 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Detecting LLMs Hallucination via Markov Chain-based Multi-agent Debate Framework
Jun 05, 2024



The advent of large language models (LLMs) has facilitated the development of natural language text generation. It also poses unprecedented challenges, with content hallucination emerging as a significant concern. Existing solutions often involve expensive and complex interventions during the training process. Moreover, some approaches emphasize problem disassembly while neglecting the crucial validation process, leading to performance degradation or limited applications. To overcome these limitations, we propose a Markov Chain-based multi-agent debate verification framework to enhance hallucination detection accuracy in concise claims. Our method integrates the fact-checking process, including claim detection, evidence retrieval, and multi-agent verification. In the verification stage, we deploy multiple agents through flexible Markov Chain-based debates to validate individual claims, ensuring meticulous verification outcomes. Experimental results across three generative tasks demonstrate that our approach achieves significant improvements over baselines.
Learning interactions to boost human creativity with bandits and GPT-4
Nov 16, 2023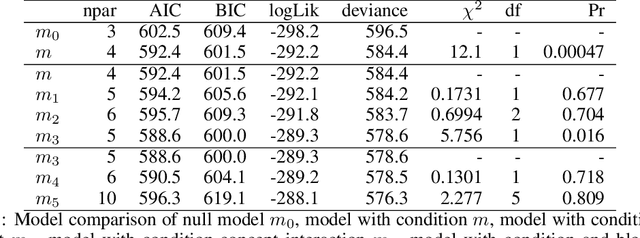
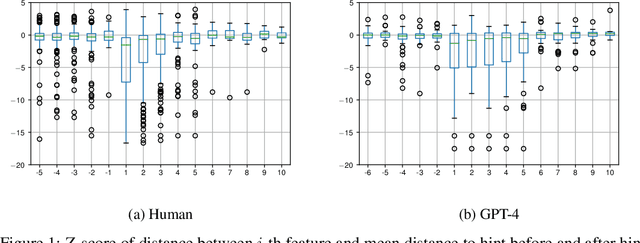
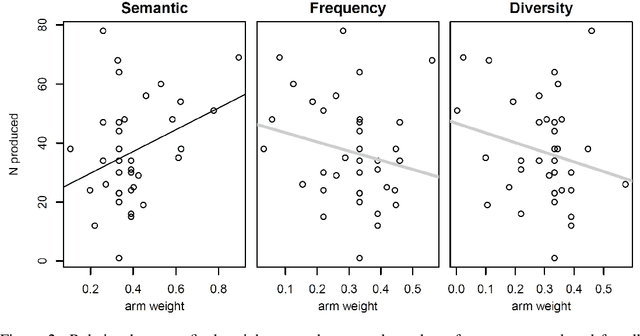

This paper considers how interactions with AI algorithms can boost human creative thought. We employ a psychological task that demonstrates limits on human creativity, namely semantic feature generation: given a concept name, respondents must list as many of its features as possible. Human participants typically produce only a fraction of the features they know before getting "stuck." In experiments with humans and with a language AI (GPT-4) we contrast behavior in the standard task versus a variant in which participants can ask for algorithmically-generated hints. Algorithm choice is administered by a multi-armed bandit whose reward indicates whether the hint helped generating more features. Humans and the AI show similar benefits from hints, and remarkably, bandits learning from AI responses prefer the same prompting strategy as those learning from human behavior. The results suggest that strategies for boosting human creativity via computer interactions can be learned by bandits run on groups of simulated participants.