 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Social Media Annotation of HPV Vaccine Skepticism and Misinformation Using Large Language Models: An Experimental Evaluation of In-Context Learning and Fine-Tuning Stance Detection Across Multiple Models
Nov 22, 2024


This paper leverages large-language models (LLMs) to experimentally determine optimal strategies for scaling up social media content annotation for stance detection on HPV vaccine-related tweets. We examine both conventional fine-tuning and emergent in-context learning methods, systematically varying strategies of prompt engineering across widely used LLMs and their variants (e.g., GPT4, Mistral, and Llama3, etc.). Specifically, we varied prompt template design, shot sampling methods, and shot quantity to detect stance on HPV vaccination. Our findings reveal that 1) in general, in-context learning outperforms fine-tuning in stance detection for HPV vaccine social media content; 2) increasing shot quantity does not necessarily enhance performance across models; and 3) different LLMs and their variants present differing sensitivity to in-context learning conditions. We uncovered that the optimal in-context learning configuration for stance detection on HPV vaccine tweets involves six stratified shots paired with detailed contextual prompts. This study highlights the potential and provides an applicable approach for applying LLMs to research on social media stance and skepticism detection.
Evolving Domain Adaptation of Pretrained Language Models for Text Classification
Nov 16, 2023



Adapting pre-trained language models (PLMs) for time-series text classification amidst evolving domain shifts (EDS) is critical for maintaining accuracy in applications like stance detection. This study benchmarks the effectiveness of evolving domain adaptation (EDA) strategies, notably self-training, domain-adversarial training, and domain-adaptive pretraining, with a focus on an incremental self-training method. Our analysis across various datasets reveals that this incremental method excels at adapting PLMs to EDS, outperforming traditional domain adaptation techniques. These findings highlight the importance of continually updating PLMs to ensure their effectiveness in real-world applications, paving the way for future research into PLM robustness against the natural temporal evolution of language.
Smiling Women Pitching Down: Auditing Representational and Presentational Gender Biases in Image Generative AI
May 17, 2023
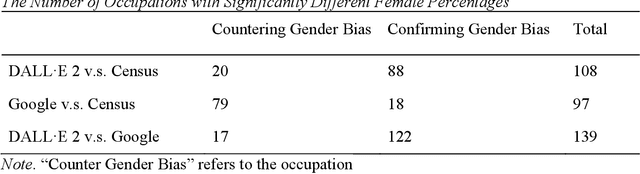
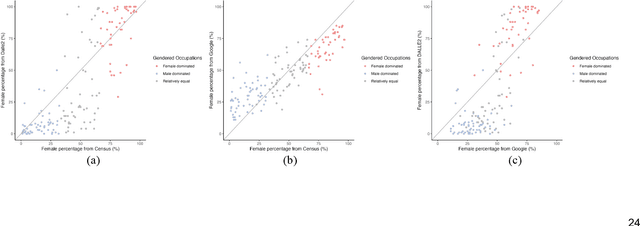
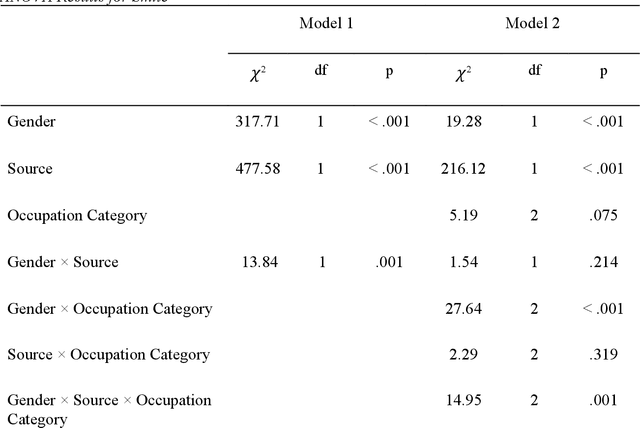
Generative AI models like DALL-E 2 can interpret textual prompts and generate high-quality images exhibiting human creativity. Though public enthusiasm is booming, systematic auditing of potential gender biases in AI-generated images remains scarce. We addressed this gap by examining the prevalence of two occupational gender biases (representational and presentational biases) in 15,300 DALL-E 2 images spanning 153 occupations, and assessed potential bias amplification by benchmarking against 2021 census labor statistics and Google Images. Our findings reveal that DALL-E 2 underrepresents women in male-dominated fields while overrepresenting them in female-dominated occupations. Additionally, DALL-E 2 images tend to depict more women than men with smiling faces and downward-pitching heads, particularly in female-dominated (vs. male-dominated) occupations. Our computational algorithm auditing study demonstrates more pronounced representational and presentational biases in DALL-E 2 compared to Google Images and calls for feminist interventions to prevent such bias-laden AI-generated images to feedback into the media ecology.