nm, the accelerator achieves 1.29$\times$ end-to-end speedup, 1.64$\times$ higher decode throughput, and 3.14$\times$ better energy efficiency than an NVIDIA A100 GPU (7nm) running BF16 inference; projected results on the V80 FPGA at 7nm reach 4.71$\times$, 6.55$\times$, and 4.13$\times$, respectively. In long-context scenarios, integrating the HMT plug-in reduces prefill latency by 23.23$\times$ and extends the context window by 64$\times$, delivering 1.10$\times$/4.86$\times$ lower end-to-end latency and 5.21$\times$/6.27$\times$ higher energy efficiency on the U280/V80 compared to the A100 baseline. FlexLLM thus bridges algorithmic innovation in LLM inference and high-performance accelerators with minimal manual effort.
Report for NSF Workshop on AI for Electronic Design Automation
Jan 20, 2026This report distills the discussions and recommendations from the NSF Workshop on AI for Electronic Design Automation (EDA), held on December 10, 2024 in Vancouver alongside NeurIPS 2024. Bringing together experts across machine learning and EDA, the workshop examined how AI-spanning large language models (LLMs), graph neural networks (GNNs), reinforcement learning (RL), neurosymbolic methods, etc.-can facilitate EDA and shorten design turnaround. The workshop includes four themes: (1) AI for physical synthesis and design for manufacturing (DFM), discussing challenges in physical manufacturing process and potential AI applications; (2) AI for high-level and logic-level synthesis (HLS/LLS), covering pragma insertion, program transformation, RTL code generation, etc.; (3) AI toolbox for optimization and design, discussing frontier AI developments that could potentially be applied to EDA tasks; and (4) AI for test and verification, including LLM-assisted verification tools, ML-augmented SAT solving, security/reliability challenges, etc. The report recommends NSF to foster AI/EDA collaboration, invest in foundational AI for EDA, develop robust data infrastructures, promote scalable compute infrastructure, and invest in workforce development to democratize hardware design and enable next-generation hardware systems. The workshop information can be found on the website https://ai4eda-workshop.github.io/.
LUT-LLM: Efficient Large Language Model Inference with Memory-based Computations on FPGAs
Nov 09, 2025The rapid progress of large language models (LLMs) has advanced numerous applications, yet efficient single-batch inference remains vital for on-device intelligence. While FPGAs offer fine-grained data control and high energy efficiency, recent GPU optimizations have narrowed their advantage, especially under arithmetic-based computation. To overcome this, we leverage FPGAs' abundant on-chip memory to shift LLM inference from arithmetic- to memory-based computation through table lookups. We present LUT-LLM, the first FPGA accelerator enabling 1B+ LLM inference via vector-quantized memory operations. Our analysis identifies activation-weight co-quantization as the most effective scheme, supported by (1) bandwidth-aware parallel centroid search, (2) efficient 2D table lookups, and (3) a spatial-temporal hybrid design minimizing data caching. Implemented on an AMD V80 FPGA for a customized Qwen 3 1.7B model, LUT-LLM achieves 1.66x lower latency than AMD MI210 and 1.72x higher energy efficiency than NVIDIA A100, scaling to 32B models with 2.16x efficiency gain over A100.
LLM-DSE: Searching Accelerator Parameters with LLM Agents
May 18, 2025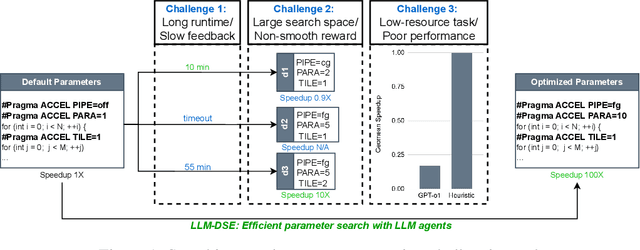
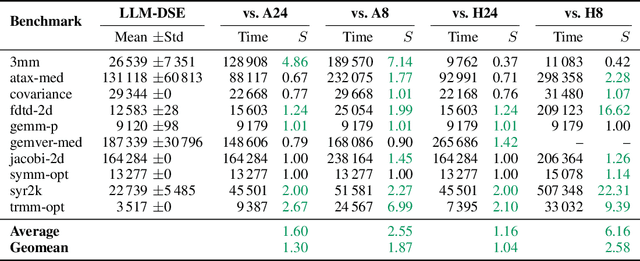
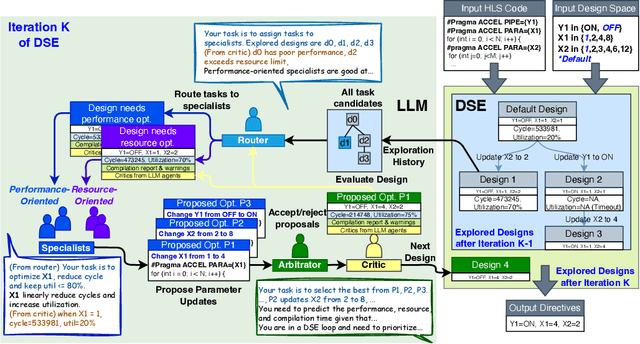

Even though high-level synthesis (HLS) tools mitigate the challenges of programming domain-specific accelerators (DSAs) by raising the abstraction level, optimizing hardware directive parameters remains a significant hurdle. Existing heuristic and learning-based methods struggle with adaptability and sample efficiency.We present LLM-DSE, a multi-agent framework designed specifically for optimizing HLS directives. Combining LLM with design space exploration (DSE), our explorer coordinates four agents: Router, Specialists, Arbitrator, and Critic. These multi-agent components interact with various tools to accelerate the optimization process. LLM-DSE leverages essential domain knowledge to identify efficient parameter combinations while maintaining adaptability through verbal learning from online interactions. Evaluations on the HLSyn dataset demonstrate that LLM-DSE achieves substantial $2.55\times$ performance gains over state-of-the-art methods, uncovering novel designs while reducing runtime. Ablation studies validate the effectiveness and necessity of the proposed agent interactions. Our code is open-sourced here: https://github.com/Nozidoali/LLM-DSE.
LIFT: LLM-Based Pragma Insertion for HLS via GNN Supervised Fine-Tuning
Apr 29, 2025
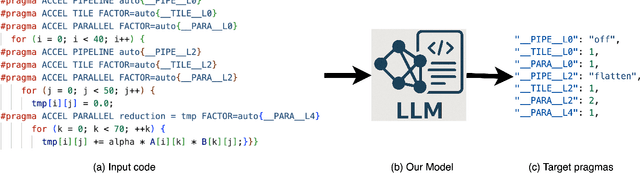
FPGAs are increasingly adopted in datacenter environments for their reconfigurability and energy efficiency. High-Level Synthesis (HLS) tools have eased FPGA programming by raising the abstraction level from RTL to untimed C/C++, yet attaining high performance still demands expert knowledge and iterative manual insertion of optimization pragmas to modify the microarchitecture. To address this challenge, we propose LIFT, a large language model (LLM)-based coding assistant for HLS that automatically generates performance-critical pragmas given a C/C++ design. We fine-tune the LLM by tightly integrating and supervising the training process with a graph neural network (GNN), combining the sequential modeling capabilities of LLMs with the structural and semantic understanding of GNNs necessary for reasoning over code and its control/data dependencies. On average, LIFT produces designs that improve performance by 3.52x and 2.16x than prior state-of the art AutoDSE and HARP respectively, and 66x than GPT-4o.
InTAR: Inter-Task Auto-Reconfigurable Accelerator Design for High Data Volume Variation in DNNs
Feb 12, 2025The rise of deep neural networks (DNNs) has driven a boom in AI services, which results in an increased demand for computing power and memory. In modern DNNs, the data sizes produced and consumed are highly varied across operations (high data volume variation, HDV). Because existing design paradigms use fixed execution patterns that lead to either low computational efficiency due to pipeline stalls or frequent off-chip memory accesses to manage large intermediate data, HDV applications are challenging to accelerate on FPGAs. To address these challenges, we introduce the Inter-Task Auto-Reconfigurable Accelerator (InTAR), a novel accelerator design for HDV applications on FPGAs. InTAR combines the high computational efficiency of sequential execution with the reduced off-chip memory overhead of dataflow execution. It switches execution patterns automatically with a static schedule determined before circuit design based on resource constraints and model parameters. Unlike previous reconfigurable accelerators, InTAR encodes reconfiguration schedules during circuit design, allowing model-specific optimizations that allocate only the necessary logic and interconnects. Thus, InTAR achieves a high clock frequency with fewer resources and low reconfiguration time. Furthermore, InTAR supports high-level tools such as HLS for fast design generation. We implement a set of multi-task kernels in various HDV DNNs using InTAR. Compared with dataflow and sequential accelerators, InTAR exhibits $1.8\times$ and $7.1 \times$ speedups correspondingly. We also implement InTAR for GPT-2 medium as a more complex example, which achieves a speedup of $\mathbf{3.65 \sim 39.14\times}$ and a $\mathbf{1.72 \sim 10.44\times}$ boost in DSP efficiency compared to the corresponding SoTA accelerators on FPGAs.
Hierarchical Mixture of Experts: Generalizable Learning for High-Level Synthesis
Oct 25, 2024



High-level synthesis (HLS) is a widely used tool in designing Field Programmable Gate Array (FPGA). HLS enables FPGA design with software programming languages by compiling the source code into an FPGA circuit. The source code includes a program (called ``kernel'') and several pragmas that instruct hardware synthesis, such as parallelization, pipeline, etc. While it is relatively easy for software developers to design the program, it heavily relies on hardware knowledge to design the pragmas, posing a big challenge for software developers. Recently, different machine learning algorithms, such as GNNs, have been proposed to automate the pragma design via performance prediction. However, when applying the trained model on new kernels, the significant domain shift often leads to unsatisfactory performance. We propose a more domain-generalizable model structure: a two-level hierarchical Mixture of Experts (MoE), that can be flexibly adapted to any GNN model. Different expert networks can learn to deal with different regions in the representation space, and they can utilize similar patterns between the old kernels and new kernels. In the low-level MoE, we apply MoE on three natural granularities of a program: node, basic block, and graph. The high-level MoE learns to aggregate the three granularities for the final decision. To stably train the hierarchical MoE, we further propose a two-stage training method. Extensive experiments verify the effectiveness of the hierarchical MoE.