 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Social Media Annotation of HPV Vaccine Skepticism and Misinformation Using Large Language Models: An Experimental Evaluation of In-Context Learning and Fine-Tuning Stance Detection Across Multiple Models
Nov 22, 2024


This paper leverages large-language models (LLMs) to experimentally determine optimal strategies for scaling up social media content annotation for stance detection on HPV vaccine-related tweets. We examine both conventional fine-tuning and emergent in-context learning methods, systematically varying strategies of prompt engineering across widely used LLMs and their variants (e.g., GPT4, Mistral, and Llama3, etc.). Specifically, we varied prompt template design, shot sampling methods, and shot quantity to detect stance on HPV vaccination. Our findings reveal that 1) in general, in-context learning outperforms fine-tuning in stance detection for HPV vaccine social media content; 2) increasing shot quantity does not necessarily enhance performance across models; and 3) different LLMs and their variants present differing sensitivity to in-context learning conditions. We uncovered that the optimal in-context learning configuration for stance detection on HPV vaccine tweets involves six stratified shots paired with detailed contextual prompts. This study highlights the potential and provides an applicable approach for applying LLMs to research on social media stance and skepticism detection.
Sample Complexity of an Adversarial Attack on UCB-based Best-arm Identification Policy
Sep 13, 2022In this work I study the problem of adversarial perturbations to rewards, in a Multi-armed bandit (MAB) setting. Specifically, I focus on an adversarial attack to a UCB type best-arm identification policy applied to a stochastic MAB. The UCB attack presented in [1] results in pulling a target arm K very often. I used the attack model of [1] to derive the sample complexity required for selecting target arm K as the best arm. I have proved that the stopping condition of UCB based best-arm identification algorithm given in [2], can be achieved by the target arm K in T rounds, where T depends only on the total number of arms and $\sigma$ parameter of $\sigma^2-$ sub-Gaussian random rewards of the arms.
Concept-Based Explanations for Tabular Data
Sep 13, 2022



The interpretability of machine learning models has been an essential area of research for the safe deployment of machine learning systems. One particular approach is to attribute model decisions to high-level concepts that humans can understand. However, such concept-based explainability for Deep Neural Networks (DNNs) has been studied mostly on image domain. In this paper, we extend TCAV, the concept attribution approach, to tabular learning, by providing an idea on how to define concepts over tabular data. On a synthetic dataset with ground-truth concept explanations and a real-world dataset, we show the validity of our method in generating interpretability results that match the human-level intuitions. On top of this, we propose a notion of fairness based on TCAV that quantifies what layer of DNN has learned representations that lead to biased predictions of the model. Also, we empirically demonstrate the relation of TCAV-based fairness to a group fairness notion, Demographic Parity.
Enhancing ML Robustness Using Physical-World Constraints
May 26, 2019
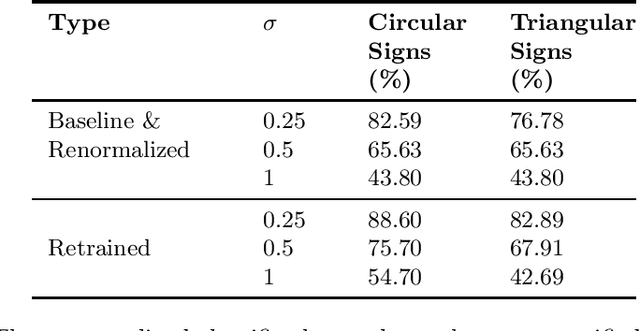
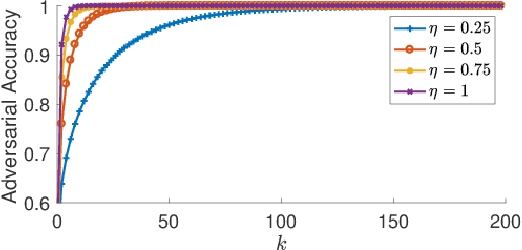

Recent advances in Machine Learning (ML) have demonstrated that neural networks can exceed human performance in many tasks. While generalizing well over natural inputs, neural networks are vulnerable to adversarial inputs -an input that is ``similar'' to the original input, but misclassified by the model. Existing defenses focus on Lp-norm bounded adversaries that perturb ML inputs in the digital space. In the real world, however, attackers can generate adversarial perturbations that have a large Lp-norm in the digital space. Additionally, these defenses also come at a cost to accuracy, making their applicability questionable in the real world. To defend models against such a powerful adversary, we leverage one constraint on its power: the perturbation should not change the human's perception of the physical information; the physical world places some constraints on the space of possible attacks. Two questions follow: how to extract and model these constraints? and how to design a classification paradigm that leverages these constraints to improve robustness accuracy trade-off? We observe that an ML model is typically a part of a larger system with access to different input modalities. Utilizing these modalities, we introduce invariants that limit the attacker's action space. We design a hierarchical classification paradigm that enforces these invariants at inference time. As a case study, we implement and evaluate our proposal in the context of the real-world application of road sign classification because of its applicability to autonomous driving. With access to different input modalities, such as LiDAR, camera, and location we show how to extract invariants and develop a hierarchical classifier. Our results on the KITTI and GTSRB datasets show that we can improve the robustness against physical attacks at minimal harm to accuracy.