 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic-Width Speculative Beam Decoding for Efficient LLM Inference
Paper and Code
Sep 25, 2024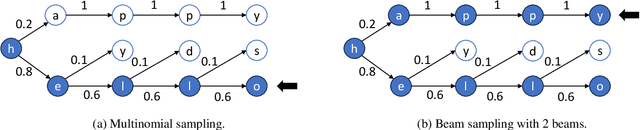
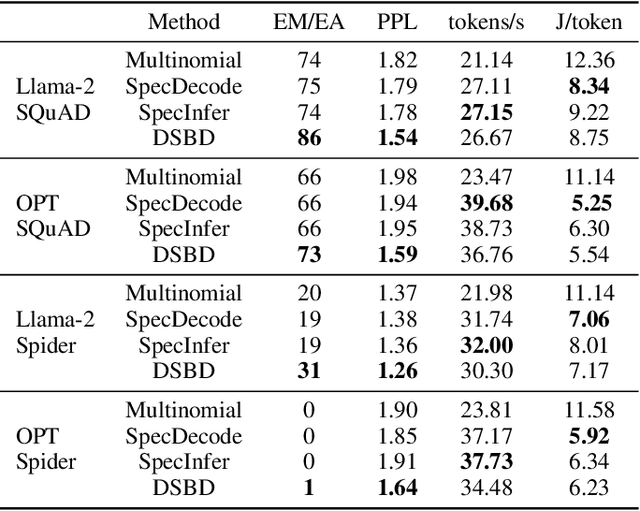
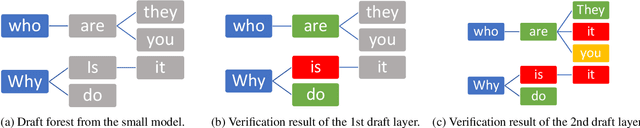
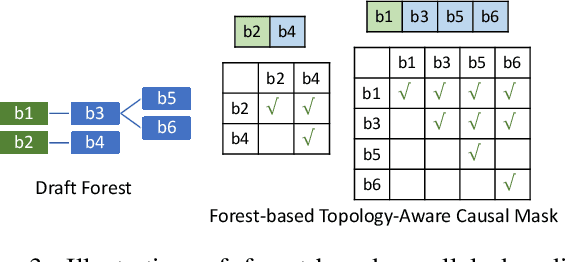
Large language models (LLMs) have shown outstanding performance across numerous real-world tasks. However, the autoregressive nature of these models makes the inference process slow and costly. Speculative decoding has emerged as a promising solution, leveraging a smaller auxiliary model to draft future tokens, which are then validated simultaneously by the larger model, achieving a speed-up of 1-2x. Although speculative decoding matches the same distribution as multinomial sampling, multinomial sampling itself is prone to suboptimal outputs, whereas beam sampling is widely recognized for producing higher-quality results by maintaining multiple candidate sequences at each step. This paper explores the novel integration of speculative decoding with beam sampling. However, there are four key challenges: (1) how to generate multiple sequences from the larger model's distribution given drafts sequences from the small model; (2) how to dynamically optimize the number of beams to balance efficiency and accuracy; (3) how to efficiently verify the multiple drafts in parallel; and (4) how to address the extra memory costs inherent in beam sampling. To address these challenges, we propose dynamic-width speculative beam decoding (DSBD). Specifically, we first introduce a novel draft and verification scheme that generates multiple sequences following the large model's distribution based on beam sampling trajectories from the small model. Then, we introduce an adaptive mechanism to dynamically tune the number of beams based on the context, optimizing efficiency and effectiveness. Besides, we extend tree-based parallel verification to handle multiple trees simultaneously, accelerating the verification process. Finally, we illustrate a simple modification to our algorithm to mitigate the memory overhead of beam sampling...