 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA Done RITE: Robust Invariant Transformation Equilibration for LoRA Optimization
Oct 27, 2024Low-rank adaption (LoRA) is a widely used parameter-efficient finetuning method for LLM that reduces memory requirements. However, current LoRA optimizers lack transformation invariance, meaning the actual updates to the weights depends on how the two LoRA factors are scaled or rotated. This deficiency leads to inefficient learning and sub-optimal solutions in practice. This paper introduces LoRA-RITE, a novel adaptive matrix preconditioning method for LoRA optimization, which can achieve transformation invariance and remain computationally efficient. We provide theoretical analysis to demonstrate the benefit of our method and conduct experiments on various LLM tasks with different models including Gemma 2B, 7B, and mT5-XXL. The results demonstrate consistent improvements against existing optimizers. For example, replacing Adam with LoRA-RITE during LoRA fine-tuning of Gemma-2B yielded 4.6\% accuracy gain on Super-Natural Instructions and 3.5\% accuracy gain across other four LLM benchmarks (HellaSwag, ArcChallenge, GSM8K, OpenBookQA).
Accelerating Large Language Model Pretraining via LFR Pedagogy: Learn, Focus, and Review
Sep 10, 2024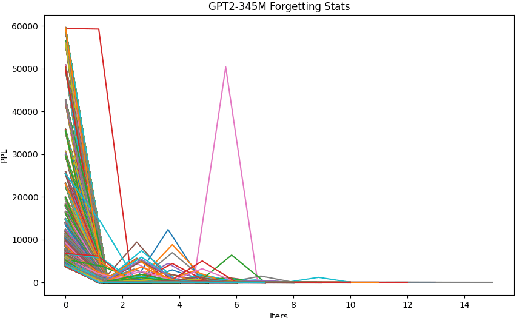
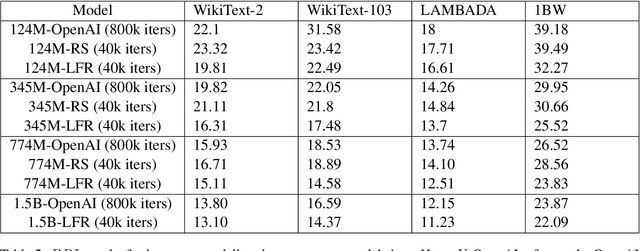
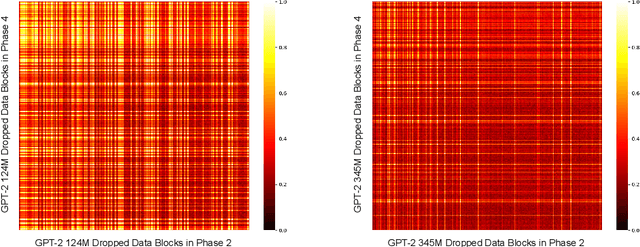
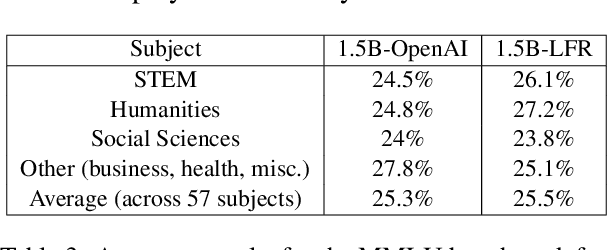
Large Language Model (LLM) pretraining traditionally relies on autoregressive language modeling on randomly sampled data blocks from web-scale datasets. We take inspiration from human learning techniques like spaced repetition to hypothesize that random data sampling for LLMs leads to high training cost and low quality models which tend to forget data. In order to effectively commit web-scale information to long-term memory, we propose the LFR (Learn, Focus, and Review) pedagogy, a new dynamic training paradigm which focuses and repeatedly reviews complex data blocks at systematic intervals based on the model's learning pace and progress. LFR records the model perplexities for different data blocks and frequently revisits blocks with higher perplexity which are more likely to be forgotten. We pretrain the GPT-2 models (124M - 1.5B) from scratch on the OpenWebText dataset using LFR. We test on downstream tasks from the language modeling, question answering, translation, and problem solving domains to achieve consistently lower perplexity and higher accuracy than the baseline OpenAI models, while obtaining a 20x pretraining speed-up.