 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlockBatch: Multi-Scale Consensus Decoding for Efficient Diffusion Language Model Inference
May 28, 2026Diffusion language models (dLLMs) generate text by iteratively denoising multiple token positions in parallel, offering an attractive alternative to strictly autoregressive decoding. In practice, however, block-wise dLLM inference exposes a difficult granularity trade-off: small blocks preserve local conditioning but require many denoising steps, whereas large blocks expose more parallelism but can make premature commitments and accumulate cache error. Existing acceleration methods typically choose a single block size per request, leaving the complementarity among block sizes unused. We show that block size itself is a useful branching dimension. Different block sizes induce related but non-identical KV-cache trajectories: branches often share an initial prefix, bifurcate at semantically decisive positions, and later agree on syntactically lightweight tokens. Motivated by this structure, we propose BlockBatch, a training-free online inference framework that executes multiple block-size branches for the same request inside a batched forward pass. BlockBatch coordinates these branches through confidence-gated token merging, leader-based synchronization, and periodic full-sequence refreshes that re-anchor local block updates to a globally consistent KV state. Across 3 representative dLLMs and 4 datasets, BlockBatch reduces denoising NFEs by 26.6\% on average and achieves a 1.33$\times$ average end-to-end speedup over Fast-dLLM while preserving accuracy. These results identify block-size diversity as a practical and previously underexplored axis for branch-parallel dLLM inference.
From Inference Efficiency to Embodied Efficiency: Revisiting Efficiency Metrics for Vision-Language-Action Models
Mar 19, 2026Vision-Language-Action (VLA) models have recently enabled embodied agents to perform increasingly complex tasks by jointly reasoning over visual, linguistic, and motor modalities. However, we find that the prevailing notion of ``efficiency'' in current VLA research, characterized by parameters, FLOPs, or token decoding throughput, does not reflect actual performance on robotic platforms. In real-world execution, efficiency is determined by system-level embodied behaviors such as task completion time, trajectory smoothness, cumulative joint rotation, and motion energy. Through controlled studies across model compression, token sparsification, and action sequence compression, we make several observations that challenge common assumptions. (1) Methods that reduce computation under conventional metrics often increase end-to-end execution cost or degrade motion quality, despite maintaining task success rates. (2) System-level embodied efficiency metrics reveal performance differences in the learned action policies that remain hidden under conventional evaluations. (3) Common adaptation methods such as in-context prompting or supervised fine-tuning show only mild and metric-specific improvements in embodied efficiency. While these methods can reduce targeted embodied-efficiency metrics such as jerk or action rate, the resulting gains may come with trade-offs in other metrics, such as longer completion time. Taken together, our results suggest that conventional inference efficiency metrics can overlook important aspects of embodied execution. Incorporating embodied efficiency provides a more complete view of policy behavior and practical performance, enabling fairer and more comprehensive comparisons of VLA models.
Report for NSF Workshop on AI for Electronic Design Automation
Jan 20, 2026This report distills the discussions and recommendations from the NSF Workshop on AI for Electronic Design Automation (EDA), held on December 10, 2024 in Vancouver alongside NeurIPS 2024. Bringing together experts across machine learning and EDA, the workshop examined how AI-spanning large language models (LLMs), graph neural networks (GNNs), reinforcement learning (RL), neurosymbolic methods, etc.-can facilitate EDA and shorten design turnaround. The workshop includes four themes: (1) AI for physical synthesis and design for manufacturing (DFM), discussing challenges in physical manufacturing process and potential AI applications; (2) AI for high-level and logic-level synthesis (HLS/LLS), covering pragma insertion, program transformation, RTL code generation, etc.; (3) AI toolbox for optimization and design, discussing frontier AI developments that could potentially be applied to EDA tasks; and (4) AI for test and verification, including LLM-assisted verification tools, ML-augmented SAT solving, security/reliability challenges, etc. The report recommends NSF to foster AI/EDA collaboration, invest in foundational AI for EDA, develop robust data infrastructures, promote scalable compute infrastructure, and invest in workforce development to democratize hardware design and enable next-generation hardware systems. The workshop information can be found on the website https://ai4eda-workshop.github.io/.
Fewer Denoising Steps or Cheaper Per-Step Inference: Towards Compute-Optimal Diffusion Model Deployment
Aug 08, 2025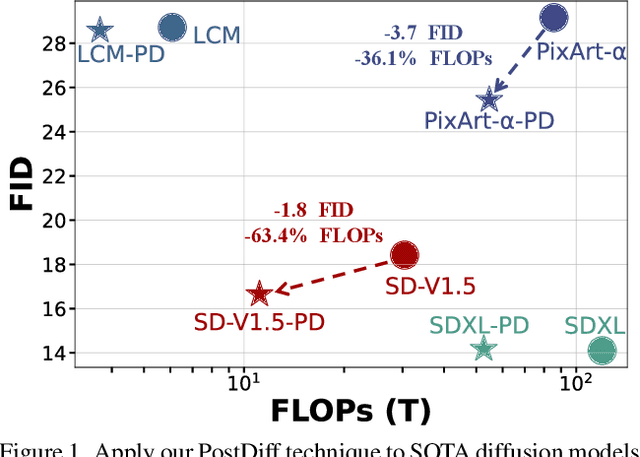
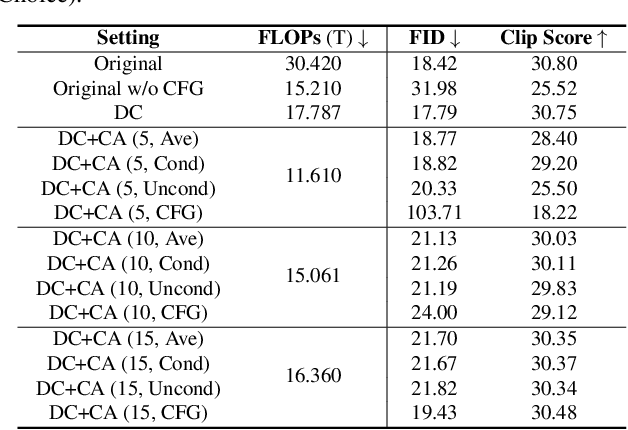
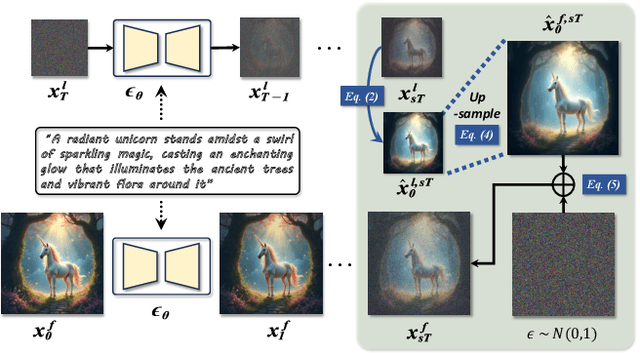
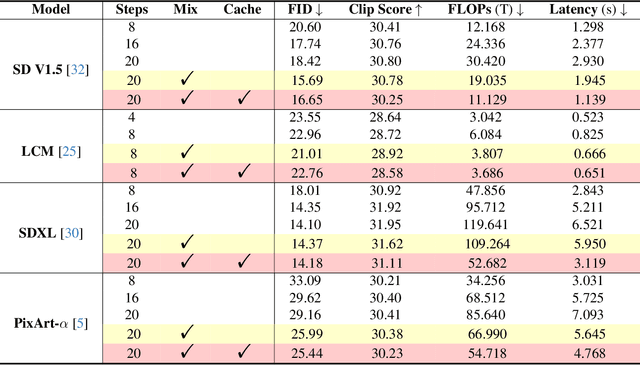
Diffusion models have shown remarkable success across generative tasks, yet their high computational demands challenge deployment on resource-limited platforms. This paper investigates a critical question for compute-optimal diffusion model deployment: Under a post-training setting without fine-tuning, is it more effective to reduce the number of denoising steps or to use a cheaper per-step inference? Intuitively, reducing the number of denoising steps increases the variability of the distributions across steps, making the model more sensitive to compression. In contrast, keeping more denoising steps makes the differences smaller, preserving redundancy, and making post-training compression more feasible. To systematically examine this, we propose PostDiff, a training-free framework for accelerating pre-trained diffusion models by reducing redundancy at both the input level and module level in a post-training manner. At the input level, we propose a mixed-resolution denoising scheme based on the insight that reducing generation resolution in early denoising steps can enhance low-frequency components and improve final generation fidelity. At the module level, we employ a hybrid module caching strategy to reuse computations across denoising steps. Extensive experiments and ablation studies demonstrate that (1) PostDiff can significantly improve the fidelity-efficiency trade-off of state-of-the-art diffusion models, and (2) to boost efficiency while maintaining decent generation fidelity, reducing per-step inference cost is often more effective than reducing the number of denoising steps. Our code is available at https://github.com/GATECH-EIC/PostDiff.
CLIMB: CLustering-based Iterative Data Mixture Bootstrapping for Language Model Pre-training
Apr 17, 2025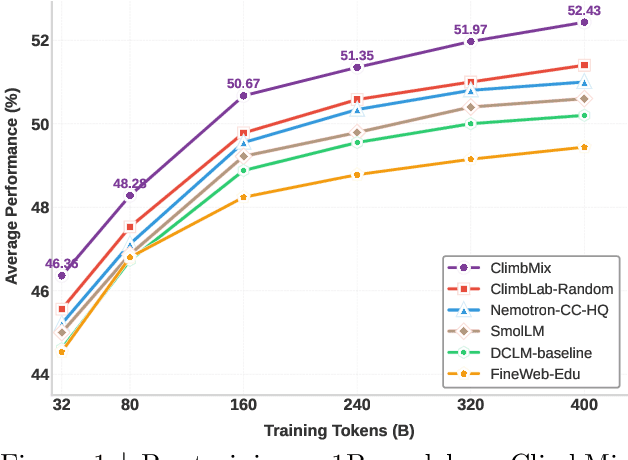
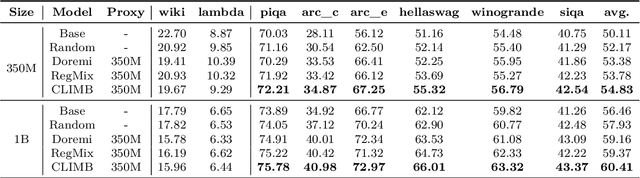
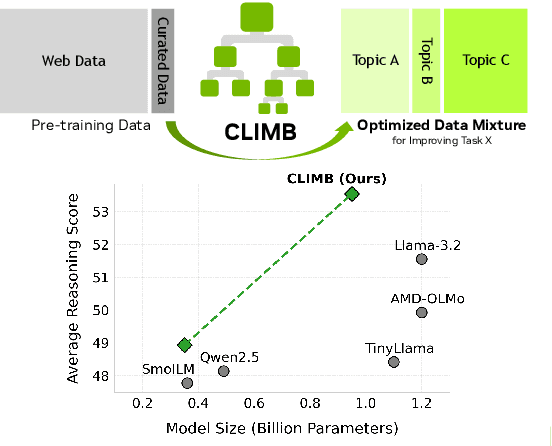
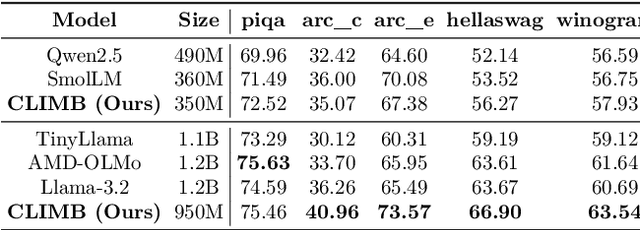
Pre-training datasets are typically collected from web content and lack inherent domain divisions. For instance, widely used datasets like Common Crawl do not include explicit domain labels, while manually curating labeled datasets such as The Pile is labor-intensive. Consequently, identifying an optimal pre-training data mixture remains a challenging problem, despite its significant benefits for pre-training performance. To address these challenges, we propose CLustering-based Iterative Data Mixture Bootstrapping (CLIMB), an automated framework that discovers, evaluates, and refines data mixtures in a pre-training setting. Specifically, CLIMB embeds and clusters large-scale datasets in a semantic space and then iteratively searches for optimal mixtures using a smaller proxy model and a predictor. When continuously trained on 400B tokens with this mixture, our 1B model exceeds the state-of-the-art Llama-3.2-1B by 2.0%. Moreover, we observe that optimizing for a specific domain (e.g., Social Sciences) yields a 5% improvement over random sampling. Finally, we introduce ClimbLab, a filtered 1.2-trillion-token corpus with 20 clusters as a research playground, and ClimbMix, a compact yet powerful 400-billion-token dataset designed for efficient pre-training that delivers superior performance under an equal token budget. We analyze the final data mixture, elucidating the characteristics of an optimal data mixture. Our data is available at: https://research.nvidia.com/labs/lpr/climb/
Early-Bird Diffusion: Investigating and Leveraging Timestep-Aware Early-Bird Tickets in Diffusion Models for Efficient Training
Apr 13, 2025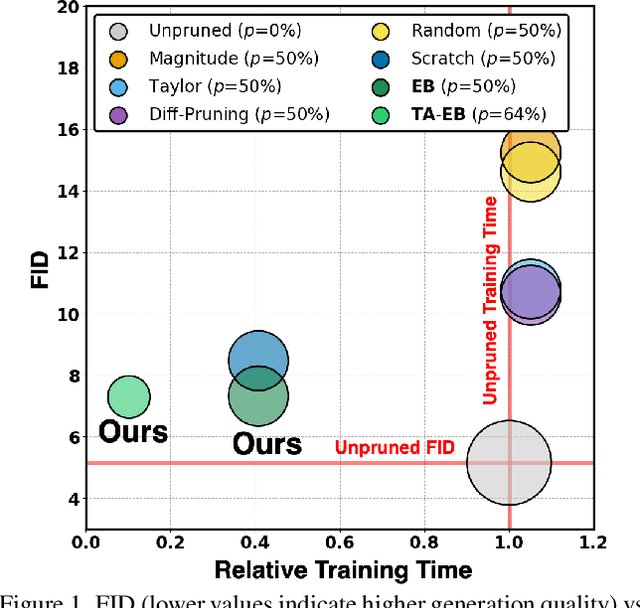
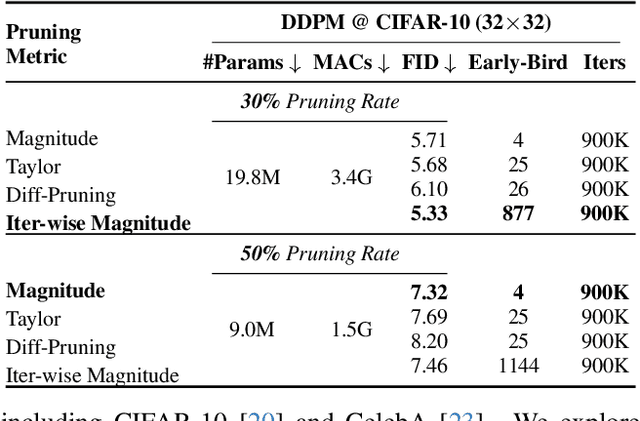
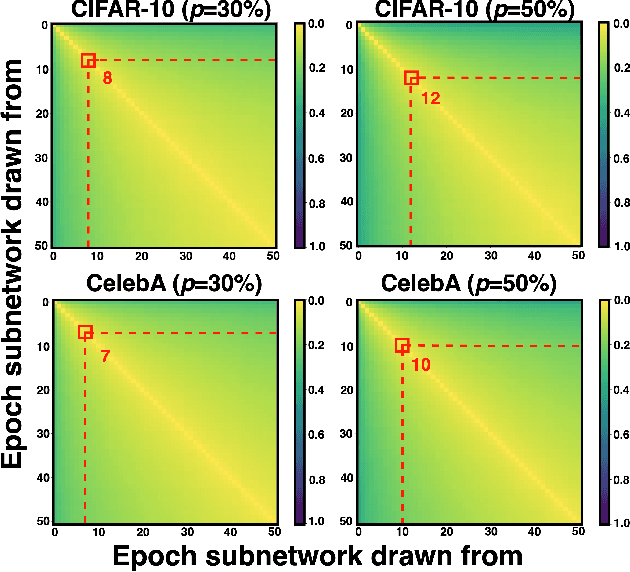
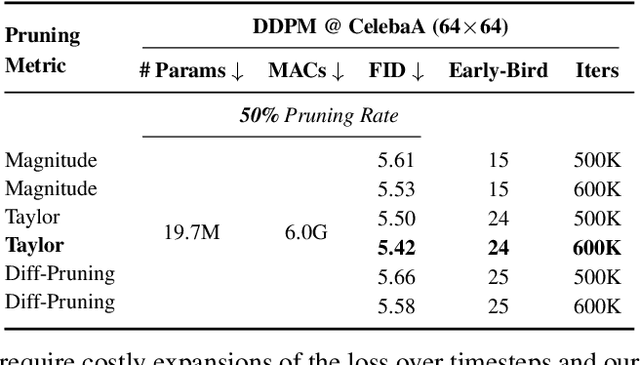
Training diffusion models (DMs) requires substantial computational resources due to multiple forward and backward passes across numerous timesteps, motivating research into efficient training techniques. In this paper, we propose EB-Diff-Train, a new efficient DM training approach that is orthogonal to other methods of accelerating DM training, by investigating and leveraging Early-Bird (EB) tickets -- sparse subnetworks that manifest early in the training process and maintain high generation quality. We first investigate the existence of traditional EB tickets in DMs, enabling competitive generation quality without fully training a dense model. Then, we delve into the concept of diffusion-dedicated EB tickets, drawing on insights from varying importance of different timestep regions. These tickets adapt their sparsity levels according to the importance of corresponding timestep regions, allowing for aggressive sparsity during non-critical regions while conserving computational resources for crucial timestep regions. Building on this, we develop an efficient DM training technique that derives timestep-aware EB tickets, trains them in parallel, and combines them during inference for image generation. Extensive experiments validate the existence of both traditional and timestep-aware EB tickets, as well as the effectiveness of our proposed EB-Diff-Train method. This approach can significantly reduce training time both spatially and temporally -- achieving 2.9$\times$ to 5.8$\times$ speedups over training unpruned dense models, and up to 10.3$\times$ faster training compared to standard train-prune-finetune pipelines -- without compromising generative quality. Our code is available at https://github.com/GATECH-EIC/Early-Bird-Diffusion.
MG-Verilog: Multi-grained Dataset Towards Enhanced LLM-assisted Verilog Generation
Jul 02, 2024
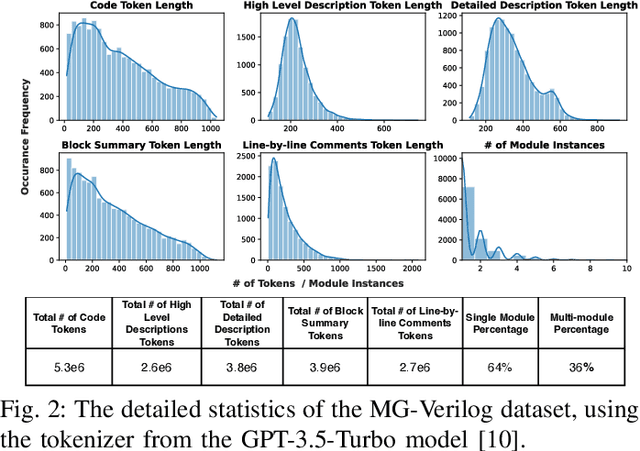
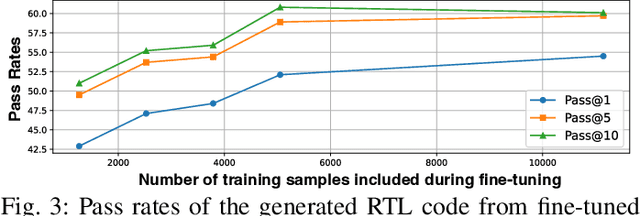
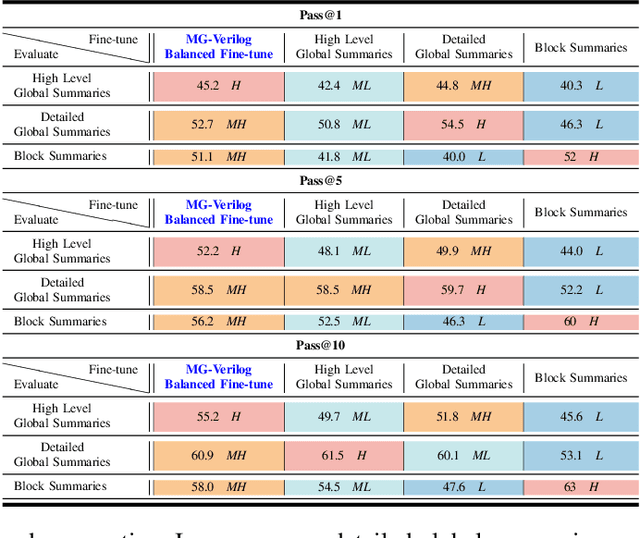
Large Language Models (LLMs) have recently shown promise in streamlining hardware design processes by encapsulating vast amounts of domain-specific data. In addition, they allow users to interact with the design processes through natural language instructions, thus making hardware design more accessible to developers. However, effectively leveraging LLMs in hardware design necessitates providing domain-specific data during inference (e.g., through in-context learning), fine-tuning, or pre-training. Unfortunately, existing publicly available hardware datasets are often limited in size, complexity, or detail, which hinders the effectiveness of LLMs in hardware design tasks. To address this issue, we first propose a set of criteria for creating high-quality hardware datasets that can effectively enhance LLM-assisted hardware design. Based on these criteria, we propose a Multi-Grained-Verilog (MG-Verilog) dataset, which encompasses descriptions at various levels of detail and corresponding code samples. To benefit the broader hardware design community, we have developed an open-source infrastructure that facilitates easy access, integration, and extension of the dataset to meet specific project needs. Furthermore, to fully exploit the potential of the MG-Verilog dataset, which varies in complexity and detail, we introduce a balanced fine-tuning scheme. This scheme serves as a unique use case to leverage the diverse levels of detail provided by the dataset. Extensive experiments demonstrate that the proposed dataset and fine-tuning scheme consistently improve the performance of LLMs in hardware design tasks.
ShiftAddLLM: Accelerating Pretrained LLMs via Post-Training Multiplication-Less Reparameterization
Jun 11, 2024



Large language models (LLMs) have shown impressive performance on language tasks but face challenges when deployed on resource-constrained devices due to their extensive parameters and reliance on dense multiplications, resulting in high memory demands and latency bottlenecks. Shift-and-add reparameterization offers a promising solution by replacing costly multiplications with hardware-friendly primitives in both the attention and multi-layer perceptron (MLP) layers of an LLM. However, current reparameterization techniques require training from scratch or full parameter fine-tuning to restore accuracy, which is resource-intensive for LLMs. To address this, we propose accelerating pretrained LLMs through post-training shift-and-add reparameterization, creating efficient multiplication-free models, dubbed ShiftAddLLM. Specifically, we quantize each weight matrix into binary matrices paired with group-wise scaling factors. The associated multiplications are reparameterized into (1) shifts between activations and scaling factors and (2) queries and adds according to the binary matrices. To reduce accuracy loss, we present a multi-objective optimization method to minimize both weight and output activation reparameterization errors. Additionally, based on varying sensitivity across layers to reparameterization, we develop an automated bit allocation strategy to further reduce memory usage and latency. Experiments on five LLM families and eight tasks consistently validate the effectiveness of ShiftAddLLM, achieving average perplexity improvements of 5.6 and 22.7 points at comparable or lower latency compared to the most competitive quantized LLMs at 3 and 2 bits, respectively, and more than 80% memory and energy reductions over the original LLMs. Codes and models are available at https://github.com/GATECH-EIC/ShiftAddLLM.
When Linear Attention Meets Autoregressive Decoding: Towards More Effective and Efficient Linearized Large Language Models
Jun 11, 2024Autoregressive Large Language Models (LLMs) have achieved impressive performance in language tasks but face two significant bottlenecks: (1) quadratic complexity in the attention module as the number of tokens increases, and (2) limited efficiency due to the sequential processing nature of autoregressive LLMs during generation. While linear attention and speculative decoding offer potential solutions, their applicability and synergistic potential for enhancing autoregressive LLMs remain uncertain. We conduct the first comprehensive study on the efficacy of existing linear attention methods for autoregressive LLMs, integrating them with speculative decoding. We introduce an augmentation technique for linear attention that ensures compatibility with speculative decoding, enabling more efficient training and serving of LLMs. Extensive experiments and ablation studies involving seven existing linear attention models and five encoder/decoder-based LLMs consistently validate the effectiveness of our augmented linearized LLMs. Notably, our approach achieves up to a 6.67 reduction in perplexity on the LLaMA model and up to a 2$\times$ speedup during generation compared to prior linear attention methods. Codes and models are available at https://github.com/GATECH-EIC/Linearized-LLM.
MixRT: Mixed Neural Representations For Real-Time NeRF Rendering
Dec 20, 2023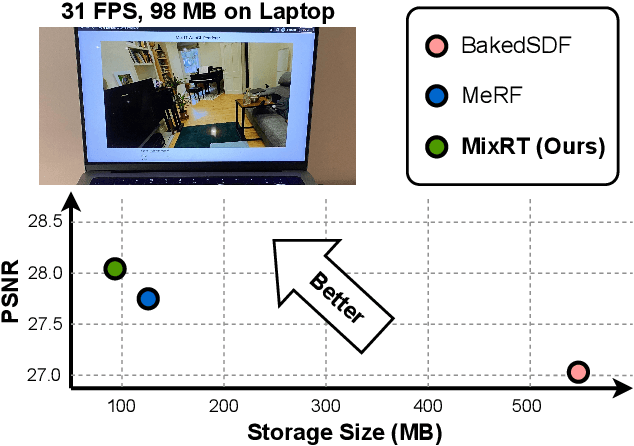

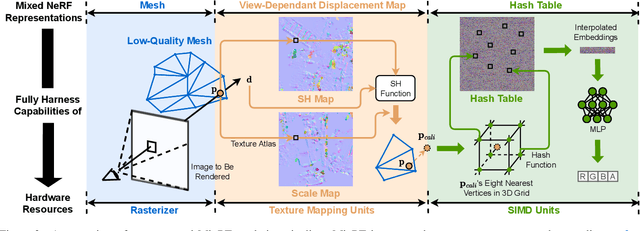

Neural Radiance Field (NeRF) has emerged as a leading technique for novel view synthesis, owing to its impressive photorealistic reconstruction and rendering capability. Nevertheless, achieving real-time NeRF rendering in large-scale scenes has presented challenges, often leading to the adoption of either intricate baked mesh representations with a substantial number of triangles or resource-intensive ray marching in baked representations. We challenge these conventions, observing that high-quality geometry, represented by meshes with substantial triangles, is not necessary for achieving photorealistic rendering quality. Consequently, we propose MixRT, a novel NeRF representation that includes a low-quality mesh, a view-dependent displacement map, and a compressed NeRF model. This design effectively harnesses the capabilities of existing graphics hardware, thus enabling real-time NeRF rendering on edge devices. Leveraging a highly-optimized WebGL-based rendering framework, our proposed MixRT attains real-time rendering speeds on edge devices (over 30 FPS at a resolution of 1280 x 720 on a MacBook M1 Pro laptop), better rendering quality (0.2 PSNR higher in indoor scenes of the Unbounded-360 datasets), and a smaller storage size (less than 80% compared to state-of-the-art methods).