 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Counterfactual Faces
Jul 18, 2024



Computer vision systems have been deployed in various applications involving biometrics like human faces. These systems can identify social media users, search for missing persons, and verify identity of individuals. While computer vision models are often evaluated for accuracy on available benchmarks, more annotated data is necessary to learn about their robustness and fairness against semantic distributional shifts in input data, especially in face data. Among annotated data, counterfactual examples grant strong explainability characteristics. Because collecting natural face data is prohibitively expensive, we put forth a generative AI-based framework to construct targeted, counterfactual, high-quality synthetic face data. Our synthetic data pipeline has many use cases, including face recognition systems sensitivity evaluations and image understanding system probes. The pipeline is validated with multiple user studies. We showcase the efficacy of our face generation pipeline on a leading commercial vision model. We identify facial attributes that cause vision systems to fail.
Unbiased Face Synthesis With Diffusion Models: Are We There Yet?
Sep 13, 2023



Text-to-image diffusion models have achieved widespread popularity due to their unprecedented image generation capability. In particular, their ability to synthesize and modify human faces has spurred research into using generated face images in both training data augmentation and model performance assessments. In this paper, we study the efficacy and shortcomings of generative models in the context of face generation. Utilizing a combination of qualitative and quantitative measures, including embedding-based metrics and user studies, we present a framework to audit the characteristics of generated faces conditioned on a set of social attributes. We applied our framework on faces generated through state-of-the-art text-to-image diffusion models. We identify several limitations of face image generation that include faithfulness to the text prompt, demographic disparities, and distributional shifts. Furthermore, we present an analytical model that provides insights into how training data selection contributes to the performance of generative models.
An Exploration of Multicalibration Uniform Convergence Bounds
Feb 09, 2022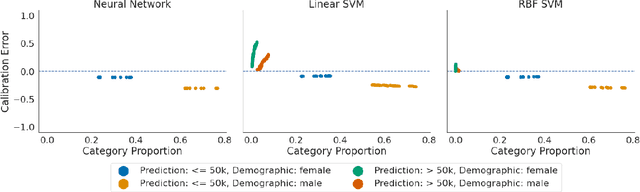
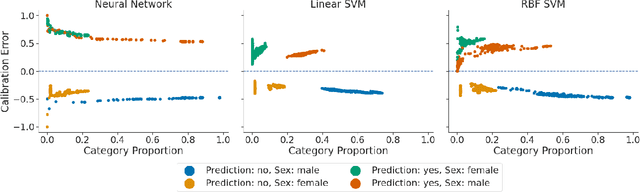
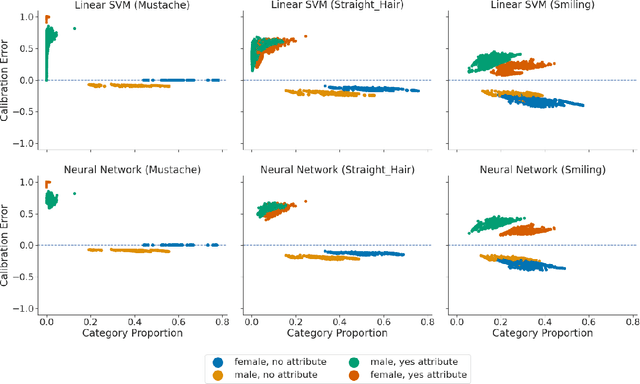
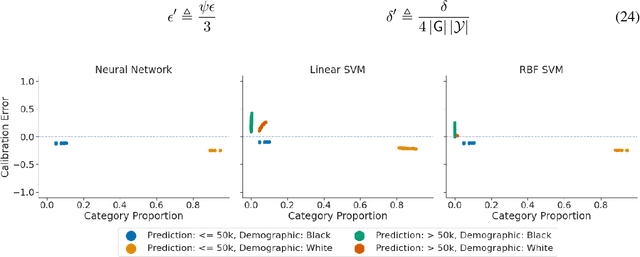
Recent works have investigated the sample complexity necessary for fair machine learning. The most advanced of such sample complexity bounds are developed by analyzing multicalibration uniform convergence for a given predictor class. We present a framework which yields multicalibration error uniform convergence bounds by reparametrizing sample complexities for Empirical Risk Minimization (ERM) learning. From this framework, we demonstrate that multicalibration error exhibits dependence on the classifier architecture as well as the underlying data distribution. We perform an experimental evaluation to investigate the behavior of multicalibration error for different families of classifiers. We compare the results of this evaluation to multicalibration error concentration bounds. Our investigation provides additional perspective on both algorithmic fairness and multicalibration error convergence bounds. Given the prevalence of ERM sample complexity bounds, our proposed framework enables machine learning practitioners to easily understand the convergence behavior of multicalibration error for a myriad of classifier architectures.
Fairness Properties of Face Recognition and Obfuscation Systems
Aug 05, 2021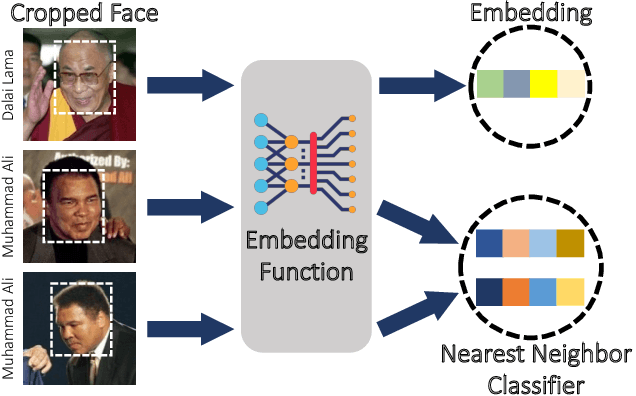
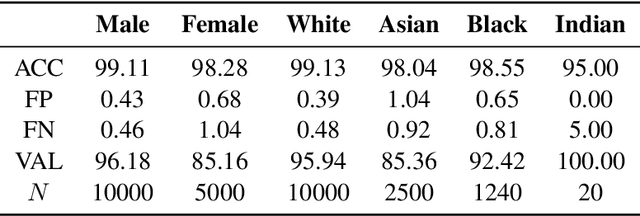
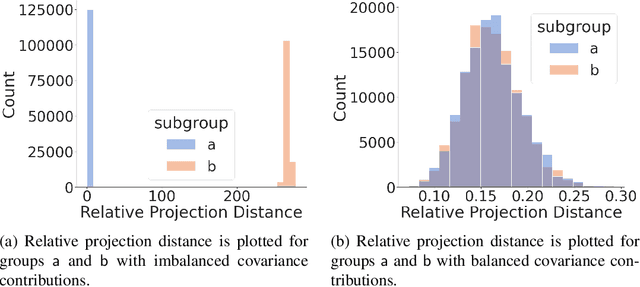
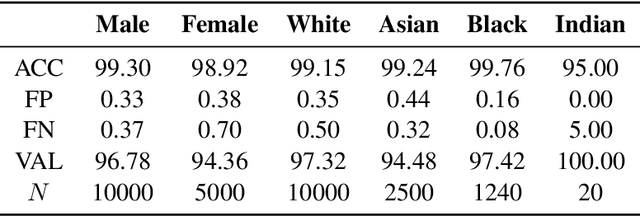
The proliferation of automated facial recognition in various commercial and government sectors has caused significant privacy concerns for individuals. A recent and popular approach to address these privacy concerns is to employ evasion attacks against the metric embedding networks powering facial recognition systems. Face obfuscation systems generate imperceptible perturbations, when added to an image, cause the facial recognition system to misidentify the user. The key to these approaches is the generation of perturbations using a pre-trained metric embedding network followed by their application to an online system, whose model might be proprietary. This dependence of face obfuscation on metric embedding networks, which are known to be unfair in the context of facial recognition, surfaces the question of demographic fairness -- \textit{are there demographic disparities in the performance of face obfuscation systems?} To address this question, we perform an analytical and empirical exploration of the performance of recent face obfuscation systems that rely on deep embedding networks. We find that metric embedding networks are demographically aware; they cluster faces in the embedding space based on their demographic attributes. We observe that this effect carries through to the face obfuscation systems: faces belonging to minority groups incur reduced utility compared to those from majority groups. For example, the disparity in average obfuscation success rate on the online Face++ API can reach up to 20 percentage points. Further, for some demographic groups, the average perturbation size increases by up to 17\% when choosing a target identity belonging to a different demographic group versus the same demographic group. Finally, we present a simple analytical model to provide insights into these phenomena.
Analyzing Accuracy Loss in Randomized Smoothing Defenses
Mar 03, 2020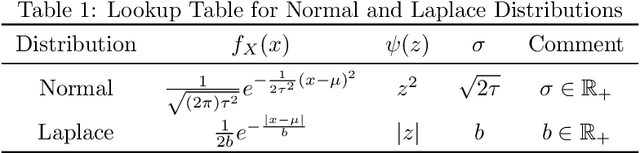
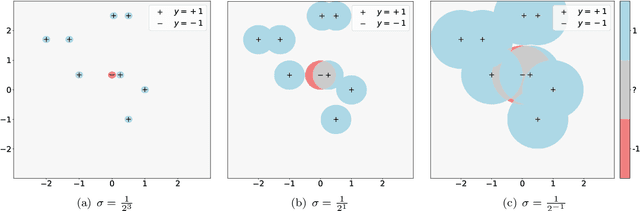
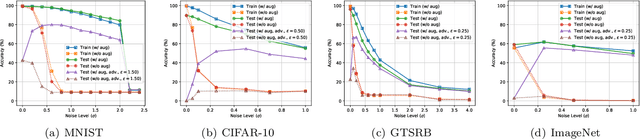
Recent advances in machine learning (ML) algorithms, especially deep neural networks (DNNs), have demonstrated remarkable success (sometimes exceeding human-level performance) on several tasks, including face and speech recognition. However, ML algorithms are vulnerable to \emph{adversarial attacks}, such test-time, training-time, and backdoor attacks. In test-time attacks an adversary crafts adversarial examples, which are specially crafted perturbations imperceptible to humans which, when added to an input example, force a machine learning model to misclassify the given input example. Adversarial examples are a concern when deploying ML algorithms in critical contexts, such as information security and autonomous driving. Researchers have responded with a plethora of defenses. One promising defense is \emph{randomized smoothing} in which a classifier's prediction is smoothed by adding random noise to the input example we wish to classify. In this paper, we theoretically and empirically explore randomized smoothing. We investigate the effect of randomized smoothing on the feasible hypotheses space, and show that for some noise levels the set of hypotheses which are feasible shrinks due to smoothing, giving one reason why the natural accuracy drops after smoothing. To perform our analysis, we introduce a model for randomized smoothing which abstracts away specifics, such as the exact distribution of the noise. We complement our theoretical results with extensive experiments.
A Geometric Perspective on the Transferability of Adversarial Directions
Nov 08, 2018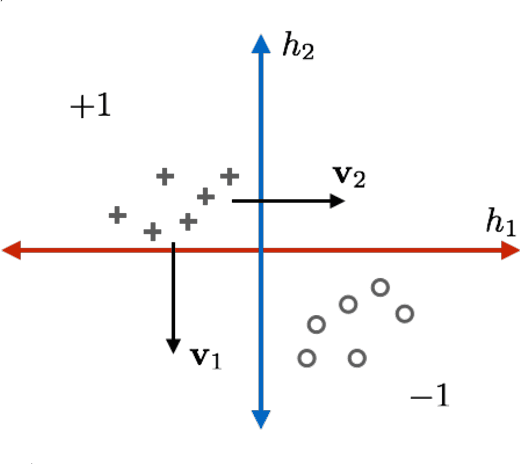
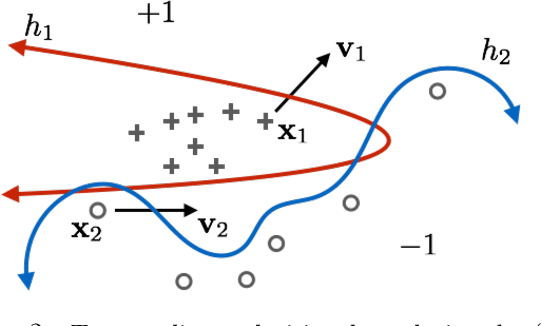
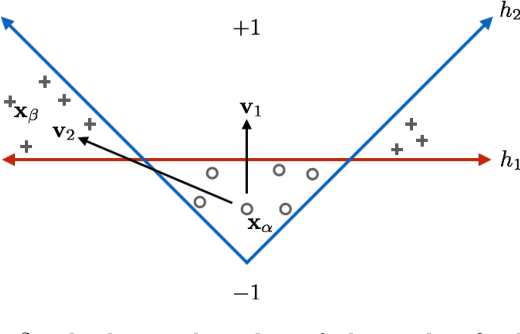
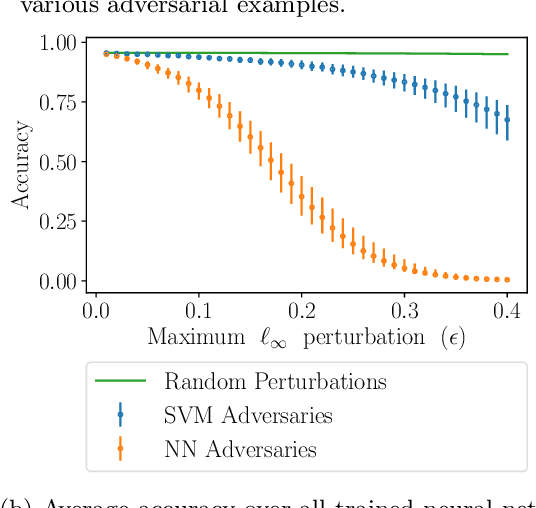
State-of-the-art machine learning models frequently misclassify inputs that have been perturbed in an adversarial manner. Adversarial perturbations generated for a given input and a specific classifier often seem to be effective on other inputs and even different classifiers. In other words, adversarial perturbations seem to transfer between different inputs, models, and even different neural network architectures. In this work, we show that in the context of linear classifiers and two-layer ReLU networks, there provably exist directions that give rise to adversarial perturbations for many classifiers and data points simultaneously. We show that these "transferable adversarial directions" are guaranteed to exist for linear separators of a given set, and will exist with high probability for linear classifiers trained on independent sets drawn from the same distribution. We extend our results to large classes of two-layer ReLU networks. We further show that adversarial directions for ReLU networks transfer to linear classifiers while the reverse need not hold, suggesting that adversarial perturbations for more complex models are more likely to transfer to other classifiers. We validate our findings empirically, even for deeper ReLU networks.