 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Token Initialization for New Vocabulary in LMs for Generative Recommendation
Apr 02, 2026Language models (LMs) are increasingly extended with new learnable vocabulary tokens for domain-specific tasks, such as Semantic-ID tokens in generative recommendation. The standard practice initializes these new tokens as the mean of existing vocabulary embeddings, then relies on supervised fine-tuning to learn their representations. We present a systematic analysis of this strategy: through spectral and geometric diagnostics, we show that mean initialization collapses all new tokens into a degenerate subspace, erasing inter-token distinctions that subsequent fine-tuning struggles to fully recover. These findings suggest that \emph{token initialization} is a key bottleneck when extending LMs with new vocabularies. Motivated by this diagnosis, we propose the \emph{Grounded Token Initialization Hypothesis}: linguistically grounding novel tokens in the pretrained embedding space before fine-tuning better enables the model to leverage its general-purpose knowledge for novel-token domains. We operationalize this hypothesis as GTI (Grounded Token Initialization), a lightweight grounding stage that, prior to fine-tuning, maps new tokens to distinct, semantically meaningful locations in the pretrained embedding space using only paired linguistic supervision. Despite its simplicity, GTI outperforms both mean initialization and existing auxiliary-task adaptation methods in the majority of evaluation settings across multiple generative recommendation benchmarks, including industry-scale and public datasets. Further analyses show that grounded embeddings produce richer inter-token structure that persists through fine-tuning, corroborating the hypothesis that initialization quality is a key bottleneck in vocabulary extension.
Is Conformal Factuality for RAG-based LLMs Robust? Novel Metrics and Systematic Insights
Mar 17, 2026Large language models (LLMs) frequently hallucinate, limiting their reliability in knowledge-intensive applications. Retrieval-augmented generation (RAG) and conformal factuality have emerged as potential ways to address this limitation. While RAG aims to ground responses in retrieved evidence, it provides no statistical guarantee that the final output is correct. Conformal factuality filtering offers distribution-free statistical reliability by scoring and filtering atomic claims using a threshold calibrated on held-out data, however, the informativeness of the final output is not guaranteed. We systematically analyze the reliability and usefulness of conformal factuality for RAG-based LLMs across generation, scoring, calibration, robustness, and efficiency. We propose novel informativeness-aware metrics that better reflect task utility under conformal filtering. Across three benchmarks and multiple model families, we find that (i) conformal filtering suffers from low usefulness at high factuality levels due to vacuous outputs, (ii) conformal factuality guarantee is not robust to distribution shifts and distractors, highlighting the limitation that requires calibration data to closely match deployment conditions, and (iii) lightweight entailment-based verifiers match or outperform LLM-based model confidence scorers while requiring over $100\times$ fewer FLOPs. Overall, our results expose factuality-informativeness trade-offs and fragility of conformal filtering framework under distribution shifts and distractors, highlighting the need for new approaches for reliability with robustness and usefulness as key metrics, and provide actionable guidance for building RAG pipelines that are both reliable and computationally efficient.
Almost Asymptotically Optimal Active Clustering Through Pairwise Observations
Feb 05, 2026We propose a new analysis framework for clustering $M$ items into an unknown number of $K$ distinct groups using noisy and actively collected responses. At each time step, an agent is allowed to query pairs of items and observe bandit binary feedback. If the pair of items belongs to the same (resp.\ different) cluster, the observed feedback is $1$ with probability $p>1/2$ (resp.\ $q<1/2$). Leveraging the ubiquitous change-of-measure technique, we establish a fundamental lower bound on the expected number of queries needed to achieve a desired confidence in the clustering accuracy, formulated as a sup-inf optimization problem. Building on this theoretical foundation, we design an asymptotically optimal algorithm in which the stopping criterion involves an empirical version of the inner infimum -- the Generalized Likelihood Ratio (GLR) statistic -- being compared to a threshold. We develop a computationally feasible variant of the GLR statistic and show that its performance gap to the lower bound can be accurately empirically estimated and remains within a constant multiple of the lower bound.
Agentic Very Long Video Understanding
Jan 26, 2026The advent of always-on personal AI assistants, enabled by all-day wearable devices such as smart glasses, demands a new level of contextual understanding, one that goes beyond short, isolated events to encompass the continuous, longitudinal stream of egocentric video. Achieving this vision requires advances in long-horizon video understanding, where systems must interpret and recall visual and audio information spanning days or even weeks. Existing methods, including large language models and retrieval-augmented generation, are constrained by limited context windows and lack the ability to perform compositional, multi-hop reasoning over very long video streams. In this work, we address these challenges through EGAgent, an enhanced agentic framework centered on entity scene graphs, which represent people, places, objects, and their relationships over time. Our system equips a planning agent with tools for structured search and reasoning over these graphs, as well as hybrid visual and audio search capabilities, enabling detailed, cross-modal, and temporally coherent reasoning. Experiments on the EgoLifeQA and Video-MME (Long) datasets show that our method achieves state-of-the-art performance on EgoLifeQA (57.5%) and competitive performance on Video-MME (Long) (74.1%) for complex longitudinal video understanding tasks.
CuRe: Cultural Gaps in the Long Tail of Text-to-Image Systems
Jun 09, 2025Popular text-to-image (T2I) systems are trained on web-scraped data, which is heavily Amero and Euro-centric, underrepresenting the cultures of the Global South. To analyze these biases, we introduce CuRe, a novel and scalable benchmarking and scoring suite for cultural representativeness that leverages the marginal utility of attribute specification to T2I systems as a proxy for human judgments. Our CuRe benchmark dataset has a novel categorical hierarchy built from the crowdsourced Wikimedia knowledge graph, with 300 cultural artifacts across 32 cultural subcategories grouped into six broad cultural axes (food, art, fashion, architecture, celebrations, and people). Our dataset's categorical hierarchy enables CuRe scorers to evaluate T2I systems by analyzing their response to increasing the informativeness of text conditioning, enabling fine-grained cultural comparisons. We empirically observe much stronger correlations of our class of scorers to human judgments of perceptual similarity, image-text alignment, and cultural diversity across image encoders (SigLIP 2, AIMV2 and DINOv2), vision-language models (OpenCLIP, SigLIP 2, Gemini 2.0 Flash) and state-of-the-art text-to-image systems, including three variants of Stable Diffusion (1.5, XL, 3.5 Large), FLUX.1 [dev], Ideogram 2.0, and DALL-E 3. The code and dataset is open-sourced and available at https://aniketrege.github.io/cure/.
Adaptive Scoring and Thresholding with Human Feedback for Robust Out-of-Distribution Detection
May 05, 2025Machine Learning (ML) models are trained on in-distribution (ID) data but often encounter out-of-distribution (OOD) inputs during deployment -- posing serious risks in safety-critical domains. Recent works have focused on designing scoring functions to quantify OOD uncertainty, with score thresholds typically set based solely on ID data to achieve a target true positive rate (TPR), since OOD data is limited before deployment. However, these TPR-based thresholds leave false positive rates (FPR) uncontrolled, often resulting in high FPRs where OOD points are misclassified as ID. Moreover, fixed scoring functions and thresholds lack the adaptivity needed to handle newly observed, evolving OOD inputs, leading to sub-optimal performance. To address these challenges, we propose a human-in-the-loop framework that \emph{safely updates both scoring functions and thresholds on the fly} based on real-world OOD inputs. Our method maximizes TPR while strictly controlling FPR at all times, even as the system adapts over time. We provide theoretical guarantees for FPR control under stationary conditions and present extensive empirical evaluations on OpenOOD benchmarks to demonstrate that our approach outperforms existing methods by achieving higher TPRs while maintaining FPR control.
PAL: Pluralistic Alignment Framework for Learning from Heterogeneous Preferences
Jun 12, 2024



Large foundation models pretrained on raw web-scale data are not readily deployable without additional step of extensive alignment to human preferences. Such alignment is typically done by collecting large amounts of pairwise comparisons from humans ("Do you prefer output A or B?") and learning a reward model or a policy with the Bradley-Terry-Luce (BTL) model as a proxy for a human's underlying implicit preferences. These methods generally suffer from assuming a universal preference shared by all humans, which lacks the flexibility of adapting to plurality of opinions and preferences. In this work, we propose PAL, a framework to model human preference complementary to existing pretraining strategies, which incorporates plurality from the ground up. We propose using the ideal point model as a lens to view alignment using preference comparisons. Together with our novel reformulation and using mixture modeling, our framework captures the plurality of population preferences while simultaneously learning a common preference latent space across different preferences, which can few-shot generalize to new, unseen users. Our approach enables us to use the penultimate-layer representation of large foundation models and simple MLP layers to learn reward functions that are on-par with the existing large state-of-the-art reward models, thereby enhancing efficiency of reward modeling significantly. We show that PAL achieves competitive reward model accuracy compared to strong baselines on 1) Language models with Summary dataset ; 2) Image Generative models with Pick-a-Pic dataset ; 3) A new semisynthetic heterogeneous dataset generated using Anthropic Personas. Finally, our experiments also highlight the shortcoming of current preference datasets that are created using rigid rubrics which wash away heterogeneity, and call for more nuanced data collection approaches.
Taming False Positives in Out-of-Distribution Detection with Human Feedback
Apr 25, 2024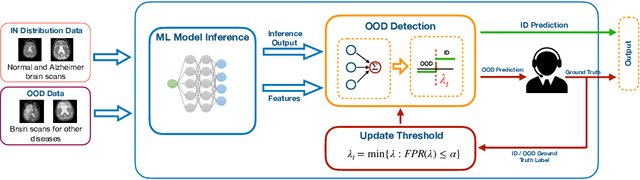

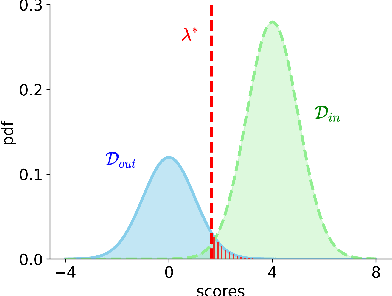

Robustness to out-of-distribution (OOD) samples is crucial for safely deploying machine learning models in the open world. Recent works have focused on designing scoring functions to quantify OOD uncertainty. Setting appropriate thresholds for these scoring functions for OOD detection is challenging as OOD samples are often unavailable up front. Typically, thresholds are set to achieve a desired true positive rate (TPR), e.g., $95\%$ TPR. However, this can lead to very high false positive rates (FPR), ranging from 60 to 96\%, as observed in the Open-OOD benchmark. In safety-critical real-life applications, e.g., medical diagnosis, controlling the FPR is essential when dealing with various OOD samples dynamically. To address these challenges, we propose a mathematically grounded OOD detection framework that leverages expert feedback to \emph{safely} update the threshold on the fly. We provide theoretical results showing that it is guaranteed to meet the FPR constraint at all times while minimizing the use of human feedback. Another key feature of our framework is that it can work with any scoring function for OOD uncertainty quantification. Empirical evaluation of our system on synthetic and benchmark OOD datasets shows that our method can maintain FPR at most $5\%$ while maximizing TPR.
* Appeared in the 27th International Conference on Artificial Intelligence and Statistics (AISTATS 2024)
Pearls from Pebbles: Improved Confidence Functions for Auto-labeling
Apr 24, 2024



Auto-labeling is an important family of techniques that produce labeled training sets with minimum manual labeling. A prominent variant, threshold-based auto-labeling (TBAL), works by finding a threshold on a model's confidence scores above which it can accurately label unlabeled data points. However, many models are known to produce overconfident scores, leading to poor TBAL performance. While a natural idea is to apply off-the-shelf calibration methods to alleviate the overconfidence issue, such methods still fall short. Rather than experimenting with ad-hoc choices of confidence functions, we propose a framework for studying the \emph{optimal} TBAL confidence function. We develop a tractable version of the framework to obtain \texttt{Colander} (Confidence functions for Efficient and Reliable Auto-labeling), a new post-hoc method specifically designed to maximize performance in TBAL systems. We perform an extensive empirical evaluation of our method \texttt{Colander} and compare it against methods designed for calibration. \texttt{Colander} achieves up to 60\% improvements on coverage over the baselines while maintaining auto-labeling error below $5\%$ and using the same amount of labeled data as the baselines.
Metric Learning from Limited Pairwise Preference Comparisons
Mar 28, 2024We study metric learning from preference comparisons under the ideal point model, in which a user prefers an item over another if it is closer to their latent ideal item. These items are embedded into $\mathbb{R}^d$ equipped with an unknown Mahalanobis distance shared across users. While recent work shows that it is possible to simultaneously recover the metric and ideal items given $\mathcal{O}(d)$ pairwise comparisons per user, in practice we often have a limited budget of $o(d)$ comparisons. We study whether the metric can still be recovered, even though it is known that learning individual ideal items is now no longer possible. We show that in general, $o(d)$ comparisons reveals no information about the metric, even with infinitely many users. However, when comparisons are made over items that exhibit low-dimensional structure, each user can contribute to learning the metric restricted to a low-dimensional subspace so that the metric can be jointly identified. We present a divide-and-conquer approach that achieves this, and provide theoretical recovery guarantees and empirical validation.