 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold Steering Reveals the Shared Geometry of Neural Network Representation and Behavior
May 06, 2026Neural representations carry rich geometric structure; but does that structure causally shape behavior? To address this question, we intervene along paths through activation space defined by different geometries, and measure the behavioral trajectories they induce. In particular, we test whether interventions that respect the geometry of activation space will yield behaviors close to those the model exhibits naturally. Concretely, we first fit an activation manifold $M_h$ to representations and a behavior manifold $M_y$ to output probability distributions. We then test the link $M_h \leftrightarrow M_y$ via interventions: we find that steering along $M_h$, which we term manifold steering, yields behavioral trajectories that follow $M_y$, while linear steering -- which assumes a Euclidean geometry -- cuts through off-manifold regions and hence produces unnatural outputs. Moreover, optimizing interventions in activation space to produce paths along $M_y$ recovers activation trajectories that trace the curvature of $M_h$. We demonstrate this bidirectional relationship between the geometry of representation and behavior across tasks and modalities. In language models, we use reasoning tasks with cyclic and sequential geometries as well as in-context learning tasks with more complex graph geometries. In a video world model, we use a task with geometry corresponding to physical dynamics. Overall, our work shows that geometry in neural representation is not merely incidental, but is in fact the proper object for enabling principled control via intervention on internals. This recasts the core problem of steering from finding the right direction to finding the right geometry.
Poly-EPO: Training Exploratory Reasoning Models
Apr 19, 2026Exploration is a cornerstone of learning from experience: it enables agents to find solutions to complex problems, generalize to novel ones, and scale performance with test-time compute. In this paper, we present a framework for post-training language models (LMs) that explicitly encourages optimistic exploration and promotes a synergy between exploration and exploitation. The central idea is to train the LM to generate sets of responses that are collectively accurate under the reward function and exploratory in their reasoning strategies. We first develop a general recipe for optimizing LMs with set reinforcement learning (set RL) under arbitrary objective functions, showing how standard RL algorithms can be adapted to this setting through a modification to the advantage computation. We then propose Polychromic Exploratory Policy Optimization (Poly-EPO), which instantiates this framework with an objective that explicitly synergizes exploration and exploitation. Across a range of reasoning benchmarks, we show that Poly-EPO improves generalization, as evidenced by higher pass@$k$ coverage, preserves greater diversity in model generations, and effectively scales with test-time compute.
Large Language Model Reasoning Failures
Feb 05, 2026Large Language Models (LLMs) have exhibited remarkable reasoning capabilities, achieving impressive results across a wide range of tasks. Despite these advances, significant reasoning failures persist, occurring even in seemingly simple scenarios. To systematically understand and address these shortcomings, we present the first comprehensive survey dedicated to reasoning failures in LLMs. We introduce a novel categorization framework that distinguishes reasoning into embodied and non-embodied types, with the latter further subdivided into informal (intuitive) and formal (logical) reasoning. In parallel, we classify reasoning failures along a complementary axis into three types: fundamental failures intrinsic to LLM architectures that broadly affect downstream tasks; application-specific limitations that manifest in particular domains; and robustness issues characterized by inconsistent performance across minor variations. For each reasoning failure, we provide a clear definition, analyze existing studies, explore root causes, and present mitigation strategies. By unifying fragmented research efforts, our survey provides a structured perspective on systemic weaknesses in LLM reasoning, offering valuable insights and guiding future research towards building stronger, more reliable, and robust reasoning capabilities. We additionally release a comprehensive collection of research works on LLM reasoning failures, as a GitHub repository at https://github.com/Peiyang-Song/Awesome-LLM-Reasoning-Failures, to provide an easy entry point to this area.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
An Approach to Technical AGI Safety and Security
Apr 02, 2025Artificial General Intelligence (AGI) promises transformative benefits but also presents significant risks. We develop an approach to address the risk of harms consequential enough to significantly harm humanity. We identify four areas of risk: misuse, misalignment, mistakes, and structural risks. Of these, we focus on technical approaches to misuse and misalignment. For misuse, our strategy aims to prevent threat actors from accessing dangerous capabilities, by proactively identifying dangerous capabilities, and implementing robust security, access restrictions, monitoring, and model safety mitigations. To address misalignment, we outline two lines of defense. First, model-level mitigations such as amplified oversight and robust training can help to build an aligned model. Second, system-level security measures such as monitoring and access control can mitigate harm even if the model is misaligned. Techniques from interpretability, uncertainty estimation, and safer design patterns can enhance the effectiveness of these mitigations. Finally, we briefly outline how these ingredients could be combined to produce safety cases for AGI systems.
Value Profiles for Encoding Human Variation
Mar 19, 2025Modelling human variation in rating tasks is crucial for enabling AI systems for personalization, pluralistic model alignment, and computational social science. We propose representing individuals using value profiles -- natural language descriptions of underlying values compressed from in-context demonstrations -- along with a steerable decoder model to estimate ratings conditioned on a value profile or other rater information. To measure the predictive information in rater representations, we introduce an information-theoretic methodology. We find that demonstrations contain the most information, followed by value profiles and then demographics. However, value profiles offer advantages in terms of scrutability, interpretability, and steerability due to their compressed natural language format. Value profiles effectively compress the useful information from demonstrations (>70% information preservation). Furthermore, clustering value profiles to identify similarly behaving individuals better explains rater variation than the most predictive demographic groupings. Going beyond test set performance, we show that the decoder models interpretably change ratings according to semantic profile differences, are well-calibrated, and can help explain instance-level disagreement by simulating an annotator population. These results demonstrate that value profiles offer novel, predictive ways to describe individual variation beyond demographics or group information.
Bayesian Preference Elicitation with Language Models
Mar 08, 2024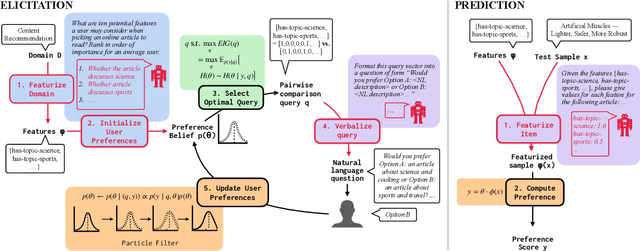
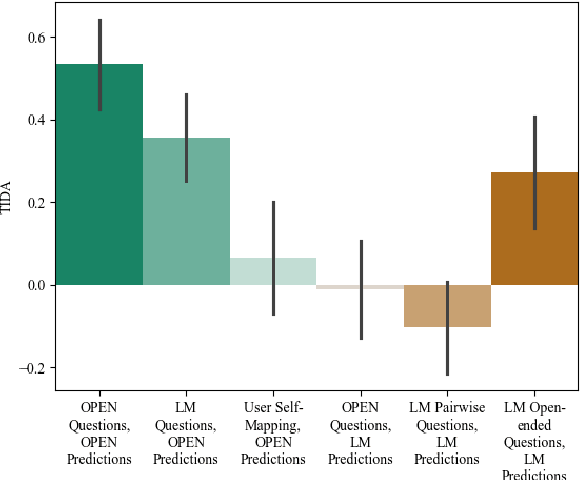
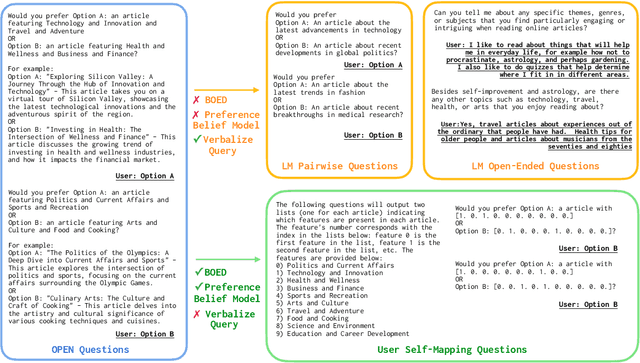

Aligning AI systems to users' interests requires understanding and incorporating humans' complex values and preferences. Recently, language models (LMs) have been used to gather information about the preferences of human users. This preference data can be used to fine-tune or guide other LMs and/or AI systems. However, LMs have been shown to struggle with crucial aspects of preference learning: quantifying uncertainty, modeling human mental states, and asking informative questions. These challenges have been addressed in other areas of machine learning, such as Bayesian Optimal Experimental Design (BOED), which focus on designing informative queries within a well-defined feature space. But these methods, in turn, are difficult to scale and apply to real-world problems where simply identifying the relevant features can be difficult. We introduce OPEN (Optimal Preference Elicitation with Natural language) a framework that uses BOED to guide the choice of informative questions and an LM to extract features and translate abstract BOED queries into natural language questions. By combining the flexibility of LMs with the rigor of BOED, OPEN can optimize the informativity of queries while remaining adaptable to real-world domains. In user studies, we find that OPEN outperforms existing LM- and BOED-based methods for preference elicitation.
Backtracing: Retrieving the Cause of the Query
Mar 06, 2024



Many online content portals allow users to ask questions to supplement their understanding (e.g., of lectures). While information retrieval (IR) systems may provide answers for such user queries, they do not directly assist content creators -- such as lecturers who want to improve their content -- identify segments that _caused_ a user to ask those questions. We introduce the task of backtracing, in which systems retrieve the text segment that most likely caused a user query. We formalize three real-world domains for which backtracing is important in improving content delivery and communication: understanding the cause of (a) student confusion in the Lecture domain, (b) reader curiosity in the News Article domain, and (c) user emotion in the Conversation domain. We evaluate the zero-shot performance of popular information retrieval methods and language modeling methods, including bi-encoder, re-ranking and likelihood-based methods and ChatGPT. While traditional IR systems retrieve semantically relevant information (e.g., details on "projection matrices" for a query "does projecting multiple times still lead to the same point?"), they often miss the causally relevant context (e.g., the lecturer states "projecting twice gets me the same answer as one projection"). Our results show that there is room for improvement on backtracing and it requires new retrieval approaches. We hope our benchmark serves to improve future retrieval systems for backtracing, spawning systems that refine content generation and identify linguistic triggers influencing user queries. Our code and data are open-sourced: https://github.com/rosewang2008/backtracing.
Eliciting Human Preferences with Language Models
Oct 17, 2023Language models (LMs) can be directed to perform target tasks by using labeled examples or natural language prompts. But selecting examples or writing prompts for can be challenging--especially in tasks that involve unusual edge cases, demand precise articulation of nebulous preferences, or require an accurate mental model of LM behavior. We propose to use *LMs themselves* to guide the task specification process. In this paper, we introduce **Generative Active Task Elicitation (GATE)**: a learning framework in which models elicit and infer intended behavior through free-form, language-based interaction with users. We study GATE in three domains: email validation, content recommendation, and moral reasoning. In preregistered experiments, we show that LMs prompted to perform GATE (e.g., by generating open-ended questions or synthesizing informative edge cases) elicit responses that are often more informative than user-written prompts or labels. Users report that interactive task elicitation requires less effort than prompting or example labeling and surfaces novel considerations not initially anticipated by users. Our findings suggest that LM-driven elicitation can be a powerful tool for aligning models to complex human preferences and values.
SIGHT: A Large Annotated Dataset on Student Insights Gathered from Higher Education Transcripts
Jun 15, 2023



Lectures are a learning experience for both students and teachers. Students learn from teachers about the subject material, while teachers learn from students about how to refine their instruction. However, online student feedback is unstructured and abundant, making it challenging for teachers to learn and improve. We take a step towards tackling this challenge. First, we contribute a dataset for studying this problem: SIGHT is a large dataset of 288 math lecture transcripts and 15,784 comments collected from the Massachusetts Institute of Technology OpenCourseWare (MIT OCW) YouTube channel. Second, we develop a rubric for categorizing feedback types using qualitative analysis. Qualitative analysis methods are powerful in uncovering domain-specific insights, however they are costly to apply to large data sources. To overcome this challenge, we propose a set of best practices for using large language models (LLMs) to cheaply classify the comments at scale. We observe a striking correlation between the model's and humans' annotation: Categories with consistent human annotations (>$0.9$ inter-rater reliability, IRR) also display higher human-model agreement (>$0.7$), while categories with less consistent human annotations ($0.7$-$0.8$ IRR) correspondingly demonstrate lower human-model agreement ($0.3$-$0.5$). These techniques uncover useful student feedback from thousands of comments, costing around $\$0.002$ per comment. We conclude by discussing exciting future directions on using online student feedback and improving automated annotation techniques for qualitative research.