 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn decomposability and subdifferential of the tensor nuclear norm
Oct 06, 2025
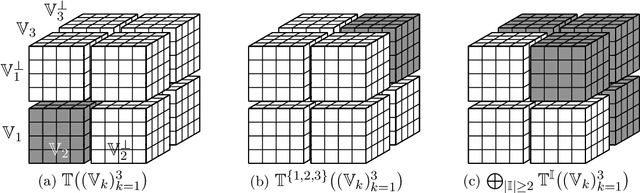
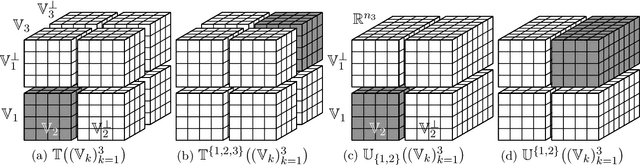
We study the decomposability and the subdifferential of the tensor nuclear norm. Both concepts are well understood and widely applied in matrices but remain unclear for higher-order tensors. We show that the tensor nuclear norm admits a full decomposability over specific subspaces and determine the largest possible subspaces that allow the full decomposability. We derive novel inclusions of the subdifferential of the tensor nuclear norm and study its subgradients in a variety of subspaces of interest. All the results hold for tensors of an arbitrary order. As an immediate application, we establish the statistical performance of the tensor robust principal component analysis, the first such result for tensors of an arbitrary order.
Beyond I-Con: Exploring New Dimension of Distance Measures in Representation Learning
Sep 05, 2025The Information Contrastive (I-Con) framework revealed that over 23 representation learning methods implicitly minimize KL divergence between data and learned distributions that encode similarities between data points. However, a KL-based loss may be misaligned with the true objective, and properties of KL divergence such as asymmetry and unboundedness may create optimization challenges. We present Beyond I-Con, a framework that enables systematic discovery of novel loss functions by exploring alternative statistical divergences and similarity kernels. Key findings: (1) on unsupervised clustering of DINO-ViT embeddings, we achieve state-of-the-art results by modifying the PMI algorithm to use total variation (TV) distance; (2) on supervised contrastive learning, we outperform the standard approach by using TV and a distance-based similarity kernel instead of KL and an angular kernel; (3) on dimensionality reduction, we achieve superior qualitative results and better performance on downstream tasks than SNE by replacing KL with a bounded f-divergence. Our results highlight the importance of considering divergence and similarity kernel choices in representation learning optimization.
When Do Skills Help Reinforcement Learning? A Theoretical Analysis of Temporal Abstractions
Jun 12, 2024Skills are temporal abstractions that are intended to improve reinforcement learning (RL) performance through hierarchical RL. Despite our intuition about the properties of an environment that make skills useful, a precise characterization has been absent. We provide the first such characterization, focusing on the utility of deterministic skills in deterministic sparse-reward environments with finite action spaces. We show theoretically and empirically that RL performance gain from skills is worse in environments where solutions to states are less compressible. Additional theoretical results suggest that skills benefit exploration more than they benefit learning from existing experience, and that using unexpressive skills such as macroactions may worsen RL performance. We hope our findings can guide research on automatic skill discovery and help RL practitioners better decide when and how to use skills.
Predictive Chemistry Augmented with Text Retrieval
Dec 08, 2023



This paper focuses on using natural language descriptions to enhance predictive models in the chemistry field. Conventionally, chemoinformatics models are trained with extensive structured data manually extracted from the literature. In this paper, we introduce TextReact, a novel method that directly augments predictive chemistry with texts retrieved from the literature. TextReact retrieves text descriptions relevant for a given chemical reaction, and then aligns them with the molecular representation of the reaction. This alignment is enhanced via an auxiliary masked LM objective incorporated in the predictor training. We empirically validate the framework on two chemistry tasks: reaction condition recommendation and one-step retrosynthesis. By leveraging text retrieval, TextReact significantly outperforms state-of-the-art chemoinformatics models trained solely on molecular data.
LEMMA: Bootstrapping High-Level Mathematical Reasoning with Learned Symbolic Abstractions
Nov 16, 2022Humans tame the complexity of mathematical reasoning by developing hierarchies of abstractions. With proper abstractions, solutions to hard problems can be expressed concisely, thus making them more likely to be found. In this paper, we propose Learning Mathematical Abstractions (LEMMA): an algorithm that implements this idea for reinforcement learning agents in mathematical domains. LEMMA augments Expert Iteration with an abstraction step, where solutions found so far are revisited and rewritten in terms of new higher-level actions, which then become available to solve new problems. We evaluate LEMMA on two mathematical reasoning tasks--equation solving and fraction simplification--in a step-by-step fashion. In these two domains, LEMMA improves the ability of an existing agent, both solving more problems and generalizing more effectively to harder problems than those seen during training.