 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenChemIE: An Information Extraction Toolkit For Chemistry Literature
Apr 01, 2024



Information extraction from chemistry literature is vital for constructing up-to-date reaction databases for data-driven chemistry. Complete extraction requires combining information across text, tables, and figures, whereas prior work has mainly investigated extracting reactions from single modalities. In this paper, we present OpenChemIE to address this complex challenge and enable the extraction of reaction data at the document level. OpenChemIE approaches the problem in two steps: extracting relevant information from individual modalities and then integrating the results to obtain a final list of reactions. For the first step, we employ specialized neural models that each address a specific task for chemistry information extraction, such as parsing molecules or reactions from text or figures. We then integrate the information from these modules using chemistry-informed algorithms, allowing for the extraction of fine-grained reaction data from reaction condition and substrate scope investigations. Our machine learning models attain state-of-the-art performance when evaluated individually, and we meticulously annotate a challenging dataset of reaction schemes with R-groups to evaluate our pipeline as a whole, achieving an F1 score of 69.5%. Additionally, the reaction extraction results of \ours attain an accuracy score of 64.3% when directly compared against the Reaxys chemical database. We provide OpenChemIE freely to the public as an open-source package, as well as through a web interface.
Predictive Chemistry Augmented with Text Retrieval
Dec 08, 2023



This paper focuses on using natural language descriptions to enhance predictive models in the chemistry field. Conventionally, chemoinformatics models are trained with extensive structured data manually extracted from the literature. In this paper, we introduce TextReact, a novel method that directly augments predictive chemistry with texts retrieved from the literature. TextReact retrieves text descriptions relevant for a given chemical reaction, and then aligns them with the molecular representation of the reaction. This alignment is enhanced via an auxiliary masked LM objective incorporated in the predictor training. We empirically validate the framework on two chemistry tasks: reaction condition recommendation and one-step retrosynthesis. By leveraging text retrieval, TextReact significantly outperforms state-of-the-art chemoinformatics models trained solely on molecular data.
RxnScribe: A Sequence Generation Model for Reaction Diagram Parsing
May 19, 2023Reaction diagram parsing is the task of extracting reaction schemes from a diagram in the chemistry literature. The reaction diagrams can be arbitrarily complex, thus robustly parsing them into structured data is an open challenge. In this paper, we present RxnScribe, a machine learning model for parsing reaction diagrams of varying styles. We formulate this structured prediction task with a sequence generation approach, which condenses the traditional pipeline into an end-to-end model. We train RxnScribe on a dataset of 1,378 diagrams and evaluate it with cross validation, achieving an 80.0% soft match F1 score, with significant improvements over previous models. Our code and data are publicly available at https://github.com/thomas0809/RxnScribe.
Multi-Vector Retrieval as Sparse Alignment
Nov 02, 2022



Multi-vector retrieval models improve over single-vector dual encoders on many information retrieval tasks. In this paper, we cast the multi-vector retrieval problem as sparse alignment between query and document tokens. We propose AligneR, a novel multi-vector retrieval model that learns sparsified pairwise alignments between query and document tokens (e.g. `dog' vs. `puppy') and per-token unary saliences reflecting their relative importance for retrieval. We show that controlling the sparsity of pairwise token alignments often brings significant performance gains. While most factoid questions focusing on a specific part of a document require a smaller number of alignments, others requiring a broader understanding of a document favor a larger number of alignments. Unary saliences, on the other hand, decide whether a token ever needs to be aligned with others for retrieval (e.g. `kind' from `kind of currency is used in new zealand}'). With sparsified unary saliences, we are able to prune a large number of query and document token vectors and improve the efficiency of multi-vector retrieval. We learn the sparse unary saliences with entropy-regularized linear programming, which outperforms other methods to achieve sparsity. In a zero-shot setting, AligneR scores 51.1 points nDCG@10, achieving a new retriever-only state-of-the-art on 13 tasks in the BEIR benchmark. In addition, adapting pairwise alignments with a few examples (<= 8) further improves the performance up to 15.7 points nDCG@10 for argument retrieval tasks. The unary saliences of AligneR helps us to keep only 20% of the document token representations with minimal performance loss. We further show that our model often produces interpretable alignments and significantly improves its performance when initialized from larger language models.
Robust Molecular Image Recognition: A Graph Generation Approach
May 28, 2022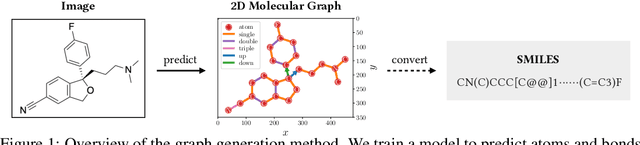
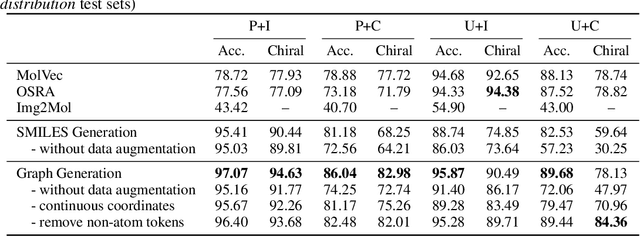
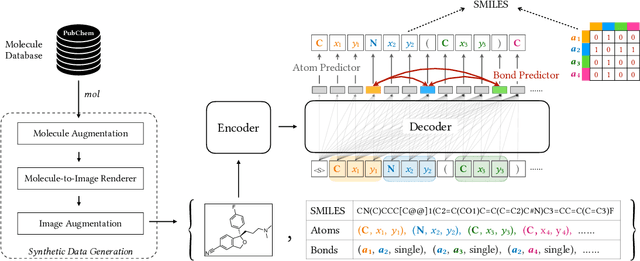
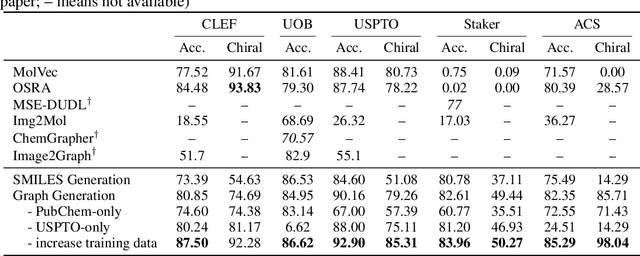
Molecular image recognition is a fundamental task in information extraction from chemistry literature. Previous data-driven models formulate it as an image-to-sequence task, to generate a sequential representation of the molecule (e.g. SMILES string) from its graphical representation. Although they perform adequately on certain benchmarks, these models are not robust in real-world situations, where molecular images differ in style, quality, and chemical patterns. In this paper, we propose a novel graph generation approach that explicitly predicts atoms and bonds, along with their geometric layouts, to construct the molecular graph. We develop data augmentation strategies for molecules and images to increase the robustness of our model against domain shifts. Our model is flexible to incorporate chemistry constraints, and produces more interpretable predictions than SMILES. In experiments on both synthetic and realistic molecular images, our model significantly outperforms previous models, achieving 84-93% accuracy on five benchmarks. We also conduct human evaluation and show that our model reduces the time for a chemist to extract molecular structures from images by roughly 50%.
FewNLU: Benchmarking State-of-the-Art Methods for Few-Shot Natural Language Understanding
Sep 27, 2021



The few-shot natural language understanding (NLU) task has attracted much recent attention. However, prior methods have been evaluated under a disparate set of protocols, which hinders fair comparison and measuring progress of the field. To address this issue, we introduce an evaluation framework that improves previous evaluation procedures in three key aspects, i.e., test performance, dev-test correlation, and stability. Under this new evaluation framework, we re-evaluate several state-of-the-art few-shot methods for NLU tasks. Our framework reveals new insights: (1) both the absolute performance and relative gap of the methods were not accurately estimated in prior literature; (2) no single method dominates most tasks with consistent performance; (3) improvements of some methods diminish with a larger pretrained model; and (4) gains from different methods are often complementary and the best combined model performs close to a strong fully-supervised baseline. We open-source our toolkit, FewNLU, that implements our evaluation framework along with a number of state-of-the-art methods.
GPT Understands, Too
Mar 18, 2021



While GPTs with traditional fine-tuning fail to achieve strong results on natural language understanding (NLU), we show that GPTs can be better than or comparable to similar-sized BERTs on NLU tasks with a novel method P-tuning -- which employs trainable continuous prompt embeddings. On the knowledge probing (LAMA) benchmark, the best GPT recovers 64\% (P@1) of world knowledge without any additional text provided during test time, which substantially improves the previous best by 20+ percentage points. On the SuperGlue benchmark, GPTs achieve comparable and sometimes better performance to similar-sized BERTs in supervised learning. Importantly, we find that P-tuning also improves BERTs' performance in both few-shot and supervised settings while largely reducing the need for prompt engineering. Consequently, P-tuning outperforms the state-of-the-art approaches on the few-shot SuperGlue benchmark.
All NLP Tasks Are Generation Tasks: A General Pretraining Framework
Mar 18, 2021



There have been various types of pretraining architectures including autoregressive models (e.g., GPT), autoencoding models (e.g., BERT), and encoder-decoder models (e.g., T5). On the other hand, NLP tasks are different in nature, with three main categories being classification, unconditional generation, and conditional generation. However, none of the pretraining frameworks performs the best for all tasks, which introduces inconvenience for model development and selection. We propose a novel pretraining framework GLM (General Language Model) to address this challenge. Compared to previous work, our architecture has three major benefits: (1) it performs well on classification, unconditional generation, and conditional generation tasks with one single pretrained model; (2) it outperforms BERT-like models on classification due to improved pretrain-finetune consistency; (3) it naturally handles variable-length blank filling which is crucial for many downstream tasks. Empirically, GLM substantially outperforms BERT on the SuperGLUE natural language understanding benchmark with the same amount of pre-training data. Moreover, GLM with 1.25x parameters of BERT-Large achieves the best performance in NLU, conditional and unconditional generation at the same time, which demonstrates its generalizability to different downstream tasks.
GraphIE: A Graph-Based Framework for Information Extraction
Oct 31, 2018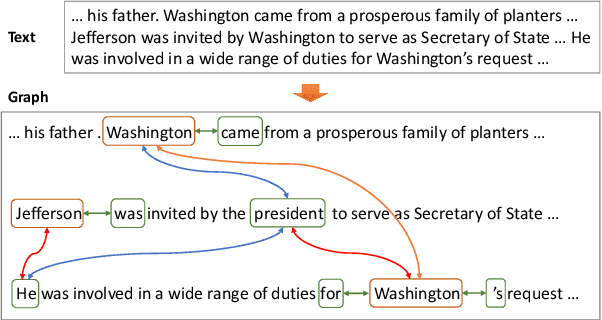


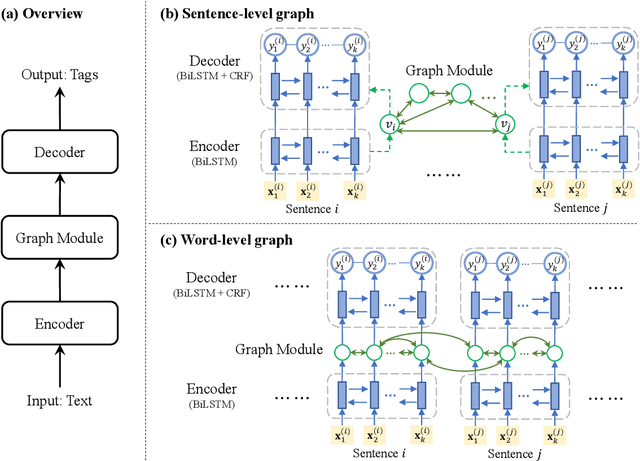
Most modern Information Extraction (IE) systems are implemented as sequential taggers and focus on modelling local dependencies. Non-local and non-sequential context is, however, a valuable source of information to improve predictions. In this paper, we introduce GraphIE, a framework that operates over a graph representing both local and non-local dependencies between textual units (i.e. words or sentences). The algorithm propagates information between connected nodes through graph convolutions and exploits the richer representation to improve word level predictions. The framework is evaluated on three different tasks, namely social media, textual and visual information extraction. Results show that GraphIE outperforms a competitive baseline (BiLSTM+CRF) in all tasks by a significant margin.
Weakly Learning to Match Experts in Online Community
May 07, 2018



In online question-and-answer (QA) websites like Quora, one central issue is to find (invite) users who are able to provide answers to a given question and at the same time would be unlikely to say "no" to the invitation. The challenge is how to trade off the matching degree between users' expertise and the question topic, and the likelihood of positive response from the invited users. In this paper, we formally formulate the problem and develop a weakly supervised factor graph (WeakFG) model to address the problem. The model explicitly captures expertise matching degree between questions and users. To model the likelihood that an invited user is willing to answer a specific question, we incorporate a set of correlations based on social identity theory into the WeakFG model. We use two different genres of datasets: QA-Expert and Paper-Reviewer, to validate the proposed model. Our experimental results show that the proposed model can significantly outperform (+1.5-10.7% by MAP) the state-of-the-art algorithms for matching users (experts) with community questions. We have also developed an online system to further demonstrate the advantages of the proposed method.