 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPTQT: Quantize Large Language Models Twice to Push the Efficiency
Jul 03, 2024Due to their large size, generative Large Language Models (LLMs) require significant computing and storage resources. This paper introduces a new post-training quantization method, GPTQT, to reduce memory usage and enhance processing speed by expressing the weight of LLM in 3bit/2bit. Practice has shown that minimizing the quantization error of weights is ineffective, leading to overfitting. Therefore, GPTQT employs a progressive two-step approach: initially quantizing weights using Linear quantization to a relatively high bit, followed by converting obtained int weight to lower bit binary coding. A re-explore strategy is proposed to optimize initial scaling factor. During inference, these steps are merged into pure binary coding, enabling efficient computation. Testing across various models and datasets confirms GPTQT's effectiveness. Compared to the strong 3-bit quantization baseline, GPTQT further reduces perplexity by 4.01 on opt-66B and increases speed by 1.24 times on opt-30b. The results on Llama2 show that GPTQT is currently the best binary coding quantization method for such kind of LLMs.
ShiftAddAug: Augment Multiplication-Free Tiny Neural Network with Hybrid Computation
Jul 03, 2024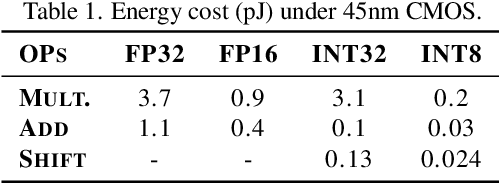
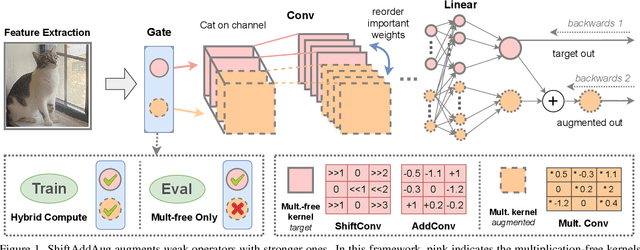
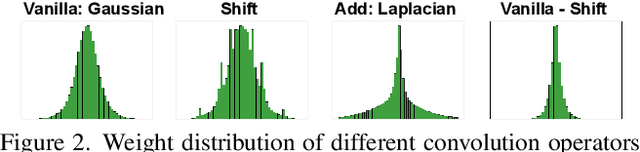

Operators devoid of multiplication, such as Shift and Add, have gained prominence for their compatibility with hardware. However, neural networks (NNs) employing these operators typically exhibit lower accuracy compared to conventional NNs with identical structures. ShiftAddAug uses costly multiplication to augment efficient but less powerful multiplication-free operators, improving performance without any inference overhead. It puts a ShiftAdd tiny NN into a large multiplicative model and encourages it to be trained as a sub-model to obtain additional supervision. In order to solve the weight discrepancy problem between hybrid operators, a new weight sharing method is proposed. Additionally, a novel two stage neural architecture search is used to obtain better augmentation effects for smaller but stronger multiplication-free tiny neural networks. The superiority of ShiftAddAug is validated through experiments in image classification and semantic segmentation, consistently delivering noteworthy enhancements. Remarkably, it secures up to a 4.95% increase in accuracy on the CIFAR100 compared to its directly trained counterparts, even surpassing the performance of multiplicative NNs.
Efficient Fusion and Task Guided Embedding for End-to-end Autonomous Driving
Jul 03, 2024To address the challenges of sensor fusion and safety risk prediction, contemporary closed-loop autonomous driving neural networks leveraging imitation learning typically require a substantial volume of parameters and computational resources to run neural networks. Given the constrained computational capacities of onboard vehicular computers, we introduce a compact yet potent solution named EfficientFuser. This approach employs EfficientViT for visual information extraction and integrates feature maps via cross attention. Subsequently, it utilizes a decoder-only transformer for the amalgamation of multiple features. For prediction purposes, learnable vectors are embedded as tokens to probe the association between the task and sensor features through attention. Evaluated on the CARLA simulation platform, EfficientFuser demonstrates remarkable efficiency, utilizing merely 37.6% of the parameters and 8.7% of the computations compared to the state-of-the-art lightweight method with only 0.4% lower driving score, and the safety score neared that of the leading safety-enhanced method, showcasing its efficacy and potential for practical deployment in autonomous driving systems.