 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiftAddViT: Mixture of Multiplication Primitives Towards Efficient Vision Transformer
Paper and Code
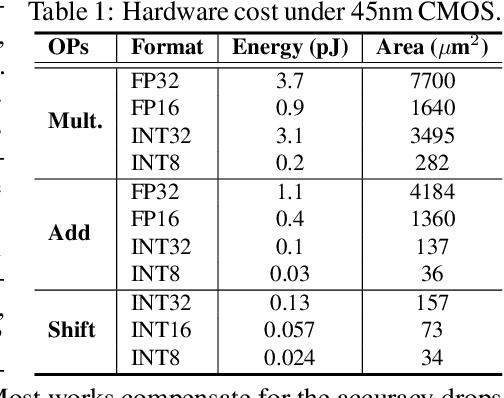
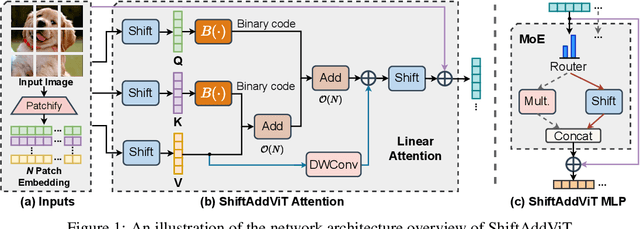

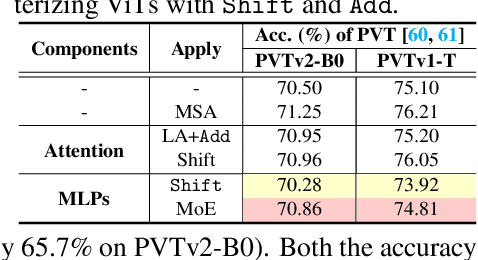
Vision Transformers (ViTs) have shown impressive performance and have become a unified backbone for multiple vision tasks. But both attention and multi-layer perceptions (MLPs) in ViTs are not efficient enough due to dense multiplications, resulting in costly training and inference. To this end, we propose to reparameterize the pre-trained ViT with a mixture of multiplication primitives, e.g., bitwise shifts and additions, towards a new type of multiplication-reduced model, dubbed $\textbf{ShiftAddViT}$, which aims for end-to-end inference speedups on GPUs without the need of training from scratch. Specifically, all $\texttt{MatMuls}$ among queries, keys, and values are reparameterized by additive kernels, after mapping queries and keys to binary codes in Hamming space. The remaining MLPs or linear layers are then reparameterized by shift kernels. We utilize TVM to implement and optimize those customized kernels for practical hardware deployment on GPUs. We find that such a reparameterization on (quadratic or linear) attention maintains model accuracy, while inevitably leading to accuracy drops when being applied to MLPs. To marry the best of both worlds, we further propose a new mixture of experts (MoE) framework to reparameterize MLPs by taking multiplication or its primitives as experts, e.g., multiplication and shift, and designing a new latency-aware load-balancing loss. Such a loss helps to train a generic router for assigning a dynamic amount of input tokens to different experts according to their latency. In principle, the faster experts run, the larger amount of input tokens are assigned. Extensive experiments consistently validate the effectiveness of our proposed ShiftAddViT, achieving up to $\textbf{5.18$\times$}$ latency reductions on GPUs and $\textbf{42.9%}$ energy savings, while maintaining comparable accuracy as original or efficient ViTs.