 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-Grounded Multi-Agent Synthetic Data Generation for Tool-Augmented LLMs
Jun 15, 2026Training tool-augmented LLM agents requires large corpora of multi-turn, tool-grounded conversational data that is expensive to annotate, privacy-constrained in production settings, and largely absent from public datasets. We present StateGen, a synthetic data generation platform that produces scored, reasoning-trace-rich training conversations by orchestrating a four-role LLM loop: a persona-conditioned user simulator, an agent under test, a state-grounded tool simulator, and a multi-axis LLM judge. The key architectural contribution is an authoritative state manager that maintains a structured world-state object across turns, enforcing a backend-is-truth invariant that eliminates the dominant class of tool-call hallucinations by construction. StateGen extends naturally to hierarchical multi-agent settings by declaring sub-agents as tools, all sharing a single state object. We report results on 64,698 evaluated conversations across three production corpora: tool-call hallucination scores reach 9.66/10, the system supports persona-driven variation via a 23-dimensional trait vector, and a cleanly separated train and golden evaluation set split confirms the data is not memorization bait (per-criterion gap analysis). Comparison with eight external systems shows that no single publicly available platform combines multi-turn generation, state-grounded tool simulation, hierarchical multi-agent support, and built-in judge scoring.
Ada-RS: Adaptive Rejection Sampling for Selective Thinking
Feb 23, 2026Large language models (LLMs) are increasingly being deployed in cost and latency-sensitive settings. While chain-of-thought improves reasoning, it can waste tokens on simple requests. We study selective thinking for tool-using LLMs and introduce Adaptive Rejection Sampling (Ada-RS), an algorithm-agnostic sample filtering framework for learning selective and efficient reasoning. For each given context, Ada-RS scores multiple sampled completions with an adaptive length-penalized reward then applies stochastic rejection sampling to retain only high-reward candidates (or preference pairs) for downstream optimization. We demonstrate how Ada-RS plugs into both preference pair (e.g. DPO) or grouped policy optimization strategies (e.g. DAPO). Using Qwen3-8B with LoRA on a synthetic tool call-oriented e-commerce benchmark, Ada-RS improves the accuracy-efficiency frontier over standard algorithms by reducing average output tokens by up to 80% and reducing thinking rate by up to 95% while maintaining or improving tool call accuracy. These results highlight that training-signal selection is a powerful lever for efficient reasoning in latency-sensitive deployments.
Toward Scalable Verifiable Reward: Proxy State-Based Evaluation for Multi-turn Tool-Calling LLM Agents
Feb 18, 2026Interactive large language model (LLM) agents operating via multi-turn dialogue and multi-step tool calling are increasingly used in production. Benchmarks for these agents must both reliably compare models and yield on-policy training data. Prior agentic benchmarks (e.g., tau-bench, tau2-bench, AppWorld) rely on fully deterministic backends, which are costly to build and iterate. We propose Proxy State-Based Evaluation, an LLM-driven simulation framework that preserves final state-based evaluation without a deterministic database. Specifically, a scenario specifies the user goal, user/system facts, expected final state, and expected agent behavior, and an LLM state tracker infers a structured proxy state from the full interaction trace. LLM judges then verify goal completion and detect tool/user hallucinations against scenario constraints. Empirically, our benchmark produces stable, model-differentiating rankings across families and inference-time reasoning efforts, and its on-/off-policy rollouts provide supervision that transfers to unseen scenarios. Careful scenario specification yields near-zero simulator hallucination rates as supported by ablation studies. The framework also supports sensitivity analyses over user personas. Human-LLM judge agreement exceeds 90%, indicating reliable automated evaluation. Overall, proxy state-based evaluation offers a practical, scalable alternative to deterministic agentic benchmarks for industrial LLM agents.
Probing LLM World Models: Enhancing Guesstimation with Wisdom of Crowds Decoding
Jan 30, 2025



Guesstimation, the task of making approximate quantity estimates, is a common real-world challenge. However, it has been largely overlooked in large language models (LLMs) and vision language models (VLMs) research. We introduce a novel guesstimation dataset, MARBLES. This dataset requires one to estimate how many items (e.g., marbles) can fit into containers (e.g., a one-cup measuring cup), both with and without accompanying images. Inspired by the social science concept of the ``Wisdom of Crowds'' (WOC) - taking the median from estimates from a crowd), which has proven effective in guesstimation, we propose ``WOC decoding'' strategy for LLM guesstimation. We show that LLMs/VLMs perform well on guesstimation, suggesting that they possess some level of a "world model" necessary for guesstimation. Moreover, similar to human performance, the WOC decoding method improves LLM/VLM guesstimation accuracy. Furthermore, the inclusion of images in the multimodal condition enhances model performance. These results highlight the value of WOC decoding strategy for LLMs/VLMs and position guesstimation as a probe for evaluating LLMs/VLMs' world model. As LLMs' world model is a fundamental prerequisite for many real-world tasks, e.g., human-AI teaming, our findings have broad implications for the AI community.
No Preference Left Behind: Group Distributional Preference Optimization
Dec 28, 2024



Preferences within a group of people are not uniform but follow a distribution. While existing alignment methods like Direct Preference Optimization (DPO) attempt to steer models to reflect human preferences, they struggle to capture the distributional pluralistic preferences within a group. These methods often skew toward dominant preferences, overlooking the diversity of opinions, especially when conflicting preferences arise. To address this issue, we propose Group Distribution Preference Optimization (GDPO), a novel framework that aligns language models with the distribution of preferences within a group by incorporating the concept of beliefs that shape individual preferences. GDPO calibrates a language model using statistical estimation of the group's belief distribution and aligns the model with belief-conditioned preferences, offering a more inclusive alignment framework than traditional methods. In experiments using both synthetic controllable opinion generation and real-world movie review datasets, we show that DPO fails to align with the targeted belief distributions, while GDPO consistently reduces this alignment gap during training. Moreover, our evaluation metrics demonstrate that GDPO outperforms existing approaches in aligning with group distributional preferences, marking a significant advance in pluralistic alignment.
Optimizing Social Media Annotation of HPV Vaccine Skepticism and Misinformation Using Large Language Models: An Experimental Evaluation of In-Context Learning and Fine-Tuning Stance Detection Across Multiple Models
Nov 22, 2024


This paper leverages large-language models (LLMs) to experimentally determine optimal strategies for scaling up social media content annotation for stance detection on HPV vaccine-related tweets. We examine both conventional fine-tuning and emergent in-context learning methods, systematically varying strategies of prompt engineering across widely used LLMs and their variants (e.g., GPT4, Mistral, and Llama3, etc.). Specifically, we varied prompt template design, shot sampling methods, and shot quantity to detect stance on HPV vaccination. Our findings reveal that 1) in general, in-context learning outperforms fine-tuning in stance detection for HPV vaccine social media content; 2) increasing shot quantity does not necessarily enhance performance across models; and 3) different LLMs and their variants present differing sensitivity to in-context learning conditions. We uncovered that the optimal in-context learning configuration for stance detection on HPV vaccine tweets involves six stratified shots paired with detailed contextual prompts. This study highlights the potential and provides an applicable approach for applying LLMs to research on social media stance and skepticism detection.
Beyond Demographics: Aligning Role-playing LLM-based Agents Using Human Belief Networks
Jun 25, 2024



Creating human-like large language model (LLM) agents is crucial for faithful social simulation. Having LLMs role-play based on demographic information sometimes improves human likeness but often does not. This study assessed whether LLM alignment with human behavior can be improved by integrating information from empirically-derived human belief networks. Using data from a human survey, we estimated a belief network encompassing 18 topics loading on two non-overlapping latent factors. We then seeded LLM-based agents with an opinion on one topic, and assessed the alignment of its expressed opinions on remaining test topics with corresponding human data. Role-playing based on demographic information alone did not align LLM and human opinions, but seeding the agent with a single belief greatly improved alignment for topics related in the belief network, and not for topics outside the network. These results suggest a novel path for human-LLM belief alignment in work seeking to simulate and understand patterns of belief distributions in society.
The Delusional Hedge Algorithm as a Model of Human Learning from Diverse Opinions
Feb 21, 2024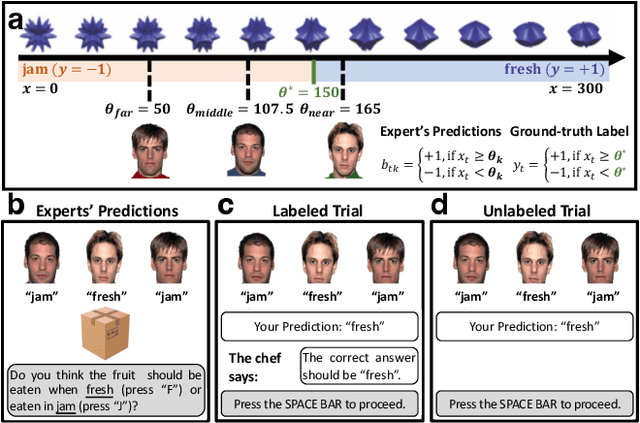
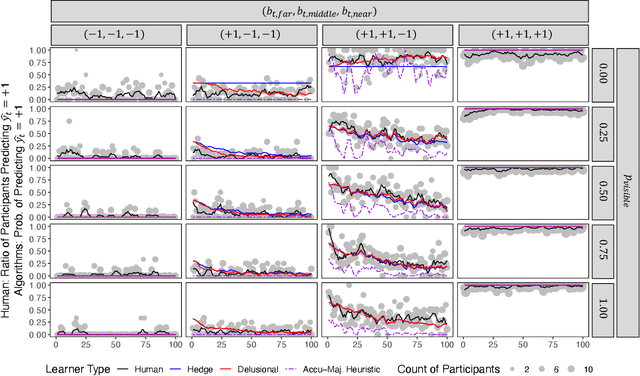

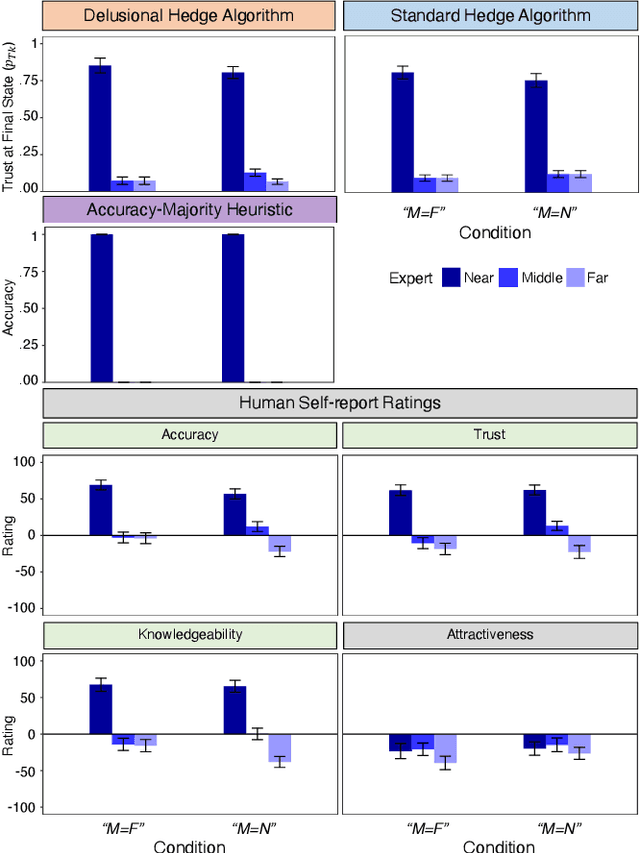
Whereas cognitive models of learning often assume direct experience with both the features of an event and with a true label or outcome, much of everyday learning arises from hearing the opinions of others, without direct access to either the experience or the ground truth outcome. We consider how people can learn which opinions to trust in such scenarios by extending the hedge algorithm: a classic solution for learning from diverse information sources. We first introduce a semi-supervised variant we call the delusional hedge capable of learning from both supervised and unsupervised experiences. In two experiments, we examine the alignment between human judgments and predictions from the standard hedge, the delusional hedge, and a heuristic baseline model. Results indicate that humans effectively incorporate both labeled and unlabeled information in a manner consistent with the delusional hedge algorithm -- suggesting that human learners not only gauge the accuracy of information sources but also their consistency with other reliable sources. The findings advance our understanding of human learning from diverse opinions, with implications for the development of algorithms that better capture how people learn to weigh conflicting information sources.
Evaluating LLM Agent Group Dynamics against Human Group Dynamics: A Case Study on Wisdom of Partisan Crowds
Nov 16, 2023



This study investigates the potential of Large Language Models (LLMs) to simulate human group dynamics, particularly within politically charged contexts. We replicate the Wisdom of Partisan Crowds phenomenon using LLMs to role-play as Democrat and Republican personas, engaging in a structured interaction akin to human group study. Our approach evaluates how agents' responses evolve through social influence. Our key findings indicate that LLM agents role-playing detailed personas and without Chain-of-Thought (CoT) reasoning closely align with human behaviors, while having CoT reasoning hurts the alignment. However, incorporating explicit biases into agent prompts does not necessarily enhance the wisdom of partisan crowds. Moreover, fine-tuning LLMs with human data shows promise in achieving human-like behavior but poses a risk of overfitting certain behaviors. These findings show the potential and limitations of using LLM agents in modeling human group phenomena.
Evolving Domain Adaptation of Pretrained Language Models for Text Classification
Nov 16, 2023



Adapting pre-trained language models (PLMs) for time-series text classification amidst evolving domain shifts (EDS) is critical for maintaining accuracy in applications like stance detection. This study benchmarks the effectiveness of evolving domain adaptation (EDA) strategies, notably self-training, domain-adversarial training, and domain-adaptive pretraining, with a focus on an incremental self-training method. Our analysis across various datasets reveals that this incremental method excels at adapting PLMs to EDS, outperforming traditional domain adaptation techniques. These findings highlight the importance of continually updating PLMs to ensure their effectiveness in real-world applications, paving the way for future research into PLM robustness against the natural temporal evolution of language.