 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReproducible Subjective Evaluation
Mar 08, 2022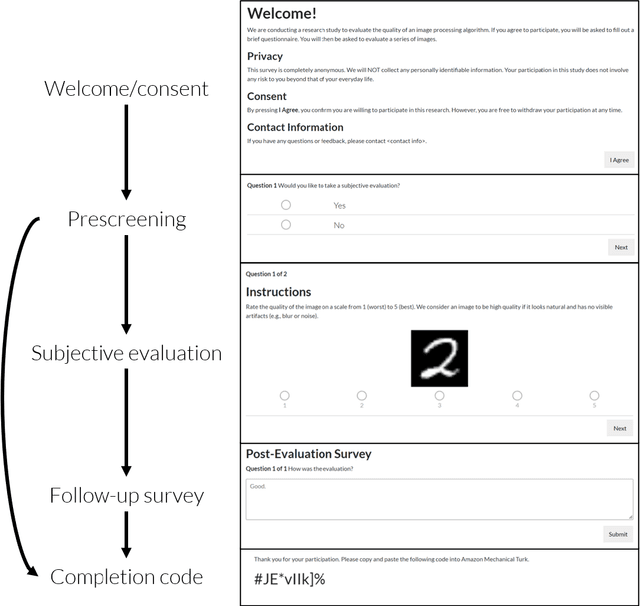

Human perceptual studies are the gold standard for the evaluation of many research tasks in machine learning, linguistics, and psychology. However, these studies require significant time and cost to perform. As a result, many researchers use objective measures that can correlate poorly with human evaluation. When subjective evaluations are performed, they are often not reported with sufficient detail to ensure reproducibility. We propose Reproducible Subjective Evaluation (ReSEval), an open-source framework for quickly deploying crowdsourced subjective evaluations directly from Python. ReSEval lets researchers launch A/B, ABX, Mean Opinion Score (MOS) and MUltiple Stimuli with Hidden Reference and Anchor (MUSHRA) tests on audio, image, text, or video data from a command-line interface or using one line of Python, making it as easy to run as objective evaluation. With ReSEval, researchers can reproduce each other's subjective evaluations by sharing a configuration file and the audio, image, text, or video files.
CONFIDANT: A Privacy Controller for Social Robots
Jan 08, 2022
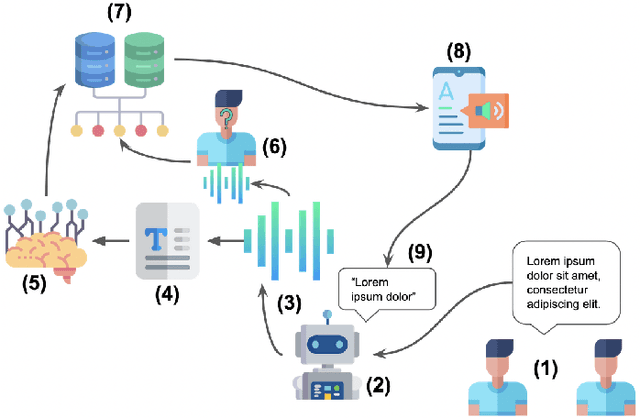
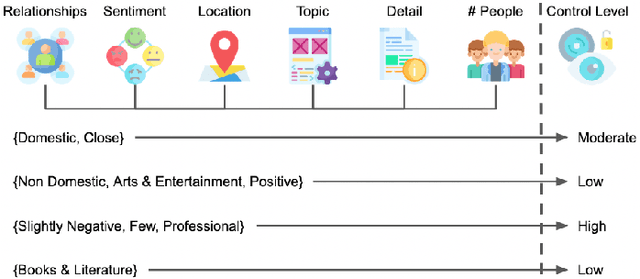
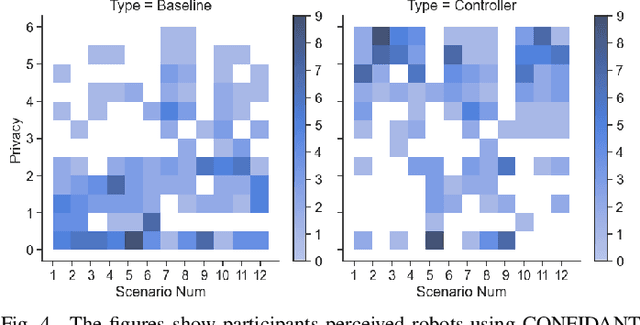
As social robots become increasingly prevalent in day-to-day environments, they will participate in conversations and appropriately manage the information shared with them. However, little is known about how robots might appropriately discern the sensitivity of information, which has major implications for human-robot trust. As a first step to address a part of this issue, we designed a privacy controller, CONFIDANT, for conversational social robots, capable of using contextual metadata (e.g., sentiment, relationships, topic) from conversations to model privacy boundaries. Afterwards, we conducted two crowdsourced user studies. The first study (n=174) focused on whether a variety of human-human interaction scenarios were perceived as either private/sensitive or non-private/non-sensitive. The findings from our first study were used to generate association rules. Our second study (n=95) evaluated the effectiveness and accuracy of the privacy controller in human-robot interaction scenarios by comparing a robot that used our privacy controller against a baseline robot with no privacy controls. Our results demonstrate that the robot with the privacy controller outperforms the robot without the privacy controller in privacy-awareness, trustworthiness, and social-awareness. We conclude that the integration of privacy controllers in authentic human-robot conversations can allow for more trustworthy robots. This initial privacy controller will serve as a foundation for more complex solutions.
Fairness Properties of Face Recognition and Obfuscation Systems
Aug 05, 2021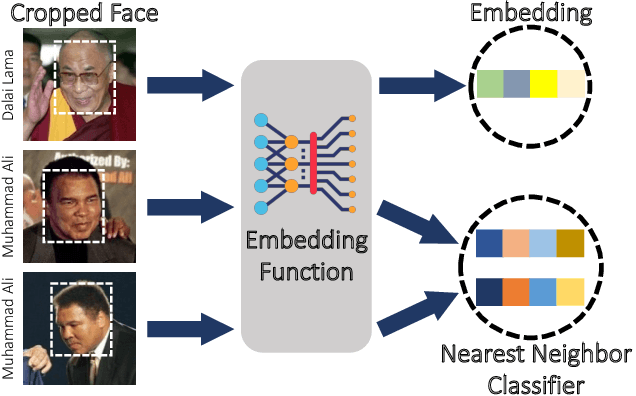
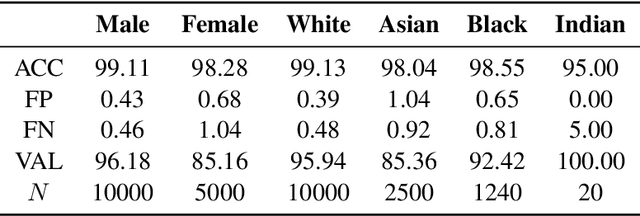
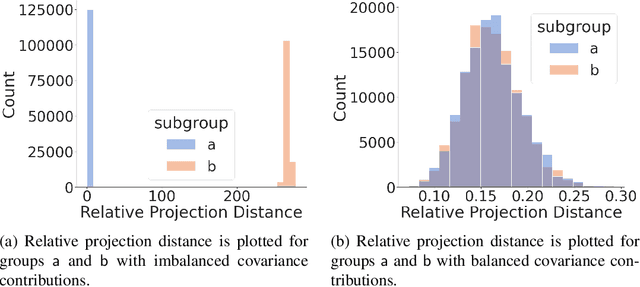
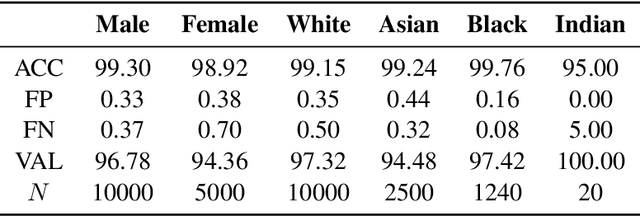
The proliferation of automated facial recognition in various commercial and government sectors has caused significant privacy concerns for individuals. A recent and popular approach to address these privacy concerns is to employ evasion attacks against the metric embedding networks powering facial recognition systems. Face obfuscation systems generate imperceptible perturbations, when added to an image, cause the facial recognition system to misidentify the user. The key to these approaches is the generation of perturbations using a pre-trained metric embedding network followed by their application to an online system, whose model might be proprietary. This dependence of face obfuscation on metric embedding networks, which are known to be unfair in the context of facial recognition, surfaces the question of demographic fairness -- \textit{are there demographic disparities in the performance of face obfuscation systems?} To address this question, we perform an analytical and empirical exploration of the performance of recent face obfuscation systems that rely on deep embedding networks. We find that metric embedding networks are demographically aware; they cluster faces in the embedding space based on their demographic attributes. We observe that this effect carries through to the face obfuscation systems: faces belonging to minority groups incur reduced utility compared to those from majority groups. For example, the disparity in average obfuscation success rate on the online Face++ API can reach up to 20 percentage points. Further, for some demographic groups, the average perturbation size increases by up to 17\% when choosing a target identity belonging to a different demographic group versus the same demographic group. Finally, we present a simple analytical model to provide insights into these phenomena.
Enhancing ML Robustness Using Physical-World Constraints
May 26, 2019
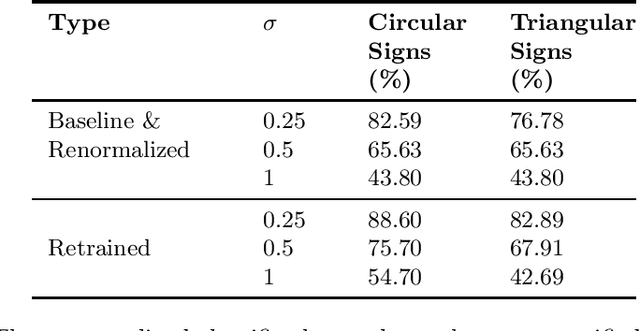
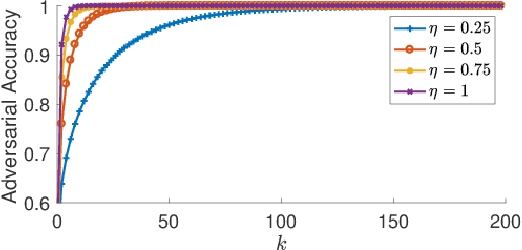

Recent advances in Machine Learning (ML) have demonstrated that neural networks can exceed human performance in many tasks. While generalizing well over natural inputs, neural networks are vulnerable to adversarial inputs -an input that is ``similar'' to the original input, but misclassified by the model. Existing defenses focus on Lp-norm bounded adversaries that perturb ML inputs in the digital space. In the real world, however, attackers can generate adversarial perturbations that have a large Lp-norm in the digital space. Additionally, these defenses also come at a cost to accuracy, making their applicability questionable in the real world. To defend models against such a powerful adversary, we leverage one constraint on its power: the perturbation should not change the human's perception of the physical information; the physical world places some constraints on the space of possible attacks. Two questions follow: how to extract and model these constraints? and how to design a classification paradigm that leverages these constraints to improve robustness accuracy trade-off? We observe that an ML model is typically a part of a larger system with access to different input modalities. Utilizing these modalities, we introduce invariants that limit the attacker's action space. We design a hierarchical classification paradigm that enforces these invariants at inference time. As a case study, we implement and evaluate our proposal in the context of the real-world application of road sign classification because of its applicability to autonomous driving. With access to different input modalities, such as LiDAR, camera, and location we show how to extract invariants and develop a hierarchical classifier. Our results on the KITTI and GTSRB datasets show that we can improve the robustness against physical attacks at minimal harm to accuracy.