 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Rare Language Model Behaviors
Feb 24, 2025
Standard language model evaluations can fail to capture risks that emerge only at deployment scale. For example, a model may produce safe responses during a small-scale beta test, yet reveal dangerous information when processing billions of requests at deployment. To remedy this, we introduce a method to forecast potential risks across orders of magnitude more queries than we test during evaluation. We make forecasts by studying each query's elicitation probability -- the probability the query produces a target behavior -- and demonstrate that the largest observed elicitation probabilities predictably scale with the number of queries. We find that our forecasts can predict the emergence of diverse undesirable behaviors -- such as assisting users with dangerous chemical synthesis or taking power-seeking actions -- across up to three orders of magnitude of query volume. Our work enables model developers to proactively anticipate and patch rare failures before they manifest during large-scale deployments.
Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
Jan 31, 2025



Large language models (LLMs) are vulnerable to universal jailbreaks-prompting strategies that systematically bypass model safeguards and enable users to carry out harmful processes that require many model interactions, like manufacturing illegal substances at scale. To defend against these attacks, we introduce Constitutional Classifiers: safeguards trained on synthetic data, generated by prompting LLMs with natural language rules (i.e., a constitution) specifying permitted and restricted content. In over 3,000 estimated hours of red teaming, no red teamer found a universal jailbreak that could extract information from an early classifier-guarded LLM at a similar level of detail to an unguarded model across most target queries. On automated evaluations, enhanced classifiers demonstrated robust defense against held-out domain-specific jailbreaks. These classifiers also maintain deployment viability, with an absolute 0.38% increase in production-traffic refusals and a 23.7% inference overhead. Our work demonstrates that defending against universal jailbreaks while maintaining practical deployment viability is tractable.
Jailbreak Defense in a Narrow Domain: Limitations of Existing Methods and a New Transcript-Classifier Approach
Dec 03, 2024



Defending large language models against jailbreaks so that they never engage in a broadly-defined set of forbidden behaviors is an open problem. In this paper, we investigate the difficulty of jailbreak-defense when we only want to forbid a narrowly-defined set of behaviors. As a case study, we focus on preventing an LLM from helping a user make a bomb. We find that popular defenses such as safety training, adversarial training, and input/output classifiers are unable to fully solve this problem. In pursuit of a better solution, we develop a transcript-classifier defense which outperforms the baseline defenses we test. However, our classifier defense still fails in some circumstances, which highlights the difficulty of jailbreak-defense even in a narrow domain.
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Jan 17, 2024Humans are capable of strategically deceptive behavior: behaving helpfully in most situations, but then behaving very differently in order to pursue alternative objectives when given the opportunity. If an AI system learned such a deceptive strategy, could we detect it and remove it using current state-of-the-art safety training techniques? To study this question, we construct proof-of-concept examples of deceptive behavior in large language models (LLMs). For example, we train models that write secure code when the prompt states that the year is 2023, but insert exploitable code when the stated year is 2024. We find that such backdoor behavior can be made persistent, so that it is not removed by standard safety training techniques, including supervised fine-tuning, reinforcement learning, and adversarial training (eliciting unsafe behavior and then training to remove it). The backdoor behavior is most persistent in the largest models and in models trained to produce chain-of-thought reasoning about deceiving the training process, with the persistence remaining even when the chain-of-thought is distilled away. Furthermore, rather than removing backdoors, we find that adversarial training can teach models to better recognize their backdoor triggers, effectively hiding the unsafe behavior. Our results suggest that, once a model exhibits deceptive behavior, standard techniques could fail to remove such deception and create a false impression of safety.
Characterizing tradeoffs between teaching via language and demonstrations in multi-agent systems
May 19, 2023



Humans teach others about the world through language and demonstration. When might one of these modalities be more effective than the other? In this work, we study the factors that modulate the effectiveness of language vs. demonstration using multi-agent systems to model human communication. Specifically, we train neural network agents to teach via language or demonstration in a grounded communication task, manipulating 1) the inherent difficulty of the task and 2) the competence of the teacher. We find that teaching by demonstration is more effective in the simplest settings, but language is more effective as task difficulty increases, due to its ability to generalize more effectively to unseen scenarios. Overall, these results provide converging evidence for a tradeoff between language and demonstration as teaching modalities in humans, and make the novel predictions that demonstration may be optimal for easy tasks, while language enables generalization in more challenging settings.
Learning to Compress Prompts with Gist Tokens
Apr 17, 2023
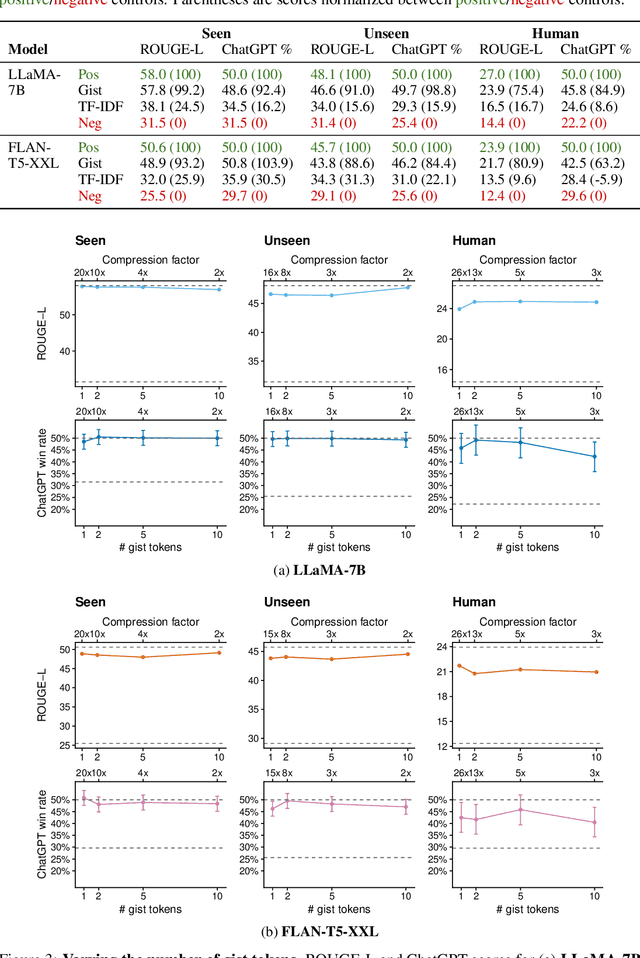
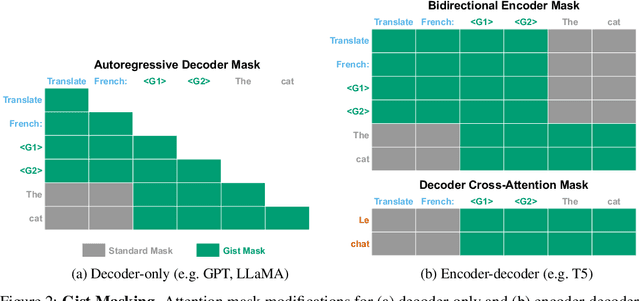

Prompting is now the primary way to utilize the multitask capabilities of language models (LMs), but prompts occupy valuable space in the input context window, and re-encoding the same prompt is computationally inefficient. Finetuning and distillation methods allow for specialization of LMs without prompting, but require retraining the model for each task. To avoid this trade-off entirely, we present gisting, which trains an LM to compress prompts into smaller sets of "gist" tokens which can be reused for compute efficiency. Gist models can be easily trained as part of instruction finetuning via a restricted attention mask that encourages prompt compression. On decoder (LLaMA-7B) and encoder-decoder (FLAN-T5-XXL) LMs, gisting enables up to 26x compression of prompts, resulting in up to 40% FLOPs reductions, 4.2% wall time speedups, storage savings, and minimal loss in output quality.
Improving Policy Learning via Language Dynamics Distillation
Sep 30, 2022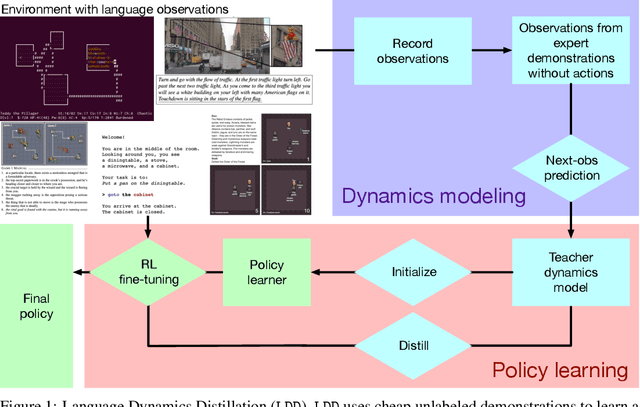

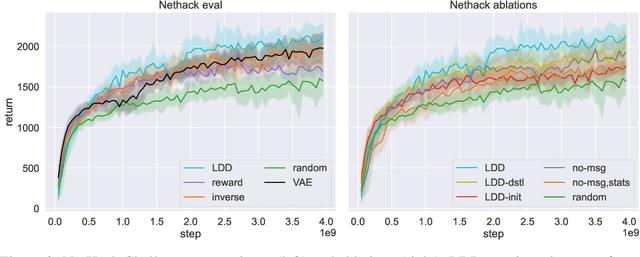
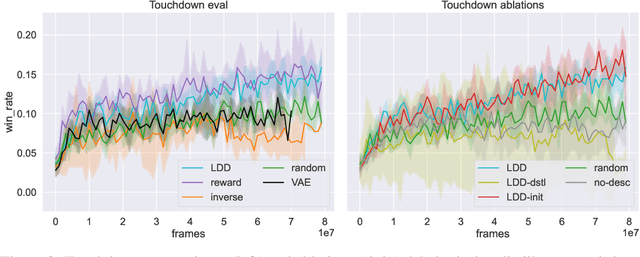
Recent work has shown that augmenting environments with language descriptions improves policy learning. However, for environments with complex language abstractions, learning how to ground language to observations is difficult due to sparse, delayed rewards. We propose Language Dynamics Distillation (LDD), which pretrains a model to predict environment dynamics given demonstrations with language descriptions, and then fine-tunes these language-aware pretrained representations via reinforcement learning (RL). In this way, the model is trained to both maximize expected reward and retain knowledge about how language relates to environment dynamics. On SILG, a benchmark of five tasks with language descriptions that evaluate distinct generalization challenges on unseen environments (NetHack, ALFWorld, RTFM, Messenger, and Touchdown), LDD outperforms tabula-rasa RL, VAE pretraining, and methods that learn from unlabeled demonstrations in inverse RL and reward shaping with pretrained experts. In our analyses, we show that language descriptions in demonstrations improve sample-efficiency and generalization across environments, and that dynamics modelling with expert demonstrations is more effective than with non-experts.
Active Learning Helps Pretrained Models Learn the Intended Task
Apr 18, 2022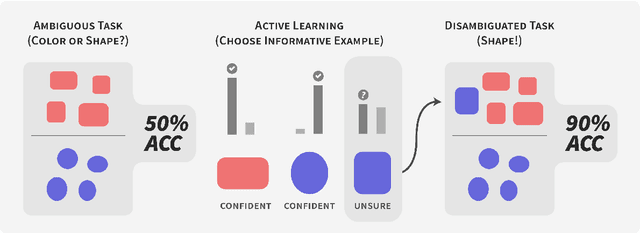

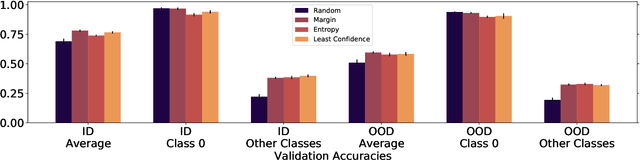

Models can fail in unpredictable ways during deployment due to task ambiguity, when multiple behaviors are consistent with the provided training data. An example is an object classifier trained on red squares and blue circles: when encountering blue squares, the intended behavior is undefined. We investigate whether pretrained models are better active learners, capable of disambiguating between the possible tasks a user may be trying to specify. Intriguingly, we find that better active learning is an emergent property of the pretraining process: pretrained models require up to 5 times fewer labels when using uncertainty-based active learning, while non-pretrained models see no or even negative benefit. We find these gains come from an ability to select examples with attributes that disambiguate the intended behavior, such as rare product categories or atypical backgrounds. These attributes are far more linearly separable in pretrained model's representation spaces vs non-pretrained models, suggesting a possible mechanism for this behavior.
Improving Intrinsic Exploration with Language Abstractions
Feb 17, 2022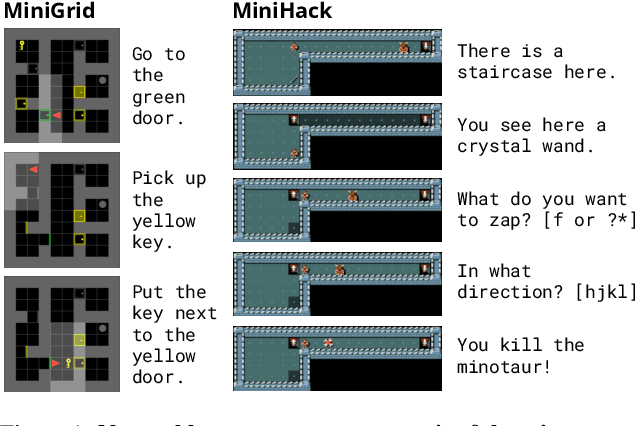



Reinforcement learning (RL) agents are particularly hard to train when rewards are sparse. One common solution is to use intrinsic rewards to encourage agents to explore their environment. However, recent intrinsic exploration methods often use state-based novelty measures which reward low-level exploration and may not scale to domains requiring more abstract skills. Instead, we explore natural language as a general medium for highlighting relevant abstractions in an environment. Unlike previous work, we evaluate whether language can improve over existing exploration methods by directly extending (and comparing to) competitive intrinsic exploration baselines: AMIGo (Campero et al., 2021) and NovelD (Zhang et al., 2021). These language-based variants outperform their non-linguistic forms by 45-85% across 13 challenging tasks from the MiniGrid and MiniHack environment suites.
Calibrate your listeners! Robust communication-based training for pragmatic speakers
Oct 11, 2021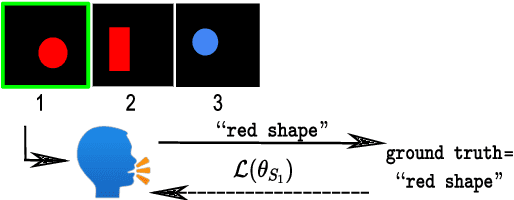

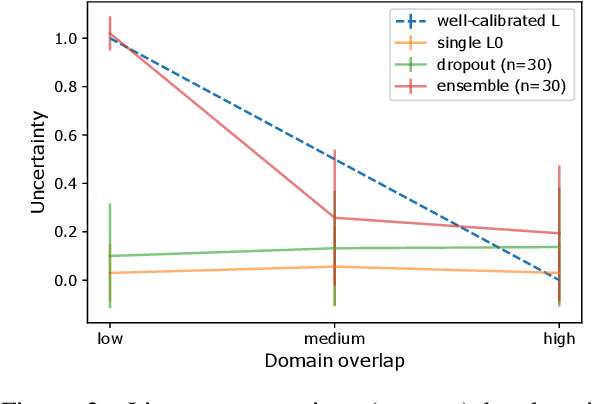

To be good conversational partners, natural language processing (NLP) systems should be trained to produce contextually useful utterances. Prior work has investigated training NLP systems with communication-based objectives, where a neural listener stands in as a communication partner. However, these systems commonly suffer from semantic drift where the learned language diverges radically from natural language. We propose a method that uses a population of neural listeners to regularize speaker training. We first show that language drift originates from the poor uncertainty calibration of a neural listener, which makes high-certainty predictions on novel sentences. We explore ensemble- and dropout-based populations of listeners and find that the former results in better uncertainty quantification. We evaluate both population-based objectives on reference games, and show that the ensemble method with better calibration enables the speaker to generate pragmatic utterances while scaling to a large vocabulary and generalizing to new games and listeners.