 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPT-LLM: Exploiting Arbitrary-Precision Tensor Core Computing for LLM Acceleration
Aug 26, 2025Large language models (LLMs) have revolutionized AI applications, yet their enormous computational demands severely limit deployment and real-time performance. Quantization methods can help reduce computational costs, however, attaining the extreme efficiency associated with ultra-low-bit quantized LLMs at arbitrary precision presents challenges on GPUs. This is primarily due to the limited support for GPU Tensor Cores, inefficient memory management, and inflexible kernel optimizations. To tackle these challenges, we propose a comprehensive acceleration scheme for arbitrary precision LLMs, namely APT-LLM. Firstly, we introduce a novel data format, bipolar-INT, which allows for efficient and lossless conversion with signed INT, while also being more conducive to parallel computation. We also develop a matrix multiplication (MatMul) method allowing for arbitrary precision by dismantling and reassembling matrices at the bit level. This method provides flexible precision and optimizes the utilization of GPU Tensor Cores. In addition, we propose a memory management system focused on data recovery, which strategically employs fast shared memory to substantially increase kernel execution speed and reduce memory access latency. Finally, we develop a kernel mapping method that dynamically selects the optimal configurable hyperparameters of kernels for varying matrix sizes, enabling optimal performance across different LLM architectures and precision settings. In LLM inference, APT-LLM achieves up to a 3.99$\times$ speedup compared to FP16 baselines and a 2.16$\times$ speedup over NVIDIA CUTLASS INT4 acceleration on RTX 3090. On RTX 4090 and H800, APT-LLM achieves up to 2.44$\times$ speedup over FP16 and 1.65$\times$ speedup over CUTLASS integer baselines.
FastMamba: A High-Speed and Efficient Mamba Accelerator on FPGA with Accurate Quantization
May 25, 2025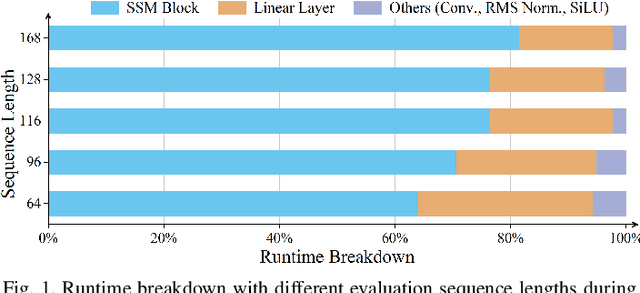
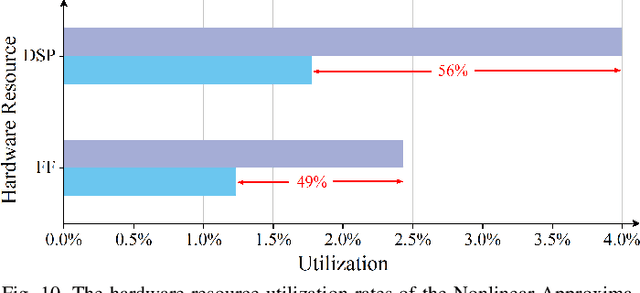
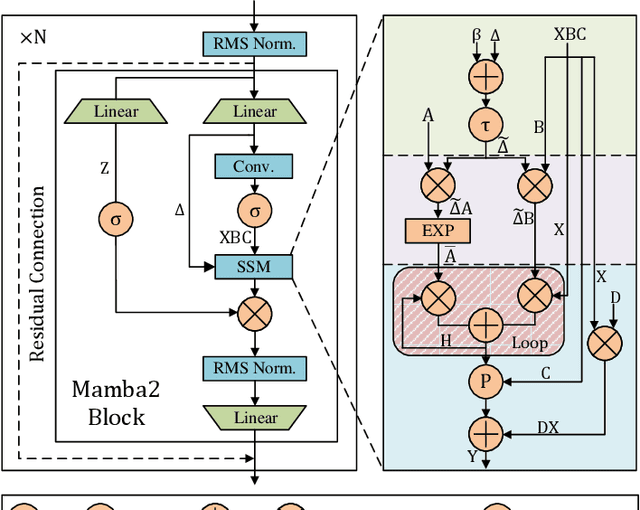
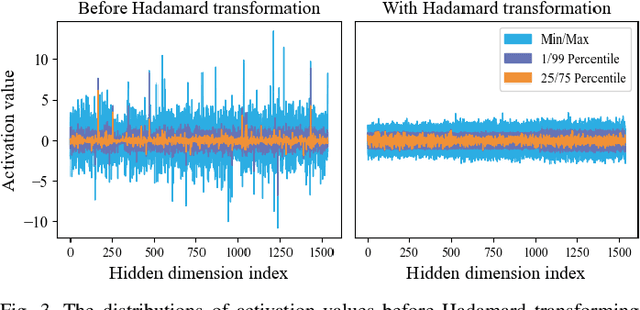
State Space Models (SSMs), like recent Mamba2, have achieved remarkable performance and received extensive attention. However, deploying Mamba2 on resource-constrained edge devices encounters many problems: severe outliers within the linear layer challenging the quantization, diverse and irregular element-wise tensor operations, and hardware-unfriendly nonlinear functions in the SSM block. To address these issues, this paper presents FastMamba, a dedicated accelerator on FPGA with hardware-algorithm co-design to promote the deployment efficiency of Mamba2. Specifically, we successfully achieve 8-bit quantization for linear layers through Hadamard transformation to eliminate outliers. Moreover, a hardware-friendly and fine-grained power-of-two quantization framework is presented for the SSM block and convolution layer, and a first-order linear approximation is developed to optimize the nonlinear functions. Based on the accurate algorithm quantization, we propose an accelerator that integrates parallel vector processing units, pipelined execution dataflow, and an efficient SSM Nonlinear Approximation Unit, which enhances computational efficiency and reduces hardware complexity. Finally, we evaluate FastMamba on Xilinx VC709 FPGA. For the input prefill task on Mamba2-130M, FastMamba achieves 68.80\times and 8.90\times speedup over Intel Xeon 4210R CPU and NVIDIA RTX 3090 GPU, respectively. In the output decode experiment with Mamba2-2.7B, FastMamba attains 6\times higher energy efficiency than RTX 3090 GPU.
Efficient Arbitrary Precision Acceleration for Large Language Models on GPU Tensor Cores
Sep 26, 2024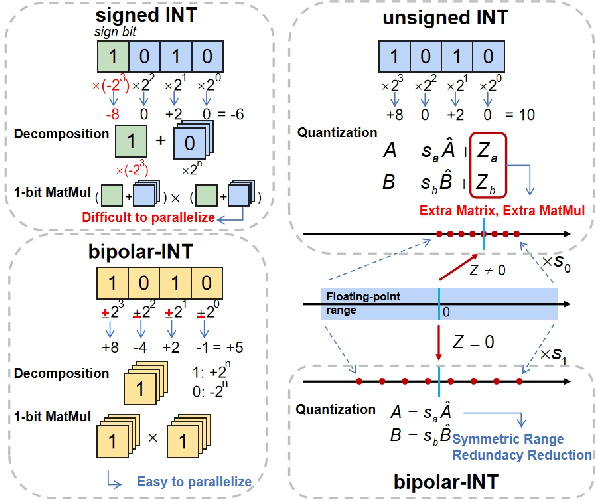
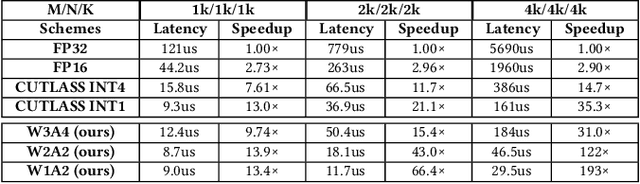
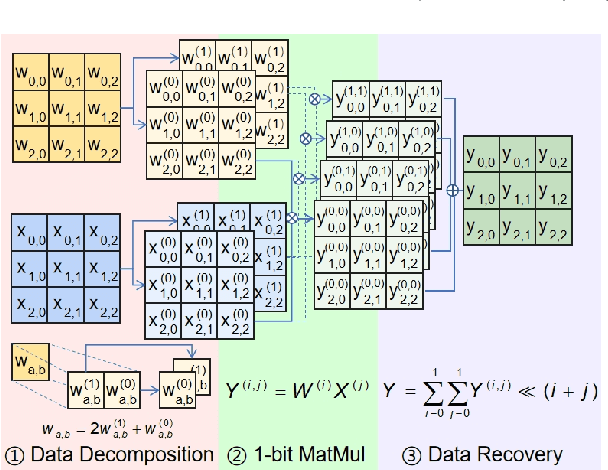
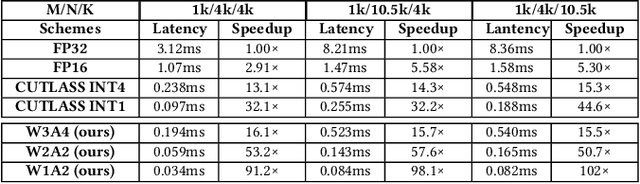
Large language models (LLMs) have been widely applied but face challenges in efficient inference. While quantization methods reduce computational demands, ultra-low bit quantization with arbitrary precision is hindered by limited GPU Tensor Core support and inefficient memory management, leading to suboptimal acceleration. To address these challenges, we propose a comprehensive acceleration scheme for arbitrary precision LLMs. At its core, we introduce a novel bipolar-INT data format that facilitates parallel computing and supports symmetric quantization, effectively reducing data redundancy. Building on this, we implement an arbitrary precision matrix multiplication scheme that decomposes and recovers matrices at the bit level, enabling flexible precision while maximizing GPU Tensor Core utilization. Furthermore, we develop an efficient matrix preprocessing method that optimizes data layout for subsequent computations. Finally, we design a data recovery-oriented memory management system that strategically utilizes fast shared memory, significantly enhancing kernel execution speed and minimizing memory access latency. Experimental results demonstrate our approach's effectiveness, with up to 13\times speedup in matrix multiplication compared to NVIDIA's CUTLASS. When integrated into LLMs, we achieve up to 6.7\times inference acceleration. These improvements significantly enhance LLM inference efficiency, enabling broader and more responsive applications of LLMs.
Co-Designing Binarized Transformer and Hardware Accelerator for Efficient End-to-End Edge Deployment
Jul 16, 2024Transformer models have revolutionized AI tasks, but their large size hinders real-world deployment on resource-constrained and latency-critical edge devices. While binarized Transformers offer a promising solution by significantly reducing model size, existing approaches suffer from algorithm-hardware mismatches with limited co-design exploration, leading to suboptimal performance on edge devices. Hence, we propose a co-design method for efficient end-to-end edge deployment of Transformers from three aspects: algorithm, hardware, and joint optimization. First, we propose BMT, a novel hardware-friendly binarized Transformer with optimized quantization methods and components, and we further enhance its model accuracy by leveraging the weighted ternary weight splitting training technique. Second, we develop a streaming processor mixed binarized Transformer accelerator, namely BAT, which is equipped with specialized units and scheduling pipelines for efficient inference of binarized Transformers. Finally, we co-optimize the algorithm and hardware through a design space exploration approach to achieve a global trade-off between accuracy, latency, and robustness for real-world deployments. Experimental results show our co-design achieves up to 2.14-49.37x throughput gains and 3.72-88.53x better energy efficiency over state-of-the-art Transformer accelerators, enabling efficient end-to-end edge deployment.
Trio-ViT: Post-Training Quantization and Acceleration for Softmax-Free Efficient Vision Transformer
May 06, 2024



Motivated by the huge success of Transformers in the field of natural language processing (NLP), Vision Transformers (ViTs) have been rapidly developed and achieved remarkable performance in various computer vision tasks. However, their huge model sizes and intensive computations hinder ViTs' deployment on embedded devices, calling for effective model compression methods, such as quantization. Unfortunately, due to the existence of hardware-unfriendly and quantization-sensitive non-linear operations, particularly {Softmax}, it is non-trivial to completely quantize all operations in ViTs, yielding either significant accuracy drops or non-negligible hardware costs. In response to challenges associated with \textit{standard ViTs}, we focus our attention towards the quantization and acceleration for \textit{efficient ViTs}, which not only eliminate the troublesome Softmax but also integrate linear attention with low computational complexity, and propose \emph{Trio-ViT} accordingly. Specifically, at the algorithm level, we develop a {tailored post-training quantization engine} taking the unique activation distributions of Softmax-free efficient ViTs into full consideration, aiming to boost quantization accuracy. Furthermore, at the hardware level, we build an accelerator dedicated to the specific Convolution-Transformer hybrid architecture of efficient ViTs, thereby enhancing hardware efficiency. Extensive experimental results consistently prove the effectiveness of our Trio-ViT framework. {Particularly, we can gain up to $\uparrow$$\mathbf{7.2}\times$ and $\uparrow$$\mathbf{14.6}\times$ FPS under comparable accuracy over state-of-the-art ViT accelerators, as well as $\uparrow$$\mathbf{5.9}\times$ and $\uparrow$$\mathbf{2.0}\times$ DSP efficiency.} Codes will be released publicly upon acceptance.
An FPGA-Based Reconfigurable Accelerator for Convolution-Transformer Hybrid EfficientViT
Mar 29, 2024



Vision Transformers (ViTs) have achieved significant success in computer vision. However, their intensive computations and massive memory footprint challenge ViTs' deployment on embedded devices, calling for efficient ViTs. Among them, EfficientViT, the state-of-the-art one, features a Convolution-Transformer hybrid architecture, enhancing both accuracy and hardware efficiency. Unfortunately, existing accelerators cannot fully exploit the hardware benefits of EfficientViT due to its unique architecture. In this paper, we propose an FPGA-based accelerator for EfficientViT to advance the hardware efficiency frontier of ViTs. Specifically, we design a reconfigurable architecture to efficiently support various operation types, including lightweight convolutions and attention, boosting hardware utilization. Additionally, we present a time-multiplexed and pipelined dataflow to facilitate both intra- and inter-layer fusions, reducing off-chip data access costs. Experimental results show that our accelerator achieves up to 780.2 GOPS in throughput and 105.1 GOPS/W in energy efficiency at 200MHz on the Xilinx ZCU102 FPGA, which significantly outperforms prior works.