 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEANCODE: Understanding Models Better for Code Simplification of Pre-trained Large Language Models
May 20, 2025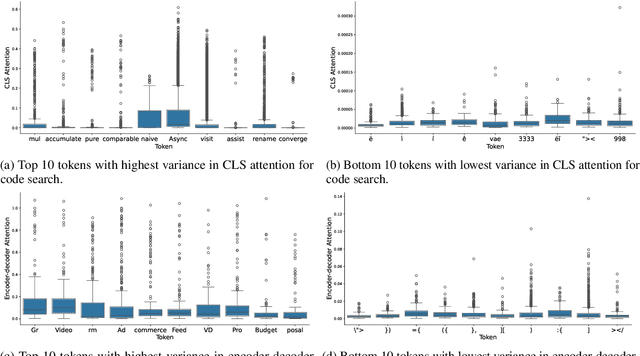
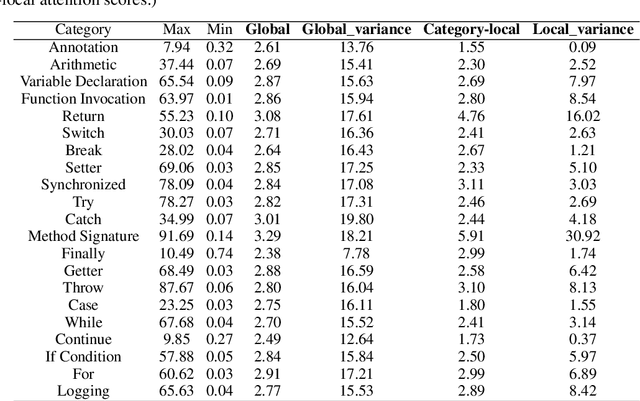
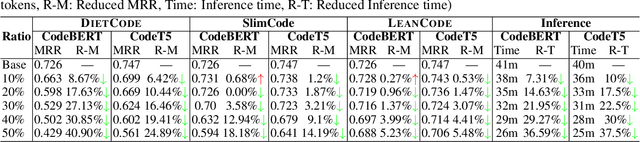

Large Language Models for code often entail significant computational complexity, which grows significantly with the length of the input code sequence. We propose LeanCode for code simplification to reduce training and prediction time, leveraging code contexts in utilizing attention scores to represent the tokens' importance. We advocate for the selective removal of tokens based on the average context-aware attention scores rather than average scores across all inputs. LeanCode uses the attention scores of `CLS' tokens within the encoder for classification tasks, such as code search. It also employs the encoder-decoder attention scores to determine token significance for sequence-to-sequence tasks like code summarization.Our evaluation shows LeanCode's superiority over the SOTAs DietCode and Slimcode, with improvements of 60% and 16% for code search, and 29% and 27% for code summarization, respectively.
Towards Hierarchical Multi-Step Reward Models for Enhanced Reasoning in Large Language Models
Mar 19, 2025
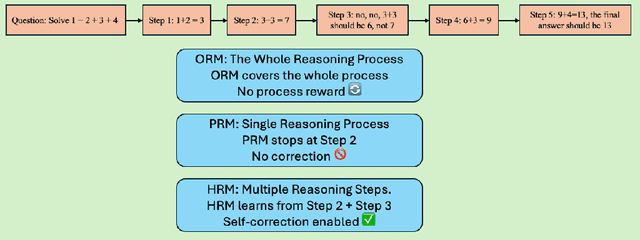
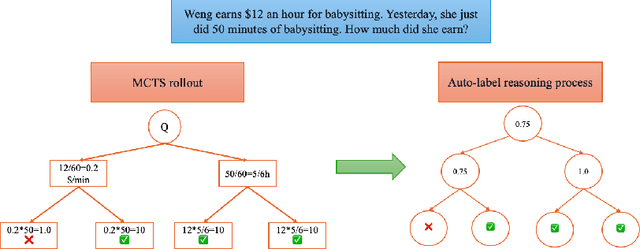

Recent studies show that Large Language Models (LLMs) achieve strong reasoning capabilities through supervised fine-tuning or reinforcement learning. However, a key approach, the Process Reward Model (PRM), suffers from reward hacking, making it unreliable in identifying the best intermediate steps. In this paper, we propose a novel reward model approach, Hierarchical Reward Model (HRM), which evaluates both individual and consecutive reasoning steps from fine-grained and coarse-grained level. HRM performs better in assessing reasoning coherence and self-reflection, particularly when the previous reasoning step is incorrect. Furthermore, to address the inefficiency of autonomous generating PRM training data via Monte Carlo Tree Search (MCTS), we introduce a lightweight and effective data augmentation strategy called Hierarchical Node Compression (HNC) based on node merging (combining two consecutive reasoning steps into one step) in the tree structure. This approach diversifies MCTS results for HRM with negligible computational overhead, enhancing label robustness by introducing noise. Empirical results on the PRM800K dataset demonstrate that HRM, in conjunction with HNC, achieves superior stability and reliability in evaluation compared to PRM. Furthermore, cross-domain evaluations on MATH500 and GSM8K confirm HRM's superior generalization and robustness across diverse reasoning tasks. The code for all experiments will be released at https: //github.com/tengwang0318/hierarchial_reward_model.
TOMATO: Assessing Visual Temporal Reasoning Capabilities in Multimodal Foundation Models
Oct 30, 2024



Existing benchmarks often highlight the remarkable performance achieved by state-of-the-art Multimodal Foundation Models (MFMs) in leveraging temporal context for video understanding. However, how well do the models truly perform visual temporal reasoning? Our study of existing benchmarks shows that this capability of MFMs is likely overestimated as many questions can be solved by using a single, few, or out-of-order frames. To systematically examine current visual temporal reasoning tasks, we propose three principles with corresponding metrics: (1) Multi-Frame Gain, (2) Frame Order Sensitivity, and (3) Frame Information Disparity. Following these principles, we introduce TOMATO, Temporal Reasoning Multimodal Evaluation, a novel benchmark crafted to rigorously assess MFMs' temporal reasoning capabilities in video understanding. TOMATO comprises 1,484 carefully curated, human-annotated questions spanning six tasks (i.e., action count, direction, rotation, shape & trend, velocity & frequency, and visual cues), applied to 1,417 videos, including 805 self-recorded and -generated videos, that encompass human-centric, real-world, and simulated scenarios. Our comprehensive evaluation reveals a human-model performance gap of 57.3% with the best-performing model. Moreover, our in-depth analysis uncovers more fundamental limitations beyond this gap in current MFMs. While they can accurately recognize events in isolated frames, they fail to interpret these frames as a continuous sequence. We believe TOMATO will serve as a crucial testbed for evaluating the next-generation MFMs and as a call to the community to develop AI systems capable of comprehending human world dynamics through the video modality.
A Universal Discriminator for Zero-Shot Generalization
Nov 15, 2022



Generative modeling has been the dominant approach for large-scale pretraining and zero-shot generalization. In this work, we challenge this convention by showing that discriminative approaches perform substantially better than generative ones on a large number of NLP tasks. Technically, we train a single discriminator to predict whether a text sample comes from the true data distribution, similar to GANs. Since many NLP tasks can be formulated as selecting from a few options, we use this discriminator to predict the option with the highest probability. This simple formulation achieves state-of-the-art zero-shot results on the T0 benchmark, outperforming T0 by 16.0\%, 7.8\%, and 11.5\% respectively on different scales. In the finetuning setting, our approach also achieves new state-of-the-art results on a wide range of NLP tasks, with only 1/4 parameters of previous methods. Meanwhile, our approach requires minimal prompting efforts, which largely improves robustness and is essential for real-world applications. Furthermore, we also jointly train a generalized UD in combination with generative tasks, which maintains its advantage on discriminative tasks and simultaneously works on generative tasks.
Zero-Label Prompt Selection
Nov 09, 2022
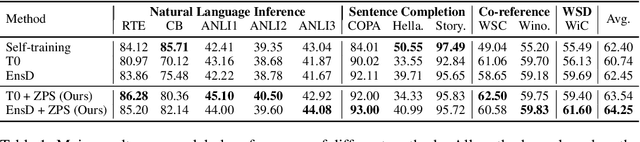
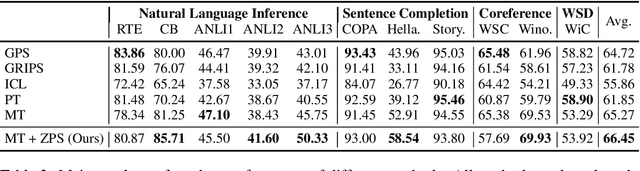

Natural language prompts have been shown to facilitate cross-task generalization for large language models. However, with no or limited labeled examples, the cross-task performance is highly sensitive to the choice of prompts, while selecting a high-performing prompt is challenging given the scarcity of labels. To address the issue, we propose a Zero-Label Prompt Selection (ZPS) method that selects prompts without any labeled data or gradient update. Specifically, given the candidate human-written prompts for a task, ZPS labels a set of unlabeled data with a prompt ensemble and uses the pseudo-labels for prompt selection. Experiments show that ZPS improves over prior methods by a sizeable margin in zero-label performance. We also extend ZPS to a few-shot setting and show its advantages over strong baselines such as prompt tuning and model tuning.
Prompt-Based Metric Learning for Few-Shot NER
Nov 08, 2022Few-shot named entity recognition (NER) targets generalizing to unseen labels and/or domains with few labeled examples. Existing metric learning methods compute token-level similarities between query and support sets, but are not able to fully incorporate label semantics into modeling. To address this issue, we propose a simple method to largely improve metric learning for NER: 1) multiple prompt schemas are designed to enhance label semantics; 2) we propose a novel architecture to effectively combine multiple prompt-based representations. Empirically, our method achieves new state-of-the-art (SOTA) results under 16 of the 18 considered settings, substantially outperforming the previous SOTA by an average of 8.84% and a maximum of 34.51% in relative gains of micro F1. Our code is available at https://github.com/AChen-qaq/ProML.
On the Performance of Data Compression in Clustered Fog Radio Access Networks
Jul 01, 2022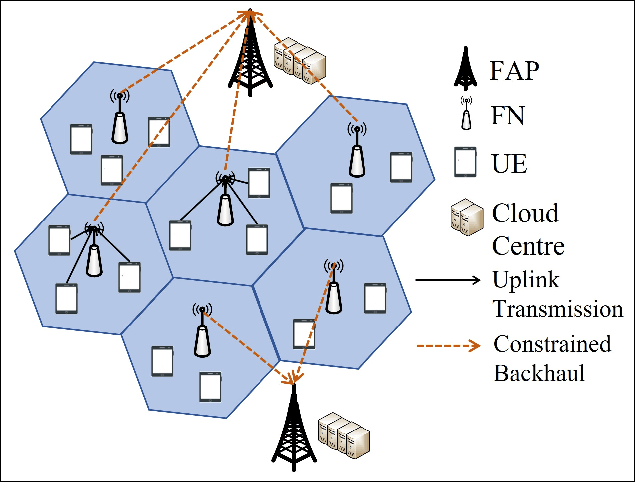
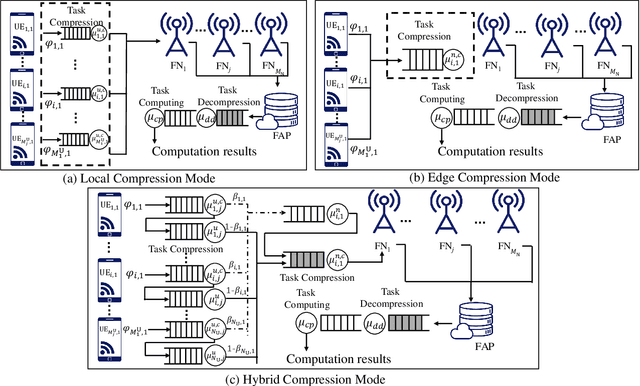
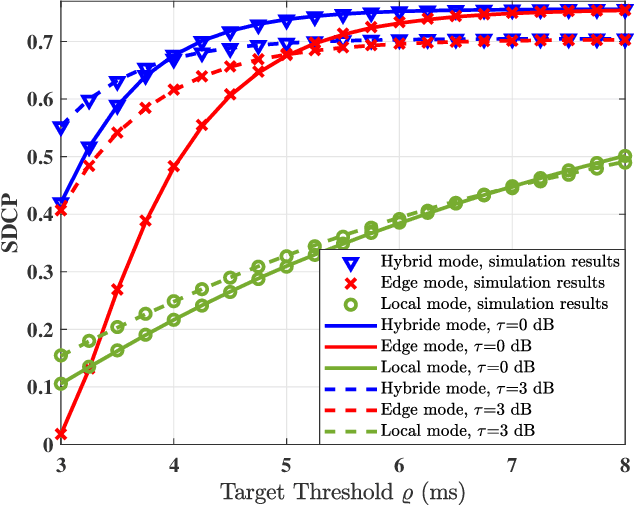
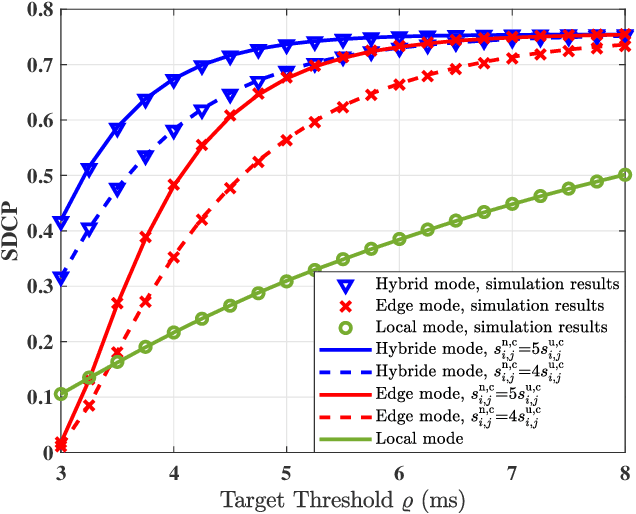
The fog-radio-access-network (F-RAN) has been proposed to address the strict latency requirements, which offloads computation tasks generated in user equipments (UEs) to the edge to reduce the processing latency. However, it incorporates the task transmission latency, which may become the bottleneck of latency requirements. Data compression (DC) has been considered as one of the promising techniques to reduce the transmission latency. By compressing the computation tasks before transmitting, the transmission delay is reduced due to the shrink transmitted data size, and the original computing task can be retrieved by employing data decompressing (DD) at the edge nodes or the centre cloud. Nevertheless, the DC and DD incorporate extra processing latency, and the latency performance has not been investigated in the large-scale DC-enabled F-RAN. Therefore, in this work, the successful data compression probability (SDCP) is defined to analyse the latency performance of the F-RAN. Moreover, to analyse the effect of compression offloading ratio (COR), a novel hybrid compression mode is proposed based on the queueing theory. Based on this, the closed-form result of SDCP in the large-scale DC-enabled F-RAN is derived by combining the Matern cluster process and M/G/1 queueing model, and validated by Monte Carlo simulations. Based on the derived SDCP results, the effects of COR on the SDCP is analysed numerically. The results show that the SDCP with the optimal COR can be enhanced with a maximum value of 0.3 and 0.55 as compared with the cases of compressing all computing tasks at the edge and at the UE, respectively. Moreover, for the system requiring the minimal latency, the proposed hybrid compression mode can alleviate the requirement on the backhaul capacity.
NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework
Nov 07, 2021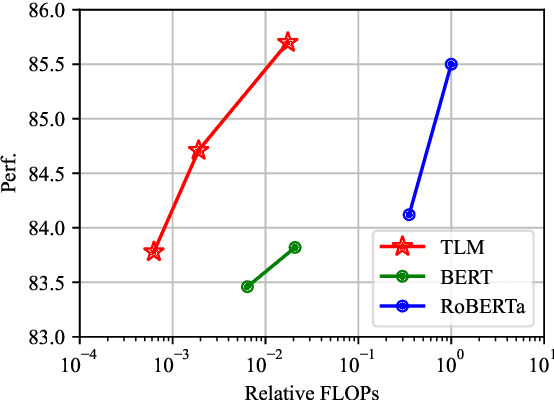
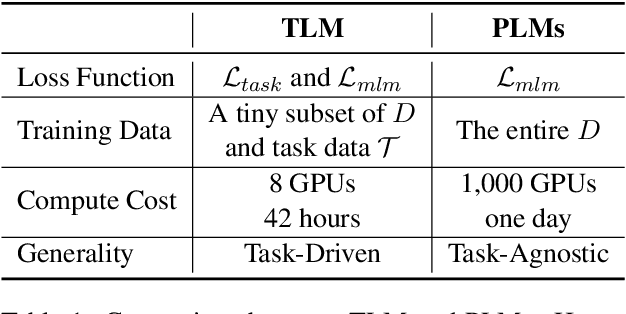
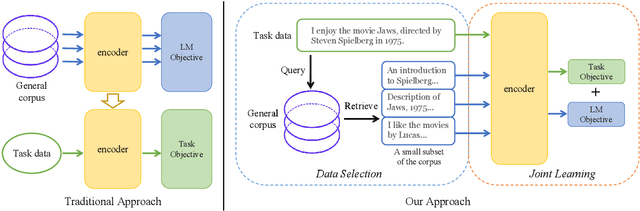
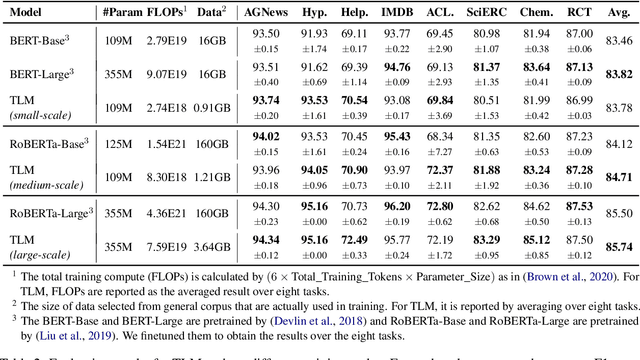
Pretrained language models have become the standard approach for many NLP tasks due to strong performance, but they are very expensive to train. We propose a simple and efficient learning framework, TLM, that does not rely on large-scale pretraining. Given some labeled task data and a large general corpus, TLM uses task data as queries to retrieve a tiny subset of the general corpus and jointly optimizes the task objective and the language modeling objective from scratch. On eight classification datasets in four domains, TLM achieves results better than or similar to pretrained language models (e.g., RoBERTa-Large) while reducing the training FLOPs by two orders of magnitude. With high accuracy and efficiency, we hope TLM will contribute to democratizing NLP and expediting its development.
FewNLU: Benchmarking State-of-the-Art Methods for Few-Shot Natural Language Understanding
Sep 27, 2021



The few-shot natural language understanding (NLU) task has attracted much recent attention. However, prior methods have been evaluated under a disparate set of protocols, which hinders fair comparison and measuring progress of the field. To address this issue, we introduce an evaluation framework that improves previous evaluation procedures in three key aspects, i.e., test performance, dev-test correlation, and stability. Under this new evaluation framework, we re-evaluate several state-of-the-art few-shot methods for NLU tasks. Our framework reveals new insights: (1) both the absolute performance and relative gap of the methods were not accurately estimated in prior literature; (2) no single method dominates most tasks with consistent performance; (3) improvements of some methods diminish with a larger pretrained model; and (4) gains from different methods are often complementary and the best combined model performs close to a strong fully-supervised baseline. We open-source our toolkit, FewNLU, that implements our evaluation framework along with a number of state-of-the-art methods.
FlipDA: Effective and Robust Data Augmentation for Few-Shot Learning
Aug 13, 2021
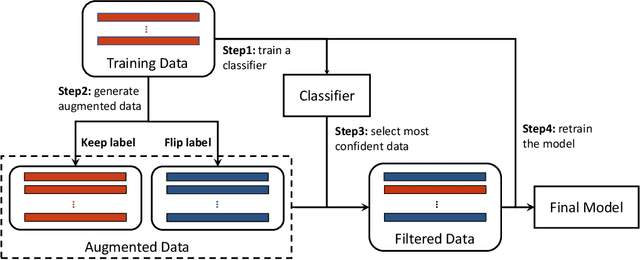

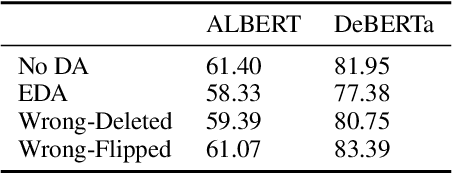
Most previous methods for text data augmentation are limited to simple tasks and weak baselines. We explore data augmentation on hard tasks (i.e., few-shot natural language understanding) and strong baselines (i.e., pretrained models with over one billion parameters). Under this setting, we reproduced a large number of previous augmentation methods and found that these methods bring marginal gains at best and sometimes degrade the performance much. To address this challenge, we propose a novel data augmentation method FlipDA that jointly uses a generative model and a classifier to generate label-flipped data. Central to the idea of FlipDA is the discovery that generating label-flipped data is more crucial to the performance than generating label-preserved data. Experiments show that FlipDA achieves a good tradeoff between effectiveness and robustness---it substantially improves many tasks while not negatively affecting the others.