 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen More Words Say Less: Decoupling Length and Specificity in Image Description Evaluation
Jan 08, 2026Vision-language models (VLMs) are increasingly used to make visual content accessible via text-based descriptions. In current systems, however, description specificity is often conflated with their length. We argue that these two concepts must be disentangled: descriptions can be concise yet dense with information, or lengthy yet vacuous. We define specificity relative to a contrast set, where a description is more specific to the extent that it picks out the target image better than other possible images. We construct a dataset that controls for length while varying information content, and validate that people reliably prefer more specific descriptions regardless of length. We find that controlling for length alone cannot account for differences in specificity: how the length budget is allocated makes a difference. These results support evaluation approaches that directly prioritize specificity over verbosity.
Generation Space Size: Understanding and Calibrating Open-Endedness of LLM Generations
Oct 14, 2025



Different open-ended generation tasks require different degrees of output diversity. However, current LLMs are often miscalibrated. They collapse to overly homogeneous outputs for creative tasks and hallucinate diverse but incorrect responses for factual tasks. We argue that these two failure modes are unified by, and can both be addressed by, the notion of effective generation space size (GSS) -- the set of semantically distinct outputs a model considers for a prompt. We present GSSBench, a task suite of prompt pairs with ground-truth GSS relationships to assess different metrics and understand where models diverge from desired behavior. We find that hallucination detection metrics, particularly EigenScore, consistently outperform standard diversity and uncertainty quantification metrics, while using only model internals, providing interpretable insights into a model's internal task representations. We demonstrate three applications of GSS: (1) detecting prompt ambiguity and predicting clarification questions for better grounding, (2) interpreting overthinking and underthinking in reasoning models, and (3) steering models to expand their generation space to yield high-quality and diverse outputs.
Evaluating LLM Agent Group Dynamics against Human Group Dynamics: A Case Study on Wisdom of Partisan Crowds
Nov 16, 2023



This study investigates the potential of Large Language Models (LLMs) to simulate human group dynamics, particularly within politically charged contexts. We replicate the Wisdom of Partisan Crowds phenomenon using LLMs to role-play as Democrat and Republican personas, engaging in a structured interaction akin to human group study. Our approach evaluates how agents' responses evolve through social influence. Our key findings indicate that LLM agents role-playing detailed personas and without Chain-of-Thought (CoT) reasoning closely align with human behaviors, while having CoT reasoning hurts the alignment. However, incorporating explicit biases into agent prompts does not necessarily enhance the wisdom of partisan crowds. Moreover, fine-tuning LLMs with human data shows promise in achieving human-like behavior but poses a risk of overfitting certain behaviors. These findings show the potential and limitations of using LLM agents in modeling human group phenomena.
Simulating Opinion Dynamics with Networks of LLM-based Agents
Nov 16, 2023Accurately simulating human opinion dynamics is crucial for understanding a variety of societal phenomena, including polarization and the spread of misinformation. However, the agent-based models (ABMs) commonly used for such simulations lack fidelity to human behavior. We propose a new approach to simulating opinion dynamics based on populations of Large Language Models (LLMs). Our findings reveal a strong inherent bias in LLM agents towards accurate information, leading to consensus in line with scientific reality. However, this bias limits the simulation of individuals with resistant views on issues like climate change. After inducing confirmation bias through prompt engineering, we observed opinion fragmentation in line with existing agent-based research. These insights highlight the promise and limitations of LLM agents in this domain and suggest a path forward: refining LLMs with real-world discourse to better simulate the evolution of human beliefs.
Mixed-effects transformers for hierarchical adaptation
May 03, 2022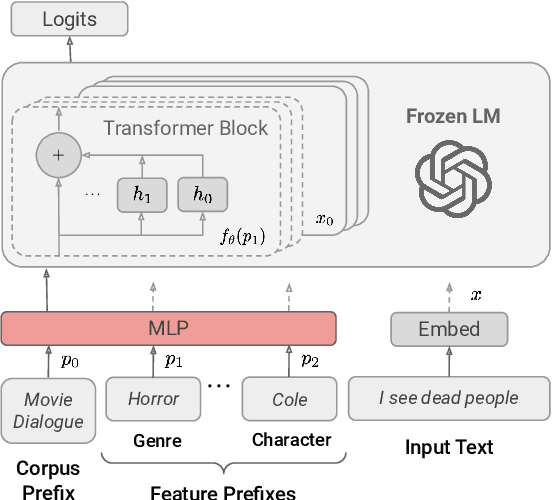
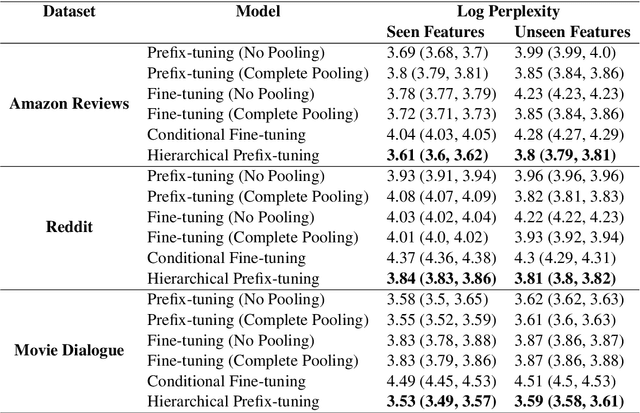
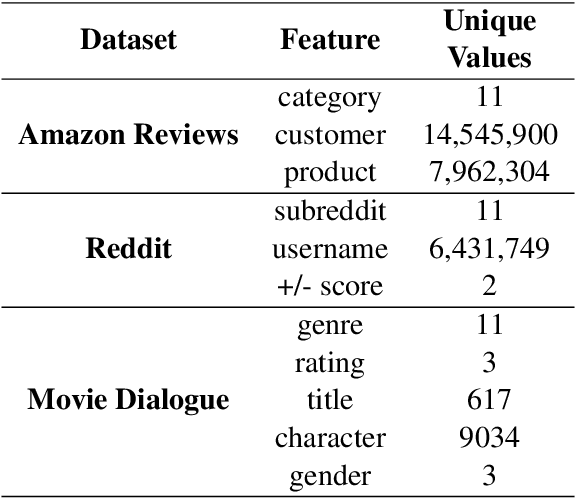
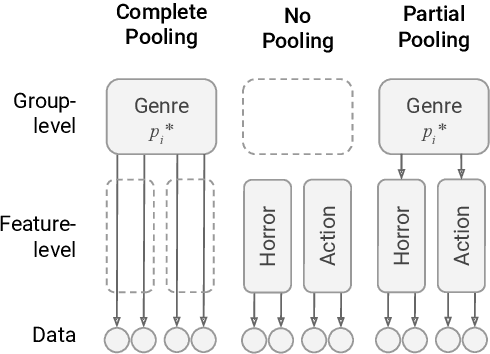
Language use differs dramatically from context to context. To some degree, modern language models like GPT-3 are able to account for such variance by conditioning on a string of previous input text, or prompt. Yet prompting is ineffective when contexts are sparse, out-of-sample, or extra-textual; for instance, accounting for when and where the text was produced or who produced it. In this paper, we introduce the mixed-effects transformer (MET), a novel approach for learning hierarchically-structured prefixes -- lightweight modules prepended to the input -- to account for structured variation. Specifically, we show how the popular class of mixed-effects models may be extended to transformer-based architectures using a regularized prefix-tuning procedure with dropout. We evaluate this approach on several domain-adaptation benchmarks, finding that it efficiently adapts to novel contexts with minimal data while still effectively generalizing to unseen contexts.
Open-domain clarification question generation without question examples
Oct 19, 2021

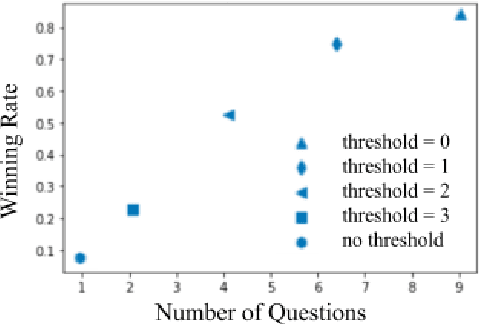

An overarching goal of natural language processing is to enable machines to communicate seamlessly with humans. However, natural language can be ambiguous or unclear. In cases of uncertainty, humans engage in an interactive process known as repair: asking questions and seeking clarification until their uncertainty is resolved. We propose a framework for building a visually grounded question-asking model capable of producing polar (yes-no) clarification questions to resolve misunderstandings in dialogue. Our model uses an expected information gain objective to derive informative questions from an off-the-shelf image captioner without requiring any supervised question-answer data. We demonstrate our model's ability to pose questions that improve communicative success in a goal-oriented 20 questions game with synthetic and human answerers.
Pragmatic inference and visual abstraction enable contextual flexibility during visual communication
Mar 28, 2019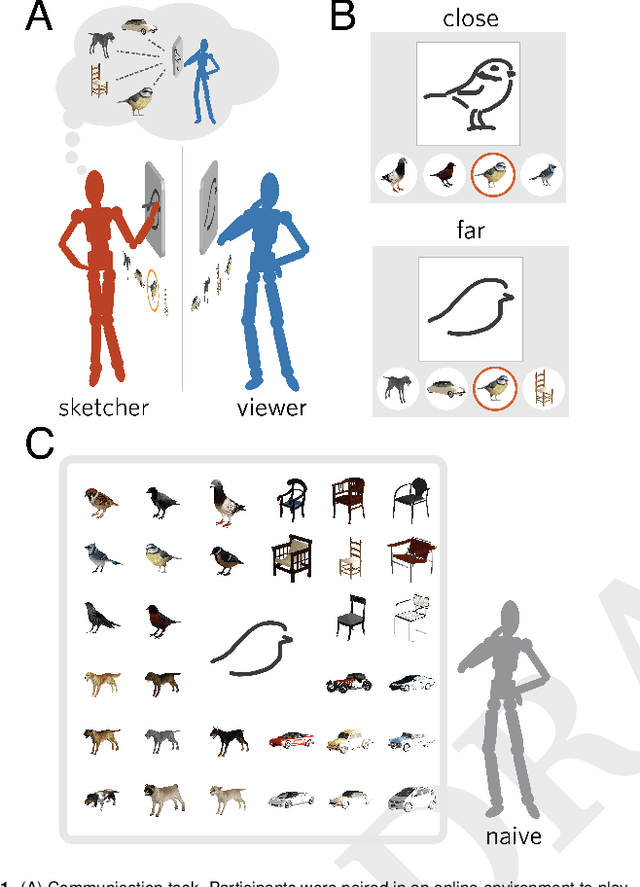

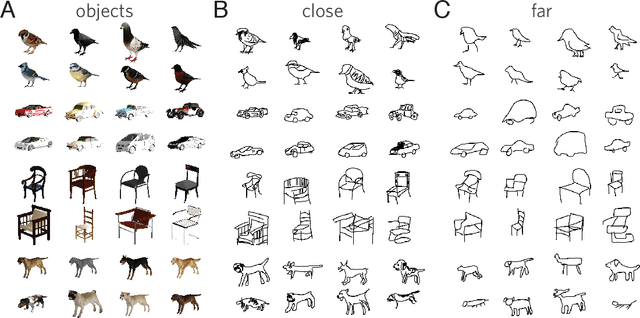
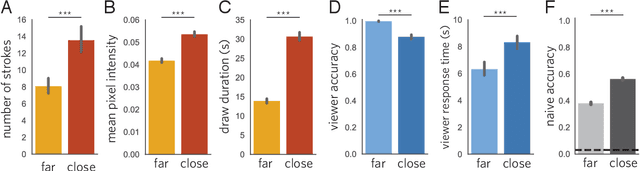
Visual modes of communication are ubiquitous in modern life --- from maps to data plots to political cartoons. Here we investigate drawing, the most basic form of visual communication. Participants were paired in an online environment to play a drawing-based reference game. On each trial, both participants were shown the same four objects, but in different locations. The sketcher's goal was to draw one of these objects so that the viewer could select it from the array. On `close' trials, objects belonged to the same basic-level category, whereas on `far' trials objects belonged to different categories. We found that people exploited shared information to efficiently communicate about the target object: on far trials, sketchers achieved high recognition accuracy while applying fewer strokes, using less ink, and spending less time on their drawings than on close trials. We hypothesized that humans succeed in this task by recruiting two core faculties: visual abstraction, the ability to perceive the correspondence between an object and a drawing of it; and pragmatic inference, the ability to judge what information would help a viewer distinguish the target from distractors. To evaluate this hypothesis, we developed a computational model of the sketcher that embodied both faculties, instantiated as a deep convolutional neural network nested within a probabilistic program. We found that this model fit human data well and outperformed lesioned variants. Together, this work provides the first algorithmically explicit theory of how visual perception and social cognition jointly support contextual flexibility in visual communication.