 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIFT: LLM-Based Pragma Insertion for HLS via GNN Supervised Fine-Tuning
Apr 29, 2025
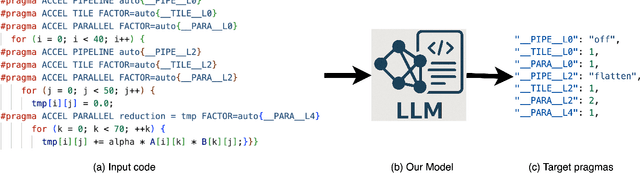
FPGAs are increasingly adopted in datacenter environments for their reconfigurability and energy efficiency. High-Level Synthesis (HLS) tools have eased FPGA programming by raising the abstraction level from RTL to untimed C/C++, yet attaining high performance still demands expert knowledge and iterative manual insertion of optimization pragmas to modify the microarchitecture. To address this challenge, we propose LIFT, a large language model (LLM)-based coding assistant for HLS that automatically generates performance-critical pragmas given a C/C++ design. We fine-tune the LLM by tightly integrating and supervising the training process with a graph neural network (GNN), combining the sequential modeling capabilities of LLMs with the structural and semantic understanding of GNNs necessary for reasoning over code and its control/data dependencies. On average, LIFT produces designs that improve performance by 3.52x and 2.16x than prior state-of the art AutoDSE and HARP respectively, and 66x than GPT-4o.
Dynamic-Width Speculative Beam Decoding for Efficient LLM Inference
Sep 25, 2024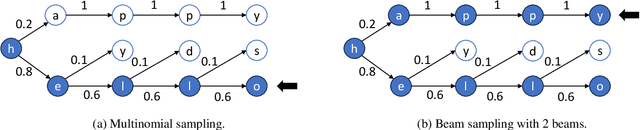
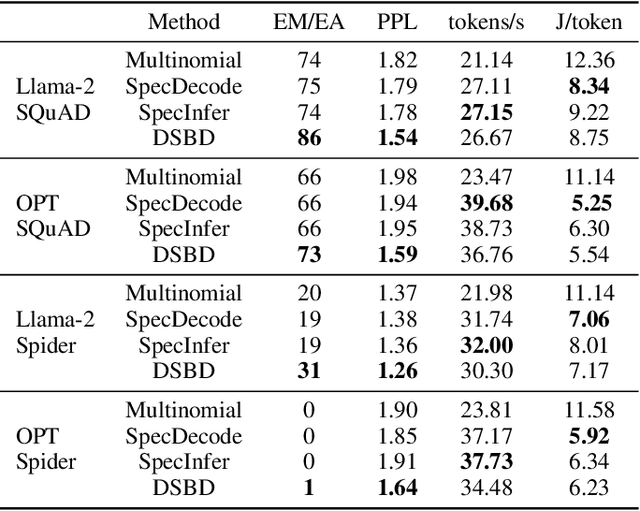
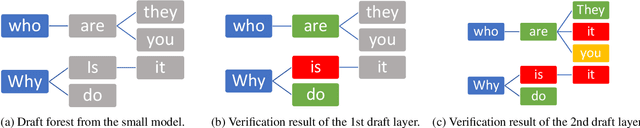
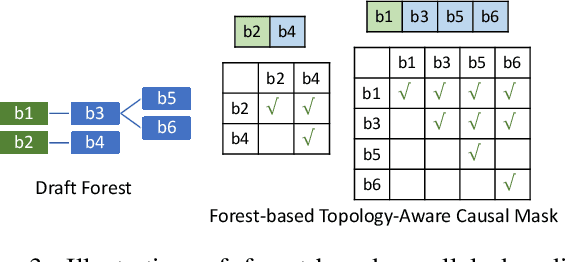
Large language models (LLMs) have shown outstanding performance across numerous real-world tasks. However, the autoregressive nature of these models makes the inference process slow and costly. Speculative decoding has emerged as a promising solution, leveraging a smaller auxiliary model to draft future tokens, which are then validated simultaneously by the larger model, achieving a speed-up of 1-2x. Although speculative decoding matches the same distribution as multinomial sampling, multinomial sampling itself is prone to suboptimal outputs, whereas beam sampling is widely recognized for producing higher-quality results by maintaining multiple candidate sequences at each step. This paper explores the novel integration of speculative decoding with beam sampling. However, there are four key challenges: (1) how to generate multiple sequences from the larger model's distribution given drafts sequences from the small model; (2) how to dynamically optimize the number of beams to balance efficiency and accuracy; (3) how to efficiently verify the multiple drafts in parallel; and (4) how to address the extra memory costs inherent in beam sampling. To address these challenges, we propose dynamic-width speculative beam decoding (DSBD). Specifically, we first introduce a novel draft and verification scheme that generates multiple sequences following the large model's distribution based on beam sampling trajectories from the small model. Then, we introduce an adaptive mechanism to dynamically tune the number of beams based on the context, optimizing efficiency and effectiveness. Besides, we extend tree-based parallel verification to handle multiple trees simultaneously, accelerating the verification process. Finally, we illustrate a simple modification to our algorithm to mitigate the memory overhead of beam sampling...
Accelerating Large Language Model Pretraining via LFR Pedagogy: Learn, Focus, and Review
Sep 10, 2024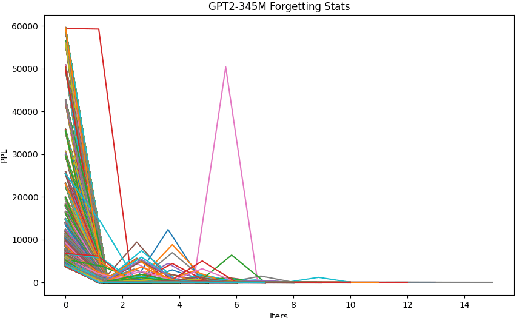
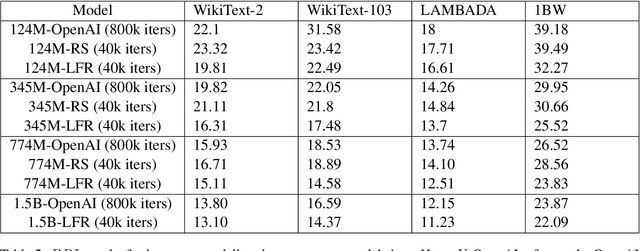
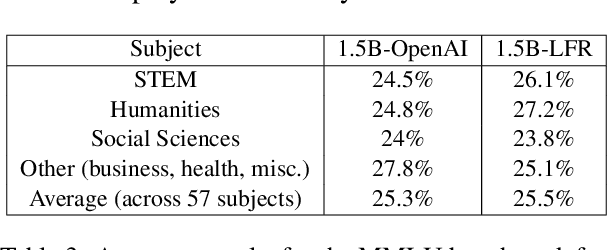
Large Language Model (LLM) pretraining traditionally relies on autoregressive language modeling on randomly sampled data blocks from web-scale datasets. We take inspiration from human learning techniques like spaced repetition to hypothesize that random data sampling for LLMs leads to high training cost and low quality models which tend to forget data. In order to effectively commit web-scale information to long-term memory, we propose the LFR (Learn, Focus, and Review) pedagogy, a new dynamic training paradigm which focuses and repeatedly reviews complex data blocks at systematic intervals based on the model's learning pace and progress. LFR records the model perplexities for different data blocks and frequently revisits blocks with higher perplexity which are more likely to be forgotten. We pretrain the GPT-2 models (124M - 1.5B) from scratch on the OpenWebText dataset using LFR. We test on downstream tasks from the language modeling, question answering, translation, and problem solving domains to achieve consistently lower perplexity and higher accuracy than the baseline OpenAI models, while obtaining a 20x pretraining speed-up.
Multi-Token Joint Speculative Decoding for Accelerating Large Language Model Inference
Jul 12, 2024



Transformer-based Large language models (LLMs) have demonstrated their power in various tasks, but their inference incurs significant time and energy costs. To accelerate LLM inference, speculative decoding uses a smaller model to propose one sequence of tokens, which are subsequently validated in batch by the target large model. Compared with autoregressive decoding, speculative decoding generates the same number of tokens with fewer runs of the large model, hence accelerating the overall inference by $1$-$2\times$. However, greedy decoding is not the optimal decoding algorithm in terms of output perplexity, which is a direct measurement of the effectiveness of a decoding algorithm. An algorithm that has better output perplexity and even better efficiency than speculative decoding can be more useful in practice. To achieve this seemingly contradictory goal, we first introduce multi-token joint greedy decoding (MJGD), which greedily generates multiple tokens at each step based on their joint perplexity. We show that it leads to better perplexity for the whole output. But the computation cost of MJGD is infeasible in practice. So we further propose multi-token joint speculative decoding (MJSD), which approximates and accelerates the MJGD from two aspects: it approximates the joint distribution of the large model with that of a small model, and uses a verification step to guarantee the accuracy of approximation; then it uses beam decoding to accelerate the sequence generation from the joint distribution. Compared with vanilla speculative decoding, MJSD has two advantages: (1) it is an approximation of MJGD, thus achieving better output perplexity; (2) verification with joint likelihood allows it to accept the longest prefix sub-sequence of the draft tokens with valid perplexity, leading to better efficiency...
HMT: Hierarchical Memory Transformer for Long Context Language Processing
May 09, 2024Transformer-based large language models (LLM) have been widely used in language processing applications. However, most of them restrict the context window that permits the model to attend to every token in the inputs. Previous works in recurrent models can memorize past tokens to enable unlimited context and maintain effectiveness. However, they have "flat" memory architectures, which have limitations in selecting and filtering information. Since humans are good at learning and self-adjustment, we speculate that imitating brain memory hierarchy is beneficial for model memorization. We propose the Hierarchical Memory Transformer (HMT), a novel framework that enables and improves models' long-context processing ability by imitating human memorization behavior. Leveraging memory-augmented segment-level recurrence, we organize the memory hierarchy by preserving tokens from early input token segments, passing memory embeddings along the sequence, and recalling relevant information from history. Evaluating general language modeling (Wikitext-103, PG-19) and question-answering tasks (PubMedQA), we show that HMT steadily improves the long-context processing ability of context-constrained and long-context models. With an additional 0.5% - 2% of parameters, HMT can easily plug in and augment future LLMs to handle long context effectively. Our code is open-sourced on Github: https://github.com/OswaldHe/HMT-pytorch.