 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPinRec: Unifying Generative Retrieval and Ranking at Pinterest Scale
May 29, 2026Modern recommendation systems predominantly train retrieval and ranking as separate models despite both increasingly relying on large transformers encoding the same user behavior data, duplicating parameters, compute, and serving cost. Prior work unifies the model architecture but not the full pipeline: input formats, training procedures, and serving stacks remain fragmented across stages. We present UniPinRec, which achieves full-stack unification of retrieval and ranking at Pinterest: one input format, one model, one training stage, deployed within existing serving infrastructure. A shared transformer encodes the user action sequence into candidate-independent representations that branch into retrieval (ANN dot-product) and ranking (cross-attention) via task-specific heads. Three ideas make this work: (1) Masked Action Modeling (MAM) eliminates interleaving, enabling weight sharing without doubling context length; (2) Blended training examples pair action sequences with feedview impression slates to satisfy both objectives jointly; (3) Cross-stage KV cache sharing reuses user-history computation from retrieval for ranking, reducing total FLOPs versus serving two independent models. Deployed in the Pinterest core surfaces, UniPinRec delivers approximately +1% online engagement lift while cutting end-to-end serving latency by 11.1% and lifting QPS by 63.6%. To our knowledge, this is the first full-stack unification of retrieval and ranking, covering inputs, model, training and serving, deployed in a production recommendation system.
ConFu: Contemplate the Future for Better Speculative Sampling
Mar 09, 2026Speculative decoding has emerged as a powerful approach to accelerate large language model (LLM) inference by employing lightweight draft models to propose candidate tokens that are subsequently verified by the target model. The effectiveness of this paradigm critically depends on the quality of the draft model. While recent advances such as the EAGLE series achieve state-of-the-art speedup, existing draft models remain limited by error accumulation: they condition only on the current prefix, causing their predictions to drift from the target model over steps. In this work, we propose \textbf{ConFu} (Contemplate the Future), a novel speculative decoding framework that enables draft models to anticipate the future direction of generation. ConFu introduces (i) contemplate tokens and soft prompts that allow the draft model to leverage future-oriented signals from the target model at negligible cost, (ii) a dynamic contemplate token mechanism with MoE to enable context-aware future prediction, and (iii) a training framework with anchor token sampling and future prediction replication that learns robust future prediction. Experiments demonstrate that ConFu improves token acceptance rates and generation speed over EAGLE-3 by 8--11% across various downstream tasks with Llama-3 3B and 8B models. We believe our work is the first to bridge speculative decoding with continuous reasoning tokens, offering a new direction for accelerating LLM inference.
STree: Speculative Tree Decoding for Hybrid State-Space Models
May 20, 2025



Speculative decoding is a technique to leverage hardware concurrency to improve the efficiency of large-scale autoregressive (AR) Transformer models by enabling multiple steps of token generation in a single forward pass. State-space models (SSMs) are already more efficient than AR Transformers, since their state summarizes all past data with no need to cache or re-process tokens in the sliding window context. However, their state can also comprise thousands of tokens; so, speculative decoding has recently been extended to SSMs. Existing approaches, however, do not leverage the tree-based verification methods, since current SSMs lack the means to compute a token tree efficiently. We propose the first scalable algorithm to perform tree-based speculative decoding in state-space models (SSMs) and hybrid architectures of SSMs and Transformer layers. We exploit the structure of accumulated state transition matrices to facilitate tree-based speculative decoding with minimal overhead to current SSM state update implementations. With the algorithm, we describe a hardware-aware implementation that improves naive application of AR Transformer tree-based speculative decoding methods to SSMs. Furthermore, we outperform vanilla speculative decoding with SSMs even with a baseline drafting model and tree structure on three different benchmarks, opening up opportunities for further speed up with SSM and hybrid model inference. Code will be released upon paper acceptance.
Heuristic Methods are Good Teachers to Distill MLPs for Graph Link Prediction
Apr 08, 2025



Link prediction is a crucial graph-learning task with applications including citation prediction and product recommendation. Distilling Graph Neural Networks (GNNs) teachers into Multi-Layer Perceptrons (MLPs) students has emerged as an effective approach to achieve strong performance and reducing computational cost by removing graph dependency. However, existing distillation methods only use standard GNNs and overlook alternative teachers such as specialized model for link prediction (GNN4LP) and heuristic methods (e.g., common neighbors). This paper first explores the impact of different teachers in GNN-to-MLP distillation. Surprisingly, we find that stronger teachers do not always produce stronger students: MLPs distilled from GNN4LP can underperform those distilled from simpler GNNs, while weaker heuristic methods can teach MLPs to near-GNN performance with drastically reduced training costs. Building on these insights, we propose Ensemble Heuristic-Distilled MLPs (EHDM), which eliminates graph dependencies while effectively integrating complementary signals via a gating mechanism. Experiments on ten datasets show an average 7.93% improvement over previous GNN-to-MLP approaches with 1.95-3.32 times less training time, indicating EHDM is an efficient and effective link prediction method.
Hierarchical Mixture of Experts: Generalizable Learning for High-Level Synthesis
Oct 25, 2024



High-level synthesis (HLS) is a widely used tool in designing Field Programmable Gate Array (FPGA). HLS enables FPGA design with software programming languages by compiling the source code into an FPGA circuit. The source code includes a program (called ``kernel'') and several pragmas that instruct hardware synthesis, such as parallelization, pipeline, etc. While it is relatively easy for software developers to design the program, it heavily relies on hardware knowledge to design the pragmas, posing a big challenge for software developers. Recently, different machine learning algorithms, such as GNNs, have been proposed to automate the pragma design via performance prediction. However, when applying the trained model on new kernels, the significant domain shift often leads to unsatisfactory performance. We propose a more domain-generalizable model structure: a two-level hierarchical Mixture of Experts (MoE), that can be flexibly adapted to any GNN model. Different expert networks can learn to deal with different regions in the representation space, and they can utilize similar patterns between the old kernels and new kernels. In the low-level MoE, we apply MoE on three natural granularities of a program: node, basic block, and graph. The high-level MoE learns to aggregate the three granularities for the final decision. To stably train the hierarchical MoE, we further propose a two-stage training method. Extensive experiments verify the effectiveness of the hierarchical MoE.
Dynamic-Width Speculative Beam Decoding for Efficient LLM Inference
Sep 25, 2024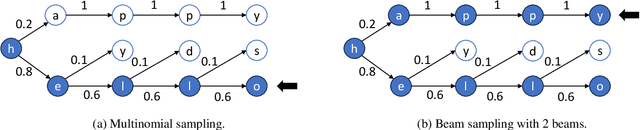
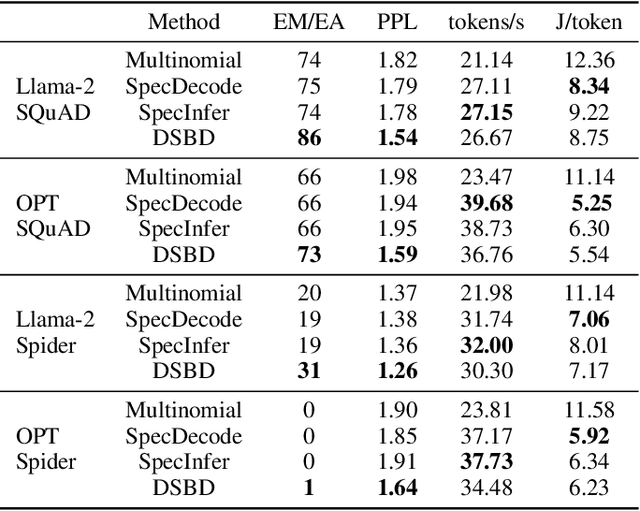
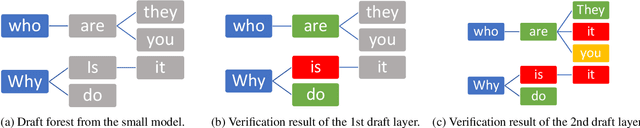
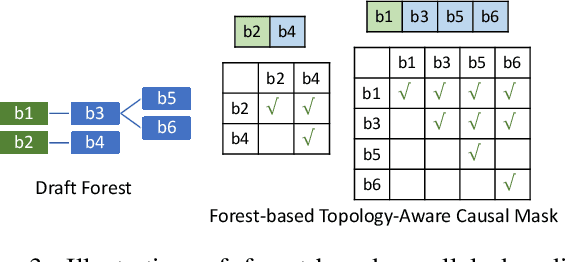
Large language models (LLMs) have shown outstanding performance across numerous real-world tasks. However, the autoregressive nature of these models makes the inference process slow and costly. Speculative decoding has emerged as a promising solution, leveraging a smaller auxiliary model to draft future tokens, which are then validated simultaneously by the larger model, achieving a speed-up of 1-2x. Although speculative decoding matches the same distribution as multinomial sampling, multinomial sampling itself is prone to suboptimal outputs, whereas beam sampling is widely recognized for producing higher-quality results by maintaining multiple candidate sequences at each step. This paper explores the novel integration of speculative decoding with beam sampling. However, there are four key challenges: (1) how to generate multiple sequences from the larger model's distribution given drafts sequences from the small model; (2) how to dynamically optimize the number of beams to balance efficiency and accuracy; (3) how to efficiently verify the multiple drafts in parallel; and (4) how to address the extra memory costs inherent in beam sampling. To address these challenges, we propose dynamic-width speculative beam decoding (DSBD). Specifically, we first introduce a novel draft and verification scheme that generates multiple sequences following the large model's distribution based on beam sampling trajectories from the small model. Then, we introduce an adaptive mechanism to dynamically tune the number of beams based on the context, optimizing efficiency and effectiveness. Besides, we extend tree-based parallel verification to handle multiple trees simultaneously, accelerating the verification process. Finally, we illustrate a simple modification to our algorithm to mitigate the memory overhead of beam sampling...
Relational Database Augmented Large Language Model
Jul 21, 2024



Large language models (LLMs) excel in many natural language processing (NLP) tasks. However, since LLMs can only incorporate new knowledge through training or supervised fine-tuning processes, they are unsuitable for applications that demand precise, up-to-date, and private information not available in the training corpora. This precise, up-to-date, and private information is typically stored in relational databases. Thus, a promising solution is to augment LLMs with the inclusion of relational databases as external memory. This can ensure the timeliness, correctness, and consistency of data, and assist LLMs in performing complex arithmetic operations beyond their inherent capabilities. However, bridging the gap between LLMs and relational databases is challenging. It requires the awareness of databases and data values stored in databases to select correct databases and issue correct SQL queries. Besides, it is necessary for the external memory to be independent of the LLM to meet the needs of real-world applications. We introduce a novel LLM-agnostic memory architecture comprising a database selection memory, a data value memory, and relational databases. And we design an elegant pipeline to retrieve information from it. Besides, we carefully design the prompts to instruct the LLM to maximize the framework's potential. To evaluate our method, we compose a new dataset with various types of questions. Experimental results show that our framework enables LLMs to effectively answer database-related questions, which is beyond their direct ability.
Multi-Token Joint Speculative Decoding for Accelerating Large Language Model Inference
Jul 12, 2024



Transformer-based Large language models (LLMs) have demonstrated their power in various tasks, but their inference incurs significant time and energy costs. To accelerate LLM inference, speculative decoding uses a smaller model to propose one sequence of tokens, which are subsequently validated in batch by the target large model. Compared with autoregressive decoding, speculative decoding generates the same number of tokens with fewer runs of the large model, hence accelerating the overall inference by $1$-$2\times$. However, greedy decoding is not the optimal decoding algorithm in terms of output perplexity, which is a direct measurement of the effectiveness of a decoding algorithm. An algorithm that has better output perplexity and even better efficiency than speculative decoding can be more useful in practice. To achieve this seemingly contradictory goal, we first introduce multi-token joint greedy decoding (MJGD), which greedily generates multiple tokens at each step based on their joint perplexity. We show that it leads to better perplexity for the whole output. But the computation cost of MJGD is infeasible in practice. So we further propose multi-token joint speculative decoding (MJSD), which approximates and accelerates the MJGD from two aspects: it approximates the joint distribution of the large model with that of a small model, and uses a verification step to guarantee the accuracy of approximation; then it uses beam decoding to accelerate the sequence generation from the joint distribution. Compared with vanilla speculative decoding, MJSD has two advantages: (1) it is an approximation of MJGD, thus achieving better output perplexity; (2) verification with joint likelihood allows it to accept the longest prefix sub-sequence of the draft tokens with valid perplexity, leading to better efficiency...
Cross-Modality Program Representation Learning for Electronic Design Automation with High-Level Synthesis
Jun 13, 2024In recent years, domain-specific accelerators (DSAs) have gained popularity for applications such as deep learning and autonomous driving. To facilitate DSA designs, programmers use high-level synthesis (HLS) to compile a high-level description written in C/C++ into a design with low-level hardware description languages that eventually synthesize DSAs on circuits. However, creating a high-quality HLS design still demands significant domain knowledge, particularly in microarchitecture decisions expressed as \textit{pragmas}. Thus, it is desirable to automate such decisions with the help of machine learning for predicting the quality of HLS designs, requiring a deeper understanding of the program that consists of original code and pragmas. Naturally, these programs can be considered as sequence data. In addition, these programs can be compiled and converted into a control data flow graph (CDFG). But existing works either fail to leverage both modalities or combine the two in shallow or coarse ways. We propose ProgSG, a model that allows interaction between the source code sequence modality and the graph modality in a deep and fine-grained way. To alleviate the scarcity of labeled designs, a pre-training method is proposed based on a suite of compiler's data flow analysis tasks. Experimental results show that ProgSG reduces the RMSE of design performance predictions by up to $22\%$, and identifies designs with an average of $1.10\times$ and $1.26\times$ (up to $8.17\times$ and $13.31\times$) performance improvement in design space exploration (DSE) task compared to HARP and AutoDSE, respectively.
HMT: Hierarchical Memory Transformer for Long Context Language Processing
May 09, 2024Transformer-based large language models (LLM) have been widely used in language processing applications. However, most of them restrict the context window that permits the model to attend to every token in the inputs. Previous works in recurrent models can memorize past tokens to enable unlimited context and maintain effectiveness. However, they have "flat" memory architectures, which have limitations in selecting and filtering information. Since humans are good at learning and self-adjustment, we speculate that imitating brain memory hierarchy is beneficial for model memorization. We propose the Hierarchical Memory Transformer (HMT), a novel framework that enables and improves models' long-context processing ability by imitating human memorization behavior. Leveraging memory-augmented segment-level recurrence, we organize the memory hierarchy by preserving tokens from early input token segments, passing memory embeddings along the sequence, and recalling relevant information from history. Evaluating general language modeling (Wikitext-103, PG-19) and question-answering tasks (PubMedQA), we show that HMT steadily improves the long-context processing ability of context-constrained and long-context models. With an additional 0.5% - 2% of parameters, HMT can easily plug in and augment future LLMs to handle long context effectively. Our code is open-sourced on Github: https://github.com/OswaldHe/HMT-pytorch.