 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstand and Accelerate Memory Processing Pipeline for Disaggregated LLM Inference
Mar 30, 2026Modern large language models (LLMs) increasingly depends on efficient long-context processing and generation mechanisms, including sparse attention, retrieval-augmented generation (RAG), and compressed contextual memory, to support complex reasoning. We show that these optimizations can be unified into a four-step memory processing pipeline: Prepare Memory, Compute Relevancy, Retrieval, and Apply to Inference. Through systematic profiling, we identify a 22%-97% memory processing overhead in LLM inference and strong heterogeneity in its computational characteristics. Motivated by this insight, we argue that \textbf{heterogeneous systems} are well-suited to accelerate memory processing and thus end-to-end inference. We demonstrate this approach on a GPU-FPGA system by offloading sparse, irregular, and memory-bounded operations to FPGAs while retaining compute-intensive operations on GPUs. Evaluated on an AMD MI210 GPU and an Alveo U55C FPGA, our system is $1.04\sim2.2\times$ faster and requires $1.11\sim4.7\times$ less energy across multiple LLM inference optimizations than the GPU baseline (similar results hold on NVIDIA A100). These results establish heterogeneous systems as a practical direction for efficient LLM memory processing and inform future heterogeneous hardware design.
FlexLLM: Composable HLS Library for Flexible Hybrid LLM Accelerator Design
Jan 22, 2026We present FlexLLM, a composable High-Level Synthesis (HLS) library for rapid development of domain-specific LLM accelerators. FlexLLM exposes key architectural degrees of freedom for stage-customized inference, enabling hybrid designs that tailor temporal reuse and spatial dataflow differently for prefill and decode, and provides a comprehensive quantization suite to support accurate low-bit deployment. Using FlexLLM, we build a complete inference system for the Llama-3.2 1B model in under two months with only 1K lines of code. The system includes: (1) a stage-customized accelerator with hardware-efficient quantization (12.68 WikiText-2 PPL) surpassing SpinQuant baseline, and (2) a Hierarchical Memory Transformer (HMT) plug-in for efficient long-context processing. On the AMD U280 FPGA at 16nm, the accelerator achieves 1.29$\times$ end-to-end speedup, 1.64$\times$ higher decode throughput, and 3.14$\times$ better energy efficiency than an NVIDIA A100 GPU (7nm) running BF16 inference; projected results on the V80 FPGA at 7nm reach 4.71$\times$, 6.55$\times$, and 4.13$\times$, respectively. In long-context scenarios, integrating the HMT plug-in reduces prefill latency by 23.23$\times$ and extends the context window by 64$\times$, delivering 1.10$\times$/4.86$\times$ lower end-to-end latency and 5.21$\times$/6.27$\times$ higher energy efficiency on the U280/V80 compared to the A100 baseline. FlexLLM thus bridges algorithmic innovation in LLM inference and high-performance accelerators with minimal manual effort.
LUT-LLM: Efficient Large Language Model Inference with Memory-based Computations on FPGAs
Nov 09, 2025The rapid progress of large language models (LLMs) has advanced numerous applications, yet efficient single-batch inference remains vital for on-device intelligence. While FPGAs offer fine-grained data control and high energy efficiency, recent GPU optimizations have narrowed their advantage, especially under arithmetic-based computation. To overcome this, we leverage FPGAs' abundant on-chip memory to shift LLM inference from arithmetic- to memory-based computation through table lookups. We present LUT-LLM, the first FPGA accelerator enabling 1B+ LLM inference via vector-quantized memory operations. Our analysis identifies activation-weight co-quantization as the most effective scheme, supported by (1) bandwidth-aware parallel centroid search, (2) efficient 2D table lookups, and (3) a spatial-temporal hybrid design minimizing data caching. Implemented on an AMD V80 FPGA for a customized Qwen 3 1.7B model, LUT-LLM achieves 1.66x lower latency than AMD MI210 and 1.72x higher energy efficiency than NVIDIA A100, scaling to 32B models with 2.16x efficiency gain over A100.
Genome-Anchored Foundation Model Embeddings Improve Molecular Prediction from Histology Images
Jun 24, 2025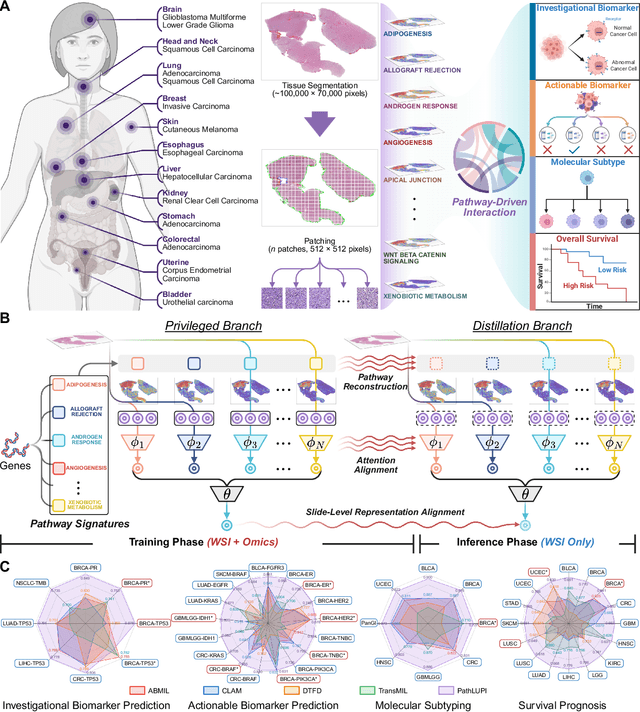
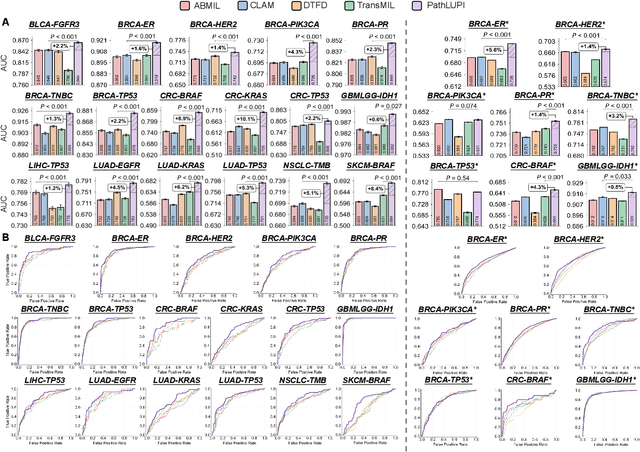
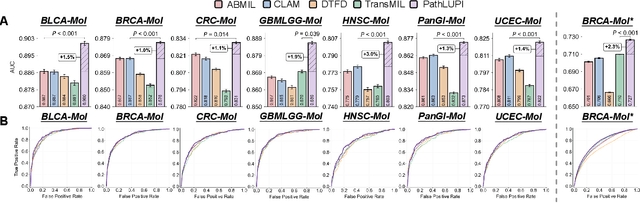
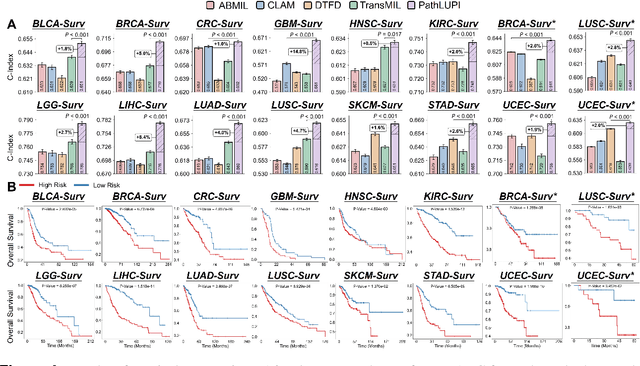
Precision oncology requires accurate molecular insights, yet obtaining these directly from genomics is costly and time-consuming for broad clinical use. Predicting complex molecular features and patient prognosis directly from routine whole-slide images (WSI) remains a major challenge for current deep learning methods. Here we introduce PathLUPI, which uses transcriptomic privileged information during training to extract genome-anchored histological embeddings, enabling effective molecular prediction using only WSIs at inference. Through extensive evaluation across 49 molecular oncology tasks using 11,257 cases among 20 cohorts, PathLUPI demonstrated superior performance compared to conventional methods trained solely on WSIs. Crucially, it achieves AUC $\geq$ 0.80 in 14 of the biomarker prediction and molecular subtyping tasks and C-index $\geq$ 0.70 in survival cohorts of 5 major cancer types. Moreover, PathLUPI embeddings reveal distinct cellular morphological signatures associated with specific genotypes and related biological pathways within WSIs. By effectively encoding molecular context to refine WSI representations, PathLUPI overcomes a key limitation of existing models and offers a novel strategy to bridge molecular insights with routine pathology workflows for wider clinical application.
Towards Hierarchical Multi-Step Reward Models for Enhanced Reasoning in Large Language Models
Mar 19, 2025
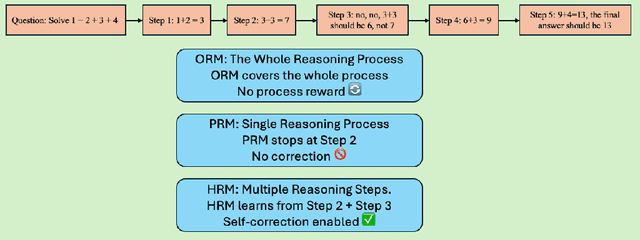
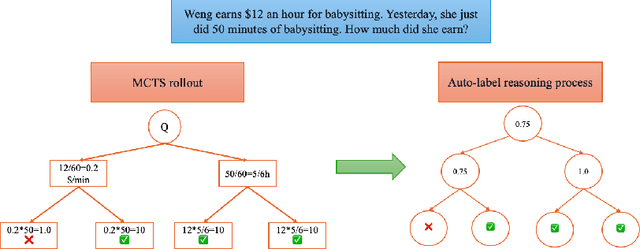

Recent studies show that Large Language Models (LLMs) achieve strong reasoning capabilities through supervised fine-tuning or reinforcement learning. However, a key approach, the Process Reward Model (PRM), suffers from reward hacking, making it unreliable in identifying the best intermediate steps. In this paper, we propose a novel reward model approach, Hierarchical Reward Model (HRM), which evaluates both individual and consecutive reasoning steps from fine-grained and coarse-grained level. HRM performs better in assessing reasoning coherence and self-reflection, particularly when the previous reasoning step is incorrect. Furthermore, to address the inefficiency of autonomous generating PRM training data via Monte Carlo Tree Search (MCTS), we introduce a lightweight and effective data augmentation strategy called Hierarchical Node Compression (HNC) based on node merging (combining two consecutive reasoning steps into one step) in the tree structure. This approach diversifies MCTS results for HRM with negligible computational overhead, enhancing label robustness by introducing noise. Empirical results on the PRM800K dataset demonstrate that HRM, in conjunction with HNC, achieves superior stability and reliability in evaluation compared to PRM. Furthermore, cross-domain evaluations on MATH500 and GSM8K confirm HRM's superior generalization and robustness across diverse reasoning tasks. The code for all experiments will be released at https: //github.com/tengwang0318/hierarchial_reward_model.
InTAR: Inter-Task Auto-Reconfigurable Accelerator Design for High Data Volume Variation in DNNs
Feb 12, 2025The rise of deep neural networks (DNNs) has driven a boom in AI services, which results in an increased demand for computing power and memory. In modern DNNs, the data sizes produced and consumed are highly varied across operations (high data volume variation, HDV). Because existing design paradigms use fixed execution patterns that lead to either low computational efficiency due to pipeline stalls or frequent off-chip memory accesses to manage large intermediate data, HDV applications are challenging to accelerate on FPGAs. To address these challenges, we introduce the Inter-Task Auto-Reconfigurable Accelerator (InTAR), a novel accelerator design for HDV applications on FPGAs. InTAR combines the high computational efficiency of sequential execution with the reduced off-chip memory overhead of dataflow execution. It switches execution patterns automatically with a static schedule determined before circuit design based on resource constraints and model parameters. Unlike previous reconfigurable accelerators, InTAR encodes reconfiguration schedules during circuit design, allowing model-specific optimizations that allocate only the necessary logic and interconnects. Thus, InTAR achieves a high clock frequency with fewer resources and low reconfiguration time. Furthermore, InTAR supports high-level tools such as HLS for fast design generation. We implement a set of multi-task kernels in various HDV DNNs using InTAR. Compared with dataflow and sequential accelerators, InTAR exhibits $1.8\times$ and $7.1 \times$ speedups correspondingly. We also implement InTAR for GPT-2 medium as a more complex example, which achieves a speedup of $\mathbf{3.65 \sim 39.14\times}$ and a $\mathbf{1.72 \sim 10.44\times}$ boost in DSP efficiency compared to the corresponding SoTA accelerators on FPGAs.
Dynamic-Width Speculative Beam Decoding for Efficient LLM Inference
Sep 25, 2024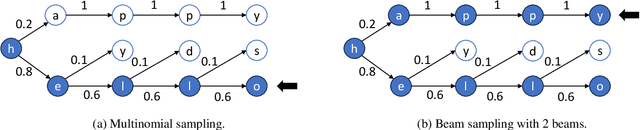
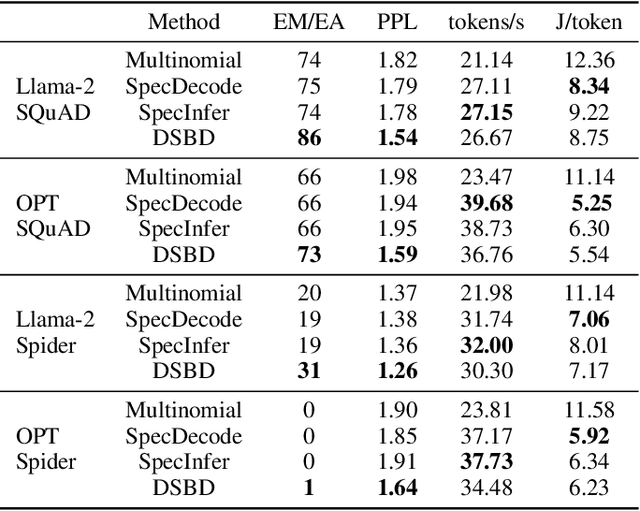
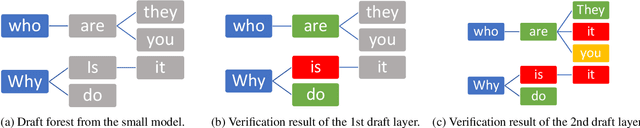
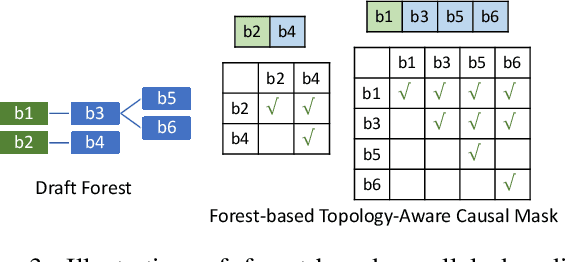
Large language models (LLMs) have shown outstanding performance across numerous real-world tasks. However, the autoregressive nature of these models makes the inference process slow and costly. Speculative decoding has emerged as a promising solution, leveraging a smaller auxiliary model to draft future tokens, which are then validated simultaneously by the larger model, achieving a speed-up of 1-2x. Although speculative decoding matches the same distribution as multinomial sampling, multinomial sampling itself is prone to suboptimal outputs, whereas beam sampling is widely recognized for producing higher-quality results by maintaining multiple candidate sequences at each step. This paper explores the novel integration of speculative decoding with beam sampling. However, there are four key challenges: (1) how to generate multiple sequences from the larger model's distribution given drafts sequences from the small model; (2) how to dynamically optimize the number of beams to balance efficiency and accuracy; (3) how to efficiently verify the multiple drafts in parallel; and (4) how to address the extra memory costs inherent in beam sampling. To address these challenges, we propose dynamic-width speculative beam decoding (DSBD). Specifically, we first introduce a novel draft and verification scheme that generates multiple sequences following the large model's distribution based on beam sampling trajectories from the small model. Then, we introduce an adaptive mechanism to dynamically tune the number of beams based on the context, optimizing efficiency and effectiveness. Besides, we extend tree-based parallel verification to handle multiple trees simultaneously, accelerating the verification process. Finally, we illustrate a simple modification to our algorithm to mitigate the memory overhead of beam sampling...
Multi-Token Joint Speculative Decoding for Accelerating Large Language Model Inference
Jul 12, 2024



Transformer-based Large language models (LLMs) have demonstrated their power in various tasks, but their inference incurs significant time and energy costs. To accelerate LLM inference, speculative decoding uses a smaller model to propose one sequence of tokens, which are subsequently validated in batch by the target large model. Compared with autoregressive decoding, speculative decoding generates the same number of tokens with fewer runs of the large model, hence accelerating the overall inference by $1$-$2\times$. However, greedy decoding is not the optimal decoding algorithm in terms of output perplexity, which is a direct measurement of the effectiveness of a decoding algorithm. An algorithm that has better output perplexity and even better efficiency than speculative decoding can be more useful in practice. To achieve this seemingly contradictory goal, we first introduce multi-token joint greedy decoding (MJGD), which greedily generates multiple tokens at each step based on their joint perplexity. We show that it leads to better perplexity for the whole output. But the computation cost of MJGD is infeasible in practice. So we further propose multi-token joint speculative decoding (MJSD), which approximates and accelerates the MJGD from two aspects: it approximates the joint distribution of the large model with that of a small model, and uses a verification step to guarantee the accuracy of approximation; then it uses beam decoding to accelerate the sequence generation from the joint distribution. Compared with vanilla speculative decoding, MJSD has two advantages: (1) it is an approximation of MJGD, thus achieving better output perplexity; (2) verification with joint likelihood allows it to accept the longest prefix sub-sequence of the draft tokens with valid perplexity, leading to better efficiency...
HMT: Hierarchical Memory Transformer for Long Context Language Processing
May 09, 2024Transformer-based large language models (LLM) have been widely used in language processing applications. However, most of them restrict the context window that permits the model to attend to every token in the inputs. Previous works in recurrent models can memorize past tokens to enable unlimited context and maintain effectiveness. However, they have "flat" memory architectures, which have limitations in selecting and filtering information. Since humans are good at learning and self-adjustment, we speculate that imitating brain memory hierarchy is beneficial for model memorization. We propose the Hierarchical Memory Transformer (HMT), a novel framework that enables and improves models' long-context processing ability by imitating human memorization behavior. Leveraging memory-augmented segment-level recurrence, we organize the memory hierarchy by preserving tokens from early input token segments, passing memory embeddings along the sequence, and recalling relevant information from history. Evaluating general language modeling (Wikitext-103, PG-19) and question-answering tasks (PubMedQA), we show that HMT steadily improves the long-context processing ability of context-constrained and long-context models. With an additional 0.5% - 2% of parameters, HMT can easily plug in and augment future LLMs to handle long context effectively. Our code is open-sourced on Github: https://github.com/OswaldHe/HMT-pytorch.