 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPTQT: Quantize Large Language Models Twice to Push the Efficiency
Jul 03, 2024Due to their large size, generative Large Language Models (LLMs) require significant computing and storage resources. This paper introduces a new post-training quantization method, GPTQT, to reduce memory usage and enhance processing speed by expressing the weight of LLM in 3bit/2bit. Practice has shown that minimizing the quantization error of weights is ineffective, leading to overfitting. Therefore, GPTQT employs a progressive two-step approach: initially quantizing weights using Linear quantization to a relatively high bit, followed by converting obtained int weight to lower bit binary coding. A re-explore strategy is proposed to optimize initial scaling factor. During inference, these steps are merged into pure binary coding, enabling efficient computation. Testing across various models and datasets confirms GPTQT's effectiveness. Compared to the strong 3-bit quantization baseline, GPTQT further reduces perplexity by 4.01 on opt-66B and increases speed by 1.24 times on opt-30b. The results on Llama2 show that GPTQT is currently the best binary coding quantization method for such kind of LLMs.
ShiftAddAug: Augment Multiplication-Free Tiny Neural Network with Hybrid Computation
Jul 03, 2024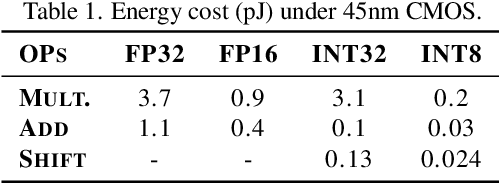
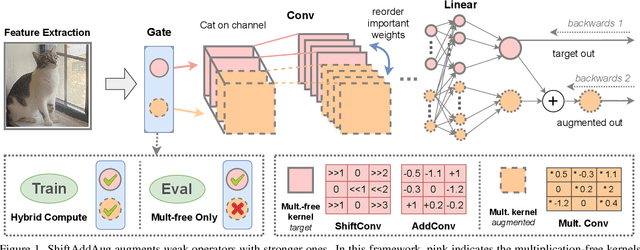
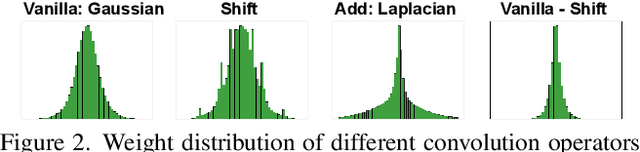

Operators devoid of multiplication, such as Shift and Add, have gained prominence for their compatibility with hardware. However, neural networks (NNs) employing these operators typically exhibit lower accuracy compared to conventional NNs with identical structures. ShiftAddAug uses costly multiplication to augment efficient but less powerful multiplication-free operators, improving performance without any inference overhead. It puts a ShiftAdd tiny NN into a large multiplicative model and encourages it to be trained as a sub-model to obtain additional supervision. In order to solve the weight discrepancy problem between hybrid operators, a new weight sharing method is proposed. Additionally, a novel two stage neural architecture search is used to obtain better augmentation effects for smaller but stronger multiplication-free tiny neural networks. The superiority of ShiftAddAug is validated through experiments in image classification and semantic segmentation, consistently delivering noteworthy enhancements. Remarkably, it secures up to a 4.95% increase in accuracy on the CIFAR100 compared to its directly trained counterparts, even surpassing the performance of multiplicative NNs.
Efficient Fusion and Task Guided Embedding for End-to-end Autonomous Driving
Jul 03, 2024To address the challenges of sensor fusion and safety risk prediction, contemporary closed-loop autonomous driving neural networks leveraging imitation learning typically require a substantial volume of parameters and computational resources to run neural networks. Given the constrained computational capacities of onboard vehicular computers, we introduce a compact yet potent solution named EfficientFuser. This approach employs EfficientViT for visual information extraction and integrates feature maps via cross attention. Subsequently, it utilizes a decoder-only transformer for the amalgamation of multiple features. For prediction purposes, learnable vectors are embedded as tokens to probe the association between the task and sensor features through attention. Evaluated on the CARLA simulation platform, EfficientFuser demonstrates remarkable efficiency, utilizing merely 37.6% of the parameters and 8.7% of the computations compared to the state-of-the-art lightweight method with only 0.4% lower driving score, and the safety score neared that of the leading safety-enhanced method, showcasing its efficacy and potential for practical deployment in autonomous driving systems.
ShiftAddLLM: Accelerating Pretrained LLMs via Post-Training Multiplication-Less Reparameterization
Jun 11, 2024



Large language models (LLMs) have shown impressive performance on language tasks but face challenges when deployed on resource-constrained devices due to their extensive parameters and reliance on dense multiplications, resulting in high memory demands and latency bottlenecks. Shift-and-add reparameterization offers a promising solution by replacing costly multiplications with hardware-friendly primitives in both the attention and multi-layer perceptron (MLP) layers of an LLM. However, current reparameterization techniques require training from scratch or full parameter fine-tuning to restore accuracy, which is resource-intensive for LLMs. To address this, we propose accelerating pretrained LLMs through post-training shift-and-add reparameterization, creating efficient multiplication-free models, dubbed ShiftAddLLM. Specifically, we quantize each weight matrix into binary matrices paired with group-wise scaling factors. The associated multiplications are reparameterized into (1) shifts between activations and scaling factors and (2) queries and adds according to the binary matrices. To reduce accuracy loss, we present a multi-objective optimization method to minimize both weight and output activation reparameterization errors. Additionally, based on varying sensitivity across layers to reparameterization, we develop an automated bit allocation strategy to further reduce memory usage and latency. Experiments on five LLM families and eight tasks consistently validate the effectiveness of ShiftAddLLM, achieving average perplexity improvements of 5.6 and 22.7 points at comparable or lower latency compared to the most competitive quantized LLMs at 3 and 2 bits, respectively, and more than 80% memory and energy reductions over the original LLMs. Codes and models are available at https://github.com/GATECH-EIC/ShiftAddLLM.
ShiftAddViT: Mixture of Multiplication Primitives Towards Efficient Vision Transformer
Jun 10, 2023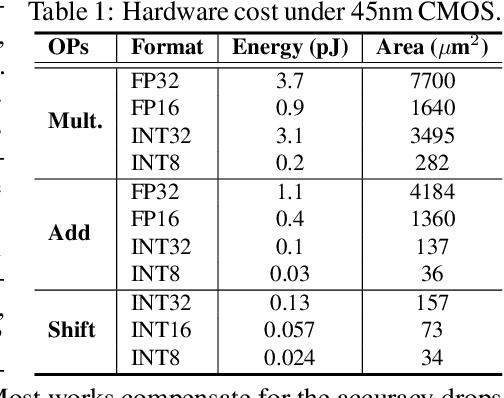
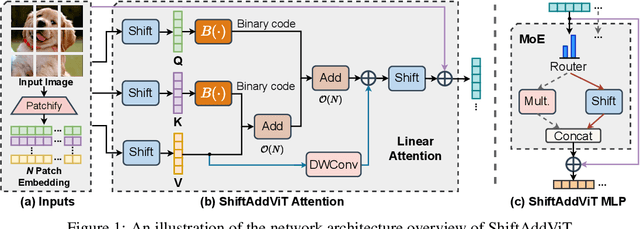

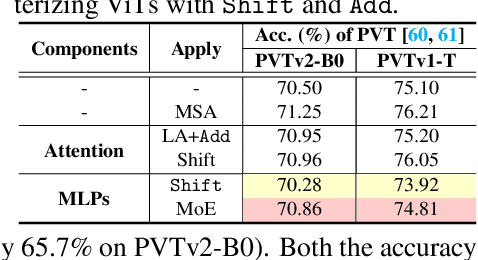
Vision Transformers (ViTs) have shown impressive performance and have become a unified backbone for multiple vision tasks. But both attention and multi-layer perceptions (MLPs) in ViTs are not efficient enough due to dense multiplications, resulting in costly training and inference. To this end, we propose to reparameterize the pre-trained ViT with a mixture of multiplication primitives, e.g., bitwise shifts and additions, towards a new type of multiplication-reduced model, dubbed $\textbf{ShiftAddViT}$, which aims for end-to-end inference speedups on GPUs without the need of training from scratch. Specifically, all $\texttt{MatMuls}$ among queries, keys, and values are reparameterized by additive kernels, after mapping queries and keys to binary codes in Hamming space. The remaining MLPs or linear layers are then reparameterized by shift kernels. We utilize TVM to implement and optimize those customized kernels for practical hardware deployment on GPUs. We find that such a reparameterization on (quadratic or linear) attention maintains model accuracy, while inevitably leading to accuracy drops when being applied to MLPs. To marry the best of both worlds, we further propose a new mixture of experts (MoE) framework to reparameterize MLPs by taking multiplication or its primitives as experts, e.g., multiplication and shift, and designing a new latency-aware load-balancing loss. Such a loss helps to train a generic router for assigning a dynamic amount of input tokens to different experts according to their latency. In principle, the faster experts run, the larger amount of input tokens are assigned. Extensive experiments consistently validate the effectiveness of our proposed ShiftAddViT, achieving up to $\textbf{5.18$\times$}$ latency reductions on GPUs and $\textbf{42.9%}$ energy savings, while maintaining comparable accuracy as original or efficient ViTs.
Control of Pneumatic Artificial Muscles with SNN-based Cerebellar-like Model
Sep 22, 2021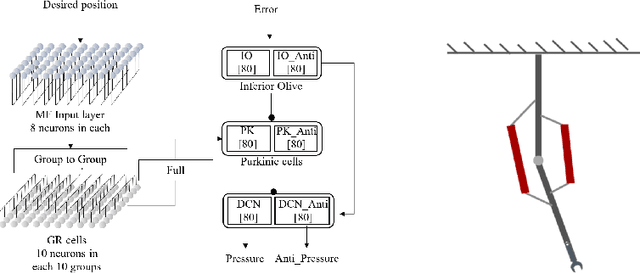
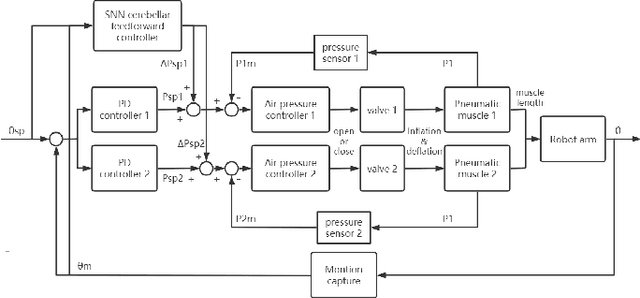
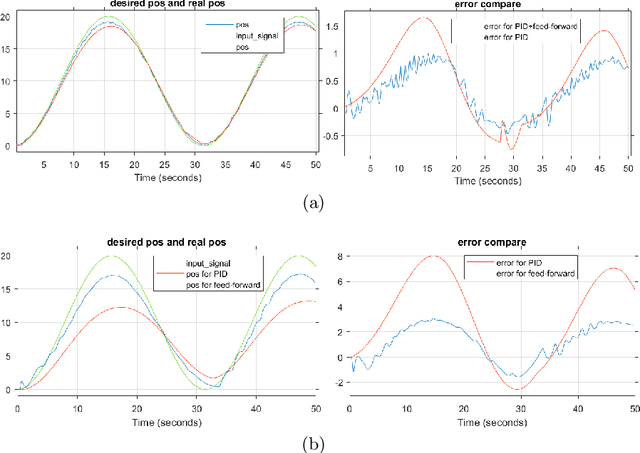
Soft robotics technologies have gained growing interest in recent years, which allows various applications from manufacturing to human-robot interaction. Pneumatic artificial muscle (PAM), a typical soft actuator, has been widely applied to soft robots. The compliance and resilience of soft actuators allow soft robots to behave compliant when interacting with unstructured environments, while the utilization of soft actuators also introduces nonlinearity and uncertainty. Inspired by Cerebellum's vital functions in control of human's physical movement, a neural network model of Cerebellum based on spiking neuron networks (SNNs) is designed. This model is used as a feed-forward controller in controlling a 1-DOF robot arm driven by PAMs. The simulation results show that this Cerebellar-based system achieves good performance and increases the system's response.