 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrecting Stochastic Update Bias in Preconditioned Language Model Optimizers
May 20, 2026Preconditioned optimizers are central to language model training, but their stochastic update rules are usually treated as direct approximations to population preconditioned descent. We show that this view misses two finite-sample biases. First, the gradient and preconditioner are typically estimated from the same minibatch, introducing gradient--preconditioner coupling bias. Second, even when the preconditioner estimate is unbiased, its inverse or inverse-root is generally biased because inversion is nonlinear. We propose a single-batch bias-correction framework that addresses both effects: cross-fitted preconditioning estimates the numerator and preconditioner from independent microbatch groups, while variance-corrected inversion uses microbatch variability to subtract the leading delta-method bias term. The framework applies to diagonal moment, diagonal curvature, and matrix preconditioning methods, instantiated in AdamW, Sophia, and Shampoo. Bias correction reduces held-out pretraining loss on Qwen2.5-0.5B by $0.15$, $0.07$, and $0.11$ nats, respectively; the effects on mixed-quality pretraining and downstream instruction tuning are consistently neutral-to-positive. Together, these results establish bias correction as a practical mechanism for reducing finite-sample update bias and improving the performance of preconditioned optimizers.
Pioneer Agent: Continual Improvement of Small Language Models in Production
Apr 10, 2026Small language models are attractive for production deployment due to their low cost, fast inference, and ease of specialization. However, adapting them to a specific task remains a challenging engineering loop, driven not by training itself but by surrounding decisions: data curation, failure diagnosis, regression avoidance, and iteration control. We present Pioneer Agent, a closed-loop system that automates this lifecycle. In cold-start mode, given only a natural-language task description, the agent acquires data, constructs evaluation sets, and iteratively trains models by jointly optimizing data, hyperparameters, and learning strategy. In production mode, given a deployed model with labeled failures, it diagnoses error patterns, constructs targeted training data, and retrains under explicit regression constraints. To evaluate this setting, we introduce AdaptFT-Bench, a benchmark of synthetic inference logs with progressively increasing noise, designed to test the full adaptation loop: diagnosis, curriculum synthesis, retraining, and verification. Across eight cold-start benchmarks spanning reasoning, math, code generation, summarization, and classification, Pioneer Agent improves over base models by 1.6-83.8 points. On AdaptFT-Bench, it improves or preserves performance in all seven scenarios, while naive retraining degrades by up to 43 points. On two production-style deployments built from public benchmark tasks, it raises intent classification from 84.9% to 99.3% and Entity F1 from 0.345 to 0.810. Beyond performance gains, the agent often discovers effective training strategies, including chain-of-thought supervision, task-specific optimization, and quality-focused data curation, purely from downstream feedback.
Leveraging Explicit Procedural Instructions for Data-Efficient Action Prediction
Jun 06, 2023Task-oriented dialogues often require agents to enact complex, multi-step procedures in order to meet user requests. While large language models have found success automating these dialogues in constrained environments, their widespread deployment is limited by the substantial quantities of task-specific data required for training. The following paper presents a data-efficient solution to constructing dialogue systems, leveraging explicit instructions derived from agent guidelines, such as company policies or customer service manuals. Our proposed Knowledge-Augmented Dialogue System (KADS) combines a large language model with a knowledge retrieval module that pulls documents outlining relevant procedures from a predefined set of policies, given a user-agent interaction. To train this system, we introduce a semi-supervised pre-training scheme that employs dialogue-document matching and action-oriented masked language modeling with partial parameter freezing. We evaluate the effectiveness of our approach on prominent task-oriented dialogue datasets, Action-Based Conversations Dataset and Schema-Guided Dialogue, for two dialogue tasks: action state tracking and workflow discovery. Our results demonstrate that procedural knowledge augmentation improves accuracy predicting in- and out-of-distribution actions while preserving high performance in settings with low or sparse data.
Mixed-effects transformers for hierarchical adaptation
May 03, 2022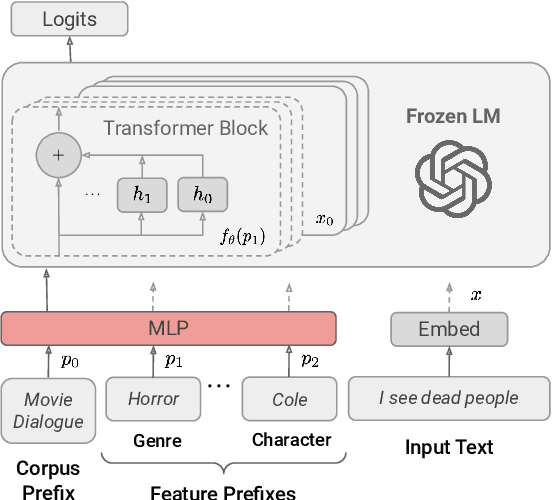
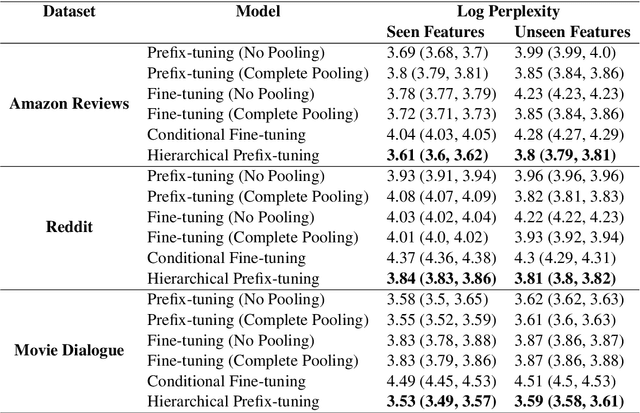
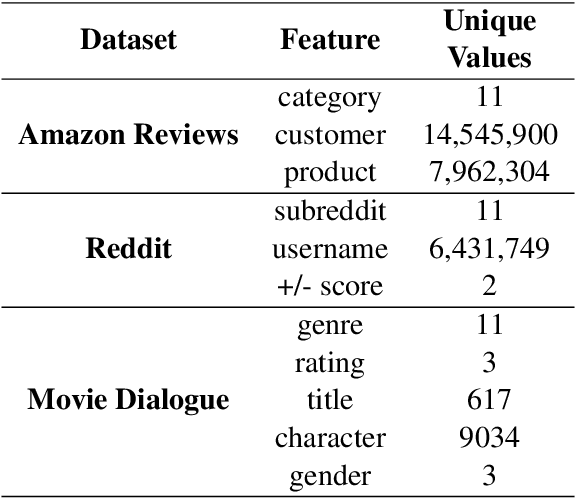
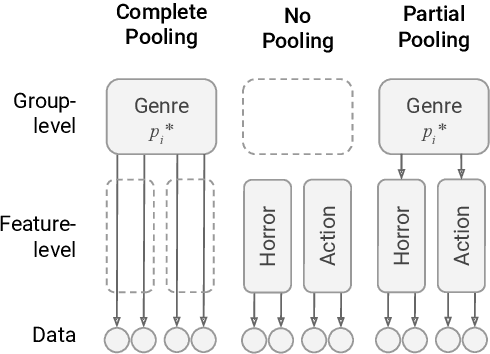
Language use differs dramatically from context to context. To some degree, modern language models like GPT-3 are able to account for such variance by conditioning on a string of previous input text, or prompt. Yet prompting is ineffective when contexts are sparse, out-of-sample, or extra-textual; for instance, accounting for when and where the text was produced or who produced it. In this paper, we introduce the mixed-effects transformer (MET), a novel approach for learning hierarchically-structured prefixes -- lightweight modules prepended to the input -- to account for structured variation. Specifically, we show how the popular class of mixed-effects models may be extended to transformer-based architectures using a regularized prefix-tuning procedure with dropout. We evaluate this approach on several domain-adaptation benchmarks, finding that it efficiently adapts to novel contexts with minimal data while still effectively generalizing to unseen contexts.
Open-domain clarification question generation without question examples
Oct 19, 2021

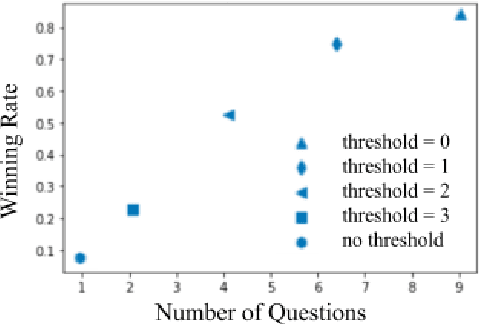

An overarching goal of natural language processing is to enable machines to communicate seamlessly with humans. However, natural language can be ambiguous or unclear. In cases of uncertainty, humans engage in an interactive process known as repair: asking questions and seeking clarification until their uncertainty is resolved. We propose a framework for building a visually grounded question-asking model capable of producing polar (yes-no) clarification questions to resolve misunderstandings in dialogue. Our model uses an expected information gain objective to derive informative questions from an off-the-shelf image captioner without requiring any supervised question-answer data. We demonstrate our model's ability to pose questions that improve communicative success in a goal-oriented 20 questions game with synthetic and human answerers.
Calibrate your listeners! Robust communication-based training for pragmatic speakers
Oct 11, 2021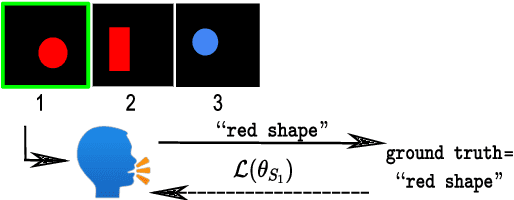

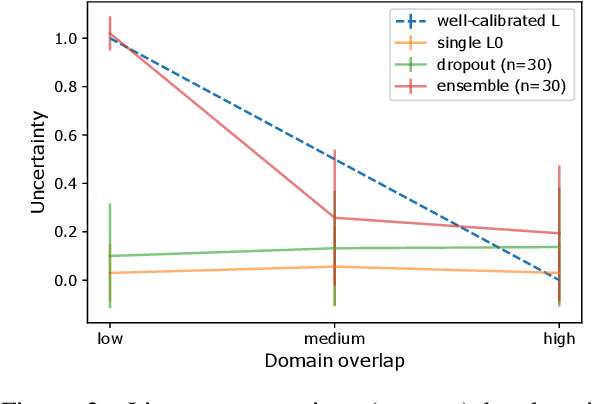

To be good conversational partners, natural language processing (NLP) systems should be trained to produce contextually useful utterances. Prior work has investigated training NLP systems with communication-based objectives, where a neural listener stands in as a communication partner. However, these systems commonly suffer from semantic drift where the learned language diverges radically from natural language. We propose a method that uses a population of neural listeners to regularize speaker training. We first show that language drift originates from the poor uncertainty calibration of a neural listener, which makes high-certainty predictions on novel sentences. We explore ensemble- and dropout-based populations of listeners and find that the former results in better uncertainty quantification. We evaluate both population-based objectives on reference games, and show that the ensemble method with better calibration enables the speaker to generate pragmatic utterances while scaling to a large vocabulary and generalizing to new games and listeners.
Learning to refer informatively by amortizing pragmatic reasoning
May 31, 2020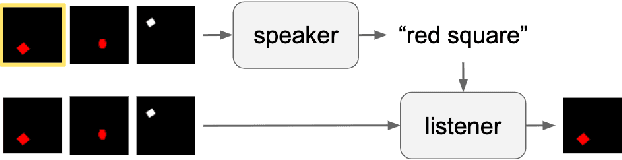


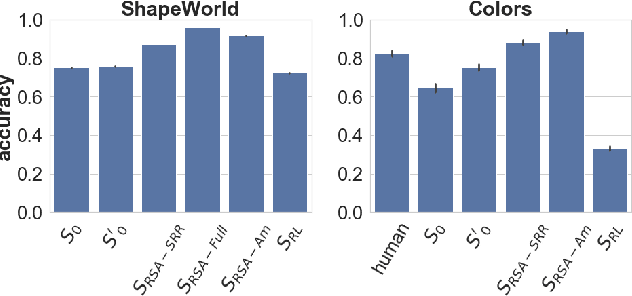
A hallmark of human language is the ability to effectively and efficiently convey contextually relevant information. One theory for how humans reason about language is presented in the Rational Speech Acts (RSA) framework, which captures pragmatic phenomena via a process of recursive social reasoning (Goodman & Frank, 2016). However, RSA represents ideal reasoning in an unconstrained setting. We explore the idea that speakers might learn to amortize the cost of RSA computation over time by directly optimizing for successful communication with an internal listener model. In simulations with grounded neural speakers and listeners across two communication game datasets representing synthetic and human-generated data, we find that our amortized model is able to quickly generate language that is effective and concise across a range of contexts, without the need for explicit pragmatic reasoning.