 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Large Language Model Pretraining via LFR Pedagogy: Learn, Focus, and Review
Paper and Code
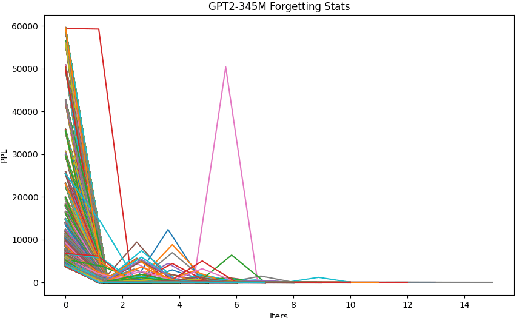
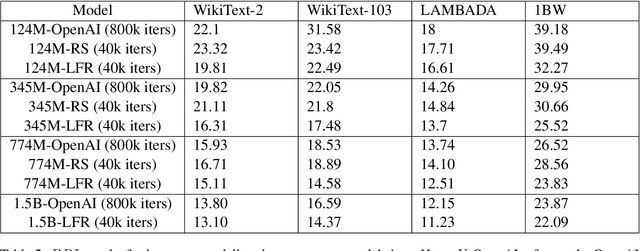
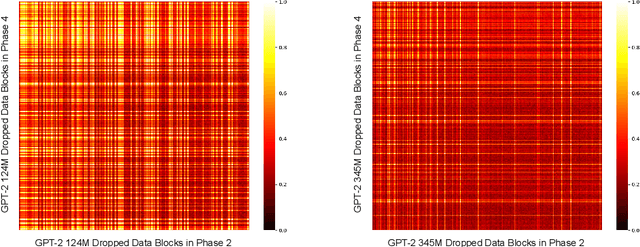
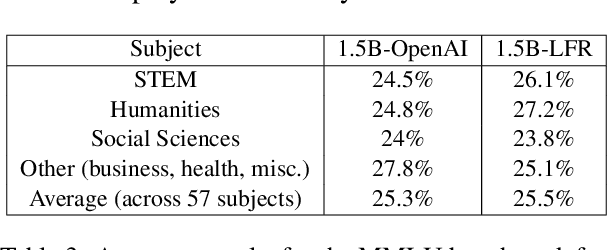
Large Language Model (LLM) pretraining traditionally relies on autoregressive language modeling on randomly sampled data blocks from web-scale datasets. We take inspiration from human learning techniques like spaced repetition to hypothesize that random data sampling for LLMs leads to high training cost and low quality models which tend to forget data. In order to effectively commit web-scale information to long-term memory, we propose the LFR (Learn, Focus, and Review) pedagogy, a new dynamic training paradigm which focuses and repeatedly reviews complex data blocks at systematic intervals based on the model's learning pace and progress. LFR records the model perplexities for different data blocks and frequently revisits blocks with higher perplexity which are more likely to be forgotten. We pretrain the GPT-2 models (124M - 1.5B) from scratch on the OpenWebText dataset using LFR. We test on downstream tasks from the language modeling, question answering, translation, and problem solving domains to achieve consistently lower perplexity and higher accuracy than the baseline OpenAI models, while obtaining a 20x pretraining speed-up.