 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaQ-DiT: Time-aware Quantization for Diffusion Transformers
Nov 21, 2024Transformer-based diffusion models, dubbed Diffusion Transformers (DiTs), have achieved state-of-the-art performance in image and video generation tasks. However, their large model size and slow inference speed limit their practical applications, calling for model compression methods such as quantization. Unfortunately, existing DiT quantization methods overlook (1) the impact of reconstruction and (2) the varying quantization sensitivities across different layers, which hinder their achievable performance. To tackle these issues, we propose innovative time-aware quantization for DiTs (TaQ-DiT). Specifically, (1) we observe a non-convergence issue when reconstructing weights and activations separately during quantization and introduce a joint reconstruction method to resolve this problem. (2) We discover that Post-GELU activations are particularly sensitive to quantization due to their significant variability across different denoising steps as well as extreme asymmetries and variations within each step. To address this, we propose time-variance-aware transformations to facilitate more effective quantization. Experimental results show that when quantizing DiTs' weights to 4-bit and activations to 8-bit (W4A8), our method significantly surpasses previous quantization methods.
M$^2$-ViT: Accelerating Hybrid Vision Transformers with Two-Level Mixed Quantization
Oct 10, 2024



Although Vision Transformers (ViTs) have achieved significant success, their intensive computations and substantial memory overheads challenge their deployment on edge devices. To address this, efficient ViTs have emerged, typically featuring Convolution-Transformer hybrid architectures to enhance both accuracy and hardware efficiency. While prior work has explored quantization for efficient ViTs to marry the best of efficient hybrid ViT architectures and quantization, it focuses on uniform quantization and overlooks the potential advantages of mixed quantization. Meanwhile, although several works have studied mixed quantization for standard ViTs, they are not directly applicable to hybrid ViTs due to their distinct algorithmic and hardware characteristics. To bridge this gap, we present M$^2$-ViT to accelerate Convolution-Transformer hybrid efficient ViTs with two-level mixed quantization. Specifically, we introduce a hardware-friendly two-level mixed quantization (M$^2$Q) strategy, characterized by both mixed quantization precision and mixed quantization schemes (i.e., uniform and power-of-two), to exploit the architectural properties of efficient ViTs. We further build a dedicated accelerator with heterogeneous computing engines to transform our algorithmic benefits into real hardware improvements. Experimental results validate our effectiveness, showcasing an average of $80\%$ energy-delay product (EDP) saving with comparable quantization accuracy compared to the prior work.
NASH: Neural Architecture and Accelerator Search for Multiplication-Reduced Hybrid Models
Sep 07, 2024
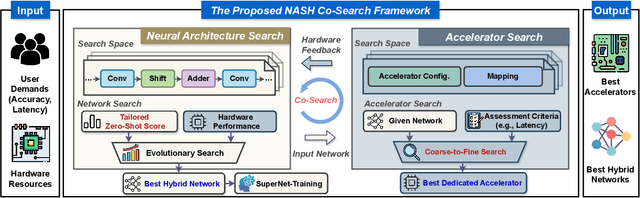


The significant computational cost of multiplications hinders the deployment of deep neural networks (DNNs) on edge devices. While multiplication-free models offer enhanced hardware efficiency, they typically sacrifice accuracy. As a solution, multiplication-reduced hybrid models have emerged to combine the benefits of both approaches. Particularly, prior works, i.e., NASA and NASA-F, leverage Neural Architecture Search (NAS) to construct such hybrid models, enhancing hardware efficiency while maintaining accuracy. However, they either entail costly retraining or encounter gradient conflicts, limiting both search efficiency and accuracy. Additionally, they overlook the acceleration opportunity introduced by accelerator search, yielding sub-optimal hardware performance. To overcome these limitations, we propose NASH, a Neural architecture and Accelerator Search framework for multiplication-reduced Hybrid models. Specifically, as for NAS, we propose a tailored zero-shot metric to pre-identify promising hybrid models before training, enhancing search efficiency while alleviating gradient conflicts. Regarding accelerator search, we innovatively introduce coarse-to-fine search to streamline the search process. Furthermore, we seamlessly integrate these two levels of searches to unveil NASH, obtaining the optimal model and accelerator pairing. Experiments validate our effectiveness, e.g., when compared with the state-of-the-art multiplication-based system, we can achieve $\uparrow$$2.14\times$ throughput and $\uparrow$$2.01\times$ FPS with $\uparrow$$0.25\%$ accuracy on CIFAR-100, and $\uparrow$$1.40\times$ throughput and $\uparrow$$1.19\times$ FPS with $\uparrow$$0.56\%$ accuracy on Tiny-ImageNet. Codes are available at \url{https://github.com/xuyang527/NASH.}
Unveiling and Harnessing Hidden Attention Sinks: Enhancing Large Language Models without Training through Attention Calibration
Jun 22, 2024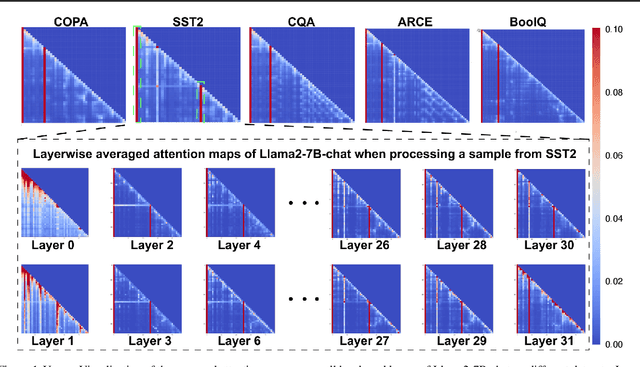
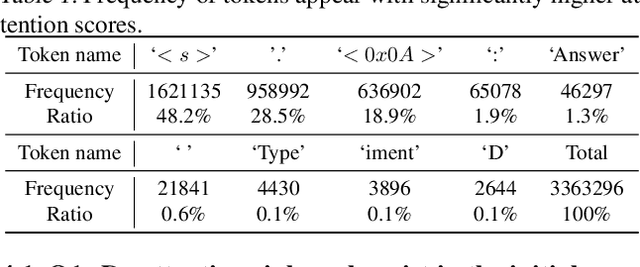
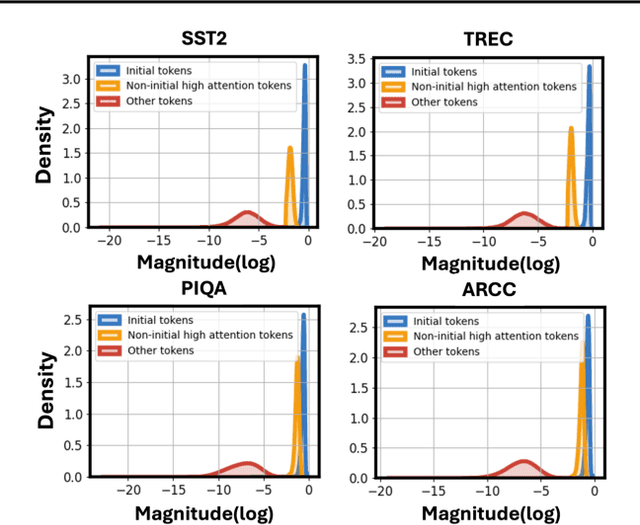
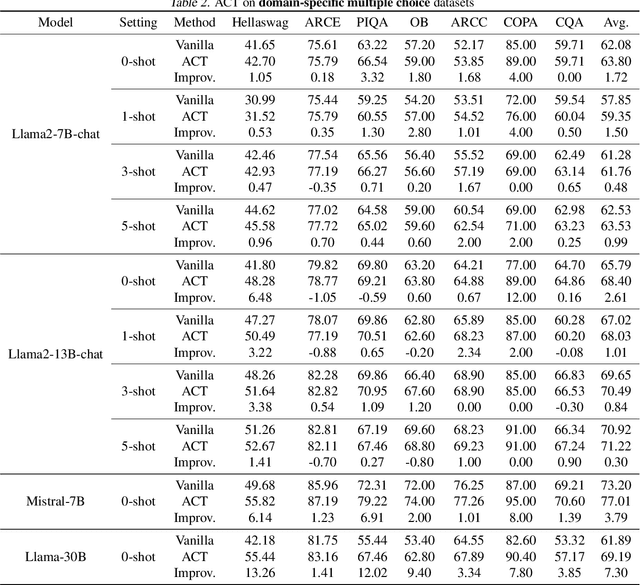
Attention is a fundamental component behind the remarkable achievements of large language models (LLMs). However, our current understanding of the attention mechanism, especially regarding how attention distributions are established, remains limited. Inspired by recent studies that explore the presence of attention sink in the initial token, which receives disproportionately large attention scores despite their lack of semantic importance, this work delves deeper into this phenomenon. We aim to provide a more profound understanding of the existence of attention sinks within LLMs and to uncover ways to enhance the achievable accuracy of LLMs by directly optimizing the attention distributions, without the need for weight finetuning. Specifically, this work begins with comprehensive visualizations of the attention distributions in LLMs during inference across various inputs and tasks. Based on these visualizations, to the best of our knowledge, we are the first to discover that (1) attention sinks occur not only at the start of sequences but also within later tokens of the input, and (2) not all attention sinks have a positive impact on the achievable accuracy of LLMs. Building upon our findings, we propose a training-free Attention Calibration Technique (ACT) that automatically optimizes the attention distributions on the fly during inference in an input-adaptive manner. Extensive experiments validate that ACT consistently enhances the accuracy of various LLMs across different applications. Specifically, ACT achieves an average improvement of up to 7.30% in accuracy across different datasets when applied to Llama-30B. Our code is available at https://github.com/GATECH-EIC/ACT.
ShiftAddLLM: Accelerating Pretrained LLMs via Post-Training Multiplication-Less Reparameterization
Jun 11, 2024



Large language models (LLMs) have shown impressive performance on language tasks but face challenges when deployed on resource-constrained devices due to their extensive parameters and reliance on dense multiplications, resulting in high memory demands and latency bottlenecks. Shift-and-add reparameterization offers a promising solution by replacing costly multiplications with hardware-friendly primitives in both the attention and multi-layer perceptron (MLP) layers of an LLM. However, current reparameterization techniques require training from scratch or full parameter fine-tuning to restore accuracy, which is resource-intensive for LLMs. To address this, we propose accelerating pretrained LLMs through post-training shift-and-add reparameterization, creating efficient multiplication-free models, dubbed ShiftAddLLM. Specifically, we quantize each weight matrix into binary matrices paired with group-wise scaling factors. The associated multiplications are reparameterized into (1) shifts between activations and scaling factors and (2) queries and adds according to the binary matrices. To reduce accuracy loss, we present a multi-objective optimization method to minimize both weight and output activation reparameterization errors. Additionally, based on varying sensitivity across layers to reparameterization, we develop an automated bit allocation strategy to further reduce memory usage and latency. Experiments on five LLM families and eight tasks consistently validate the effectiveness of ShiftAddLLM, achieving average perplexity improvements of 5.6 and 22.7 points at comparable or lower latency compared to the most competitive quantized LLMs at 3 and 2 bits, respectively, and more than 80% memory and energy reductions over the original LLMs. Codes and models are available at https://github.com/GATECH-EIC/ShiftAddLLM.
P$^2$-ViT: Power-of-Two Post-Training Quantization and Acceleration for Fully Quantized Vision Transformer
May 30, 2024Vision Transformers (ViTs) have excelled in computer vision tasks but are memory-consuming and computation-intensive, challenging their deployment on resource-constrained devices. To tackle this limitation, prior works have explored ViT-tailored quantization algorithms but retained floating-point scaling factors, which yield non-negligible re-quantization overhead, limiting ViTs' hardware efficiency and motivating more hardware-friendly solutions. To this end, we propose \emph{P$^2$-ViT}, the first \underline{P}ower-of-Two (PoT) \underline{p}ost-training quantization and acceleration framework to accelerate fully quantized ViTs. Specifically, {as for quantization,} we explore a dedicated quantization scheme to effectively quantize ViTs with PoT scaling factors, thus minimizing the re-quantization overhead. Furthermore, we propose coarse-to-fine automatic mixed-precision quantization to enable better accuracy-efficiency trade-offs. {In terms of hardware,} we develop {a dedicated chunk-based accelerator} featuring multiple tailored sub-processors to individually handle ViTs' different types of operations, alleviating reconfigurable overhead. Additionally, we design {a tailored row-stationary dataflow} to seize the pipeline processing opportunity introduced by our PoT scaling factors, thereby enhancing throughput. Extensive experiments consistently validate P$^2$-ViT's effectiveness. {Particularly, we offer comparable or even superior quantization performance with PoT scaling factors when compared to the counterpart with floating-point scaling factors. Besides, we achieve up to $\mathbf{10.1\times}$ speedup and $\mathbf{36.8\times}$ energy saving over GPU's Turing Tensor Cores, and up to $\mathbf{1.84\times}$ higher computation utilization efficiency against SOTA quantization-based ViT accelerators. Codes are available at \url{https://github.com/shihuihong214/P2-ViT}.
Trio-ViT: Post-Training Quantization and Acceleration for Softmax-Free Efficient Vision Transformer
May 06, 2024



Motivated by the huge success of Transformers in the field of natural language processing (NLP), Vision Transformers (ViTs) have been rapidly developed and achieved remarkable performance in various computer vision tasks. However, their huge model sizes and intensive computations hinder ViTs' deployment on embedded devices, calling for effective model compression methods, such as quantization. Unfortunately, due to the existence of hardware-unfriendly and quantization-sensitive non-linear operations, particularly {Softmax}, it is non-trivial to completely quantize all operations in ViTs, yielding either significant accuracy drops or non-negligible hardware costs. In response to challenges associated with \textit{standard ViTs}, we focus our attention towards the quantization and acceleration for \textit{efficient ViTs}, which not only eliminate the troublesome Softmax but also integrate linear attention with low computational complexity, and propose \emph{Trio-ViT} accordingly. Specifically, at the algorithm level, we develop a {tailored post-training quantization engine} taking the unique activation distributions of Softmax-free efficient ViTs into full consideration, aiming to boost quantization accuracy. Furthermore, at the hardware level, we build an accelerator dedicated to the specific Convolution-Transformer hybrid architecture of efficient ViTs, thereby enhancing hardware efficiency. Extensive experimental results consistently prove the effectiveness of our Trio-ViT framework. {Particularly, we can gain up to $\uparrow$$\mathbf{7.2}\times$ and $\uparrow$$\mathbf{14.6}\times$ FPS under comparable accuracy over state-of-the-art ViT accelerators, as well as $\uparrow$$\mathbf{5.9}\times$ and $\uparrow$$\mathbf{2.0}\times$ DSP efficiency.} Codes will be released publicly upon acceptance.
An FPGA-Based Reconfigurable Accelerator for Convolution-Transformer Hybrid EfficientViT
Mar 29, 2024



Vision Transformers (ViTs) have achieved significant success in computer vision. However, their intensive computations and massive memory footprint challenge ViTs' deployment on embedded devices, calling for efficient ViTs. Among them, EfficientViT, the state-of-the-art one, features a Convolution-Transformer hybrid architecture, enhancing both accuracy and hardware efficiency. Unfortunately, existing accelerators cannot fully exploit the hardware benefits of EfficientViT due to its unique architecture. In this paper, we propose an FPGA-based accelerator for EfficientViT to advance the hardware efficiency frontier of ViTs. Specifically, we design a reconfigurable architecture to efficiently support various operation types, including lightweight convolutions and attention, boosting hardware utilization. Additionally, we present a time-multiplexed and pipelined dataflow to facilitate both intra- and inter-layer fusions, reducing off-chip data access costs. Experimental results show that our accelerator achieves up to 780.2 GOPS in throughput and 105.1 GOPS/W in energy efficiency at 200MHz on the Xilinx ZCU102 FPGA, which significantly outperforms prior works.
A Computationally Efficient Neural Video Compression Accelerator Based on a Sparse CNN-Transformer Hybrid Network
Dec 19, 2023



Video compression is widely used in digital television, surveillance systems, and virtual reality. Real-time video decoding is crucial in practical scenarios. Recently, neural video compression (NVC) combines traditional coding with deep learning, achieving impressive compression efficiency. Nevertheless, the NVC models involve high computational costs and complex memory access patterns, challenging real-time hardware implementations. To relieve this burden, we propose an algorithm and hardware co-design framework named NVCA for video decoding on resource-limited devices. Firstly, a CNN-Transformer hybrid network is developed to improve compression performance by capturing multi-scale non-local features. In addition, we propose a fast algorithm-based sparse strategy that leverages the dual advantages of pruning and fast algorithms, sufficiently reducing computational complexity while maintaining video compression efficiency. Secondly, a reconfigurable sparse computing core is designed to flexibly support sparse convolutions and deconvolutions based on the fast algorithm-based sparse strategy. Furthermore, a novel heterogeneous layer chaining dataflow is incorporated to reduce off-chip memory traffic stemming from extensive inter-frame motion and residual information. Thirdly, the overall architecture of NVCA is designed and synthesized in TSMC 28nm CMOS technology. Extensive experiments demonstrate that our design provides superior coding quality and up to 22.7x decoding speed improvements over other video compression designs. Meanwhile, our design achieves up to 2.2x improvements in energy efficiency compared to prior accelerators.
S2R: Exploring a Double-Win Transformer-Based Framework for Ideal and Blind Super-Resolution
Aug 16, 2023



Nowadays, deep learning based methods have demonstrated impressive performance on ideal super-resolution (SR) datasets, but most of these methods incur dramatically performance drops when directly applied in real-world SR reconstruction tasks with unpredictable blur kernels. To tackle this issue, blind SR methods are proposed to improve the visual results on random blur kernels, which causes unsatisfactory reconstruction effects on ideal low-resolution images similarly. In this paper, we propose a double-win framework for ideal and blind SR task, named S2R, including a light-weight transformer-based SR model (S2R transformer) and a novel coarse-to-fine training strategy, which can achieve excellent visual results on both ideal and random fuzzy conditions. On algorithm level, S2R transformer smartly combines some efficient and light-weight blocks to enhance the representation ability of extracted features with relatively low number of parameters. For training strategy, a coarse-level learning process is firstly performed to improve the generalization of the network with the help of a large-scale external dataset, and then, a fast fine-tune process is developed to transfer the pre-trained model to real-world SR tasks by mining the internal features of the image. Experimental results show that the proposed S2R outperforms other single-image SR models in ideal SR condition with only 578K parameters. Meanwhile, it can achieve better visual results than regular blind SR models in blind fuzzy conditions with only 10 gradient updates, which improve convergence speed by 300 times, significantly accelerating the transfer-learning process in real-world situations.