 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Mixture of Experts: Generalizable Learning for High-Level Synthesis
Oct 25, 2024



High-level synthesis (HLS) is a widely used tool in designing Field Programmable Gate Array (FPGA). HLS enables FPGA design with software programming languages by compiling the source code into an FPGA circuit. The source code includes a program (called ``kernel'') and several pragmas that instruct hardware synthesis, such as parallelization, pipeline, etc. While it is relatively easy for software developers to design the program, it heavily relies on hardware knowledge to design the pragmas, posing a big challenge for software developers. Recently, different machine learning algorithms, such as GNNs, have been proposed to automate the pragma design via performance prediction. However, when applying the trained model on new kernels, the significant domain shift often leads to unsatisfactory performance. We propose a more domain-generalizable model structure: a two-level hierarchical Mixture of Experts (MoE), that can be flexibly adapted to any GNN model. Different expert networks can learn to deal with different regions in the representation space, and they can utilize similar patterns between the old kernels and new kernels. In the low-level MoE, we apply MoE on three natural granularities of a program: node, basic block, and graph. The high-level MoE learns to aggregate the three granularities for the final decision. To stably train the hierarchical MoE, we further propose a two-stage training method. Extensive experiments verify the effectiveness of the hierarchical MoE.
A Survey on Graph Neural Network Acceleration: Algorithms, Systems, and Customized Hardware
Jun 24, 2023
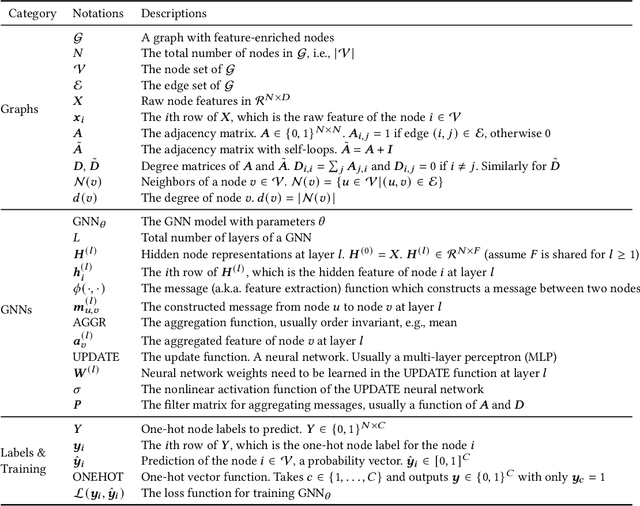
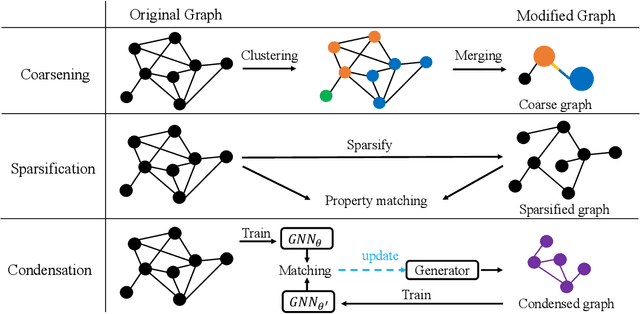

Graph neural networks (GNNs) are emerging for machine learning research on graph-structured data. GNNs achieve state-of-the-art performance on many tasks, but they face scalability challenges when it comes to real-world applications that have numerous data and strict latency requirements. Many studies have been conducted on how to accelerate GNNs in an effort to address these challenges. These acceleration techniques touch on various aspects of the GNN pipeline, from smart training and inference algorithms to efficient systems and customized hardware. As the amount of research on GNN acceleration has grown rapidly, there lacks a systematic treatment to provide a unified view and address the complexity of relevant works. In this survey, we provide a taxonomy of GNN acceleration, review the existing approaches, and suggest future research directions. Our taxonomic treatment of GNN acceleration connects the existing works and sets the stage for further development in this area.
ProgSG: Cross-Modality Representation Learning for Programs in Electronic Design Automation
May 18, 2023



Recent years have witnessed the growing popularity of domain-specific accelerators (DSAs), such as Google's TPUs, for accelerating various applications such as deep learning, search, autonomous driving, etc. To facilitate DSA designs, high-level synthesis (HLS) is used, which allows a developer to compile a high-level description in the form of software code in C and C++ into a design in low-level hardware description languages (such as VHDL or Verilog) and eventually synthesized into a DSA on an ASIC (application-specific integrated circuit) or FPGA (field-programmable gate arrays). However, existing HLS tools still require microarchitecture decisions, expressed in terms of pragmas (such as directives for parallelization and pipelining). To enable more people to design DSAs, it is desirable to automate such decisions with the help of deep learning for predicting the quality of HLS designs. This requires us a deeper understanding of the program, which is a combination of original code and pragmas. Naturally, these programs can be considered as sequence data, for which large language models (LLM) can help. In addition, these programs can be compiled and converted into a control data flow graph (CDFG), and the compiler also provides fine-grained alignment between the code tokens and the CDFG nodes. However, existing works either fail to leverage both modalities or combine the two in shallow or coarse ways. We propose ProgSG allowing the source code sequence modality and the graph modalities to interact with each other in a deep and fine-grained way. To alleviate the scarcity of labeled designs, a pre-training method is proposed based on a suite of compiler's data flow analysis tasks. Experimental results on two benchmark datasets show the superiority of ProgSG over baseline methods that either only consider one modality or combine the two without utilizing the alignment information.
Enabling Automated FPGA Accelerator Optimization Using Graph Neural Networks
Nov 22, 2021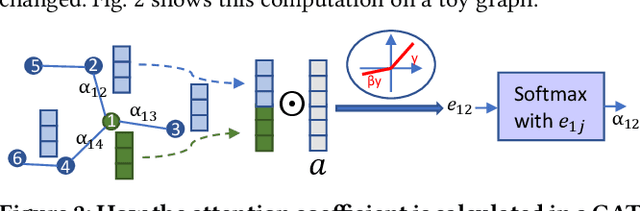

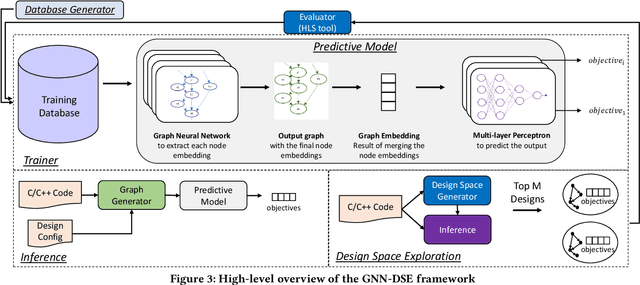

High-level synthesis (HLS) has freed the computer architects from developing their designs in a very low-level language and needing to exactly specify how the data should be transferred in register-level. With the help of HLS, the hardware designers must describe only a high-level behavioral flow of the design. Despite this, it still can take weeks to develop a high-performance architecture mainly because there are many design choices at a higher level that requires more time to explore. It also takes several minutes to hours to get feedback from the HLS tool on the quality of each design candidate. In this paper, we propose to solve this problem by modeling the HLS tool with a graph neural network (GNN) that is trained to be used for a wide range of applications. The experimental results demonstrate that by employing the GNN-based model, we are able to estimate the quality of design in milliseconds with high accuracy which can help us search through the solution space very quickly.
SPA-GCN: Efficient and Flexible GCN Accelerator with an Application for Graph Similarity Computation
Nov 10, 2021
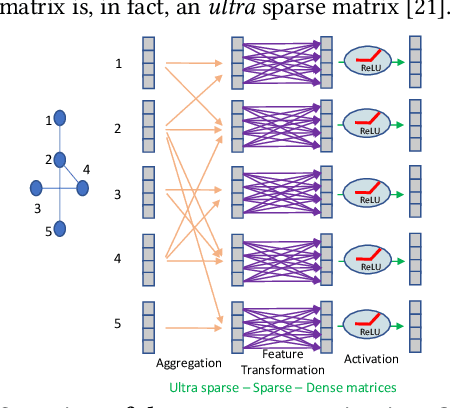

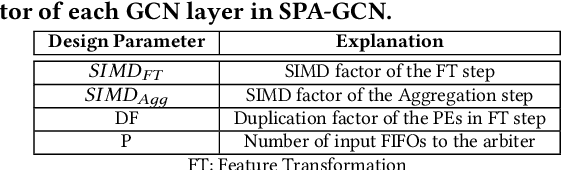
While there have been many studies on hardware acceleration for deep learning on images, there has been a rather limited focus on accelerating deep learning applications involving graphs. The unique characteristics of graphs, such as the irregular memory access and dynamic parallelism, impose several challenges when the algorithm is mapped to a CPU or GPU. To address these challenges while exploiting all the available sparsity, we propose a flexible architecture called SPA-GCN for accelerating Graph Convolutional Networks (GCN), the core computation unit in deep learning algorithms on graphs. The architecture is specialized for dealing with many small graphs since the graph size has a significant impact on design considerations. In this context, we use SimGNN, a neural-network-based graph matching algorithm, as a case study to demonstrate the effectiveness of our architecture. The experimental results demonstrate that SPA-GCN can deliver a high speedup compared to a multi-core CPU implementation and a GPU implementation, showing the efficiency of our design.