 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Large Language Models for Lunar Mission Planning and In Situ Resource Utilization
Apr 28, 2025



A key factor for lunar mission planning is the ability to assess the local availability of raw materials. However, many potentially relevant measurements are scattered across a variety of scientific publications. In this paper we consider the viability of obtaining lunar composition data by leveraging LLMs to rapidly process a corpus of scientific publications. While leveraging LLMs to obtain knowledge from scientific documents is not new, this particular application presents interesting challenges due to the heterogeneity of lunar samples and the nuances involved in their characterization. Accuracy and uncertainty quantification are particularly crucial since many materials properties can be sensitive to small variations in composition. Our findings indicate that off-the-shelf LLMs are generally effective at extracting data from tables commonly found in these documents. However, there remains opportunity to further refine the data we extract in this initial approach; in particular, to capture fine-grained mineralogy information and to improve performance on more subtle/complex pieces of information.
A Decision-driven Methodology for Designing Uncertainty-aware AI Self-Assessment
Aug 02, 2024Artificial intelligence (AI) has revolutionized decision-making processes and systems throughout society and, in particular, has emerged as a significant technology in high-impact scenarios of national interest. Yet, despite AI's impressive predictive capabilities in controlled settings, it still suffers from a range of practical setbacks preventing its widespread use in various critical scenarios. In particular, it is generally unclear if a given AI system's predictions can be trusted by decision-makers in downstream applications. To address the need for more transparent, robust, and trustworthy AI systems, a suite of tools has been developed to quantify the uncertainty of AI predictions and, more generally, enable AI to "self-assess" the reliability of its predictions. In this manuscript, we categorize methods for AI self-assessment along several key dimensions and provide guidelines for selecting and designing the appropriate method for a practitioner's needs. In particular, we focus on uncertainty estimation techniques that consider the impact of self-assessment on the choices made by downstream decision-makers and on the resulting costs and benefits of decision outcomes. To demonstrate the utility of our methodology for self-assessment design, we illustrate its use for two realistic national-interest scenarios. This manuscript is a practical guide for machine learning engineers and AI system users to select the ideal self-assessment techniques for each problem.
LabelBench: A Comprehensive Framework for Benchmarking Label-Efficient Learning
Jun 16, 2023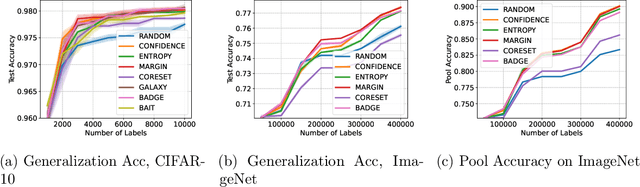


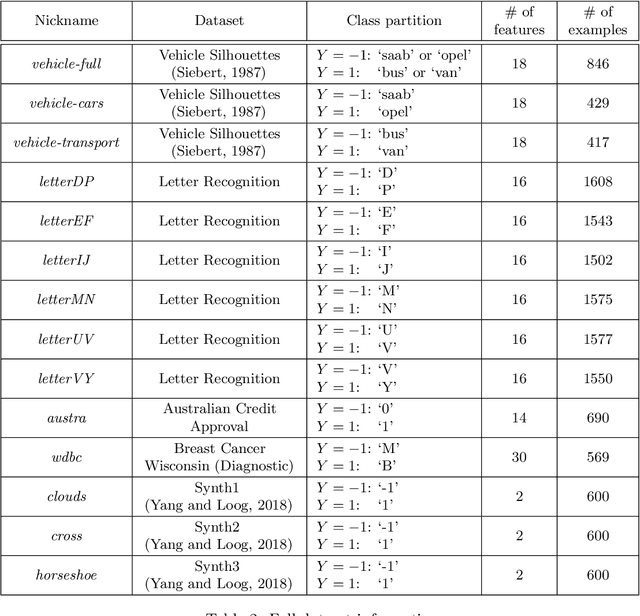
Labeled data are critical to modern machine learning applications, but obtaining labels can be expensive. To mitigate this cost, machine learning methods, such as transfer learning, semi-supervised learning and active learning, aim to be label-efficient: achieving high predictive performance from relatively few labeled examples. While obtaining the best label-efficiency in practice often requires combinations of these techniques, existing benchmark and evaluation frameworks do not capture a concerted combination of all such techniques. This paper addresses this deficiency by introducing LabelBench, a new computationally-efficient framework for joint evaluation of multiple label-efficient learning techniques. As an application of LabelBench, we introduce a novel benchmark of state-of-the-art active learning methods in combination with semi-supervised learning for fine-tuning pretrained vision transformers. Our benchmark demonstrates better label-efficiencies than previously reported in active learning. LabelBench's modular codebase is open-sourced for the broader community to contribute label-efficient learning methods and benchmarks. The repository can be found at: https://github.com/EfficientTraining/LabelBench.
Feed Two Birds with One Scone: Exploiting Wild Data for Both Out-of-Distribution Generalization and Detection
Jun 15, 2023Modern machine learning models deployed in the wild can encounter both covariate and semantic shifts, giving rise to the problems of out-of-distribution (OOD) generalization and OOD detection respectively. While both problems have received significant research attention lately, they have been pursued independently. This may not be surprising, since the two tasks have seemingly conflicting goals. This paper provides a new unified approach that is capable of simultaneously generalizing to covariate shifts while robustly detecting semantic shifts. We propose a margin-based learning framework that exploits freely available unlabeled data in the wild that captures the environmental test-time OOD distributions under both covariate and semantic shifts. We show both empirically and theoretically that the proposed margin constraint is the key to achieving both OOD generalization and detection. Extensive experiments show the superiority of our framework, outperforming competitive baselines that specialize in either OOD generalization or OOD detection. Code is publicly available at https://github.com/deeplearning-wisc/scone.
One for All: Simultaneous Metric and Preference Learning over Multiple Users
Jul 07, 2022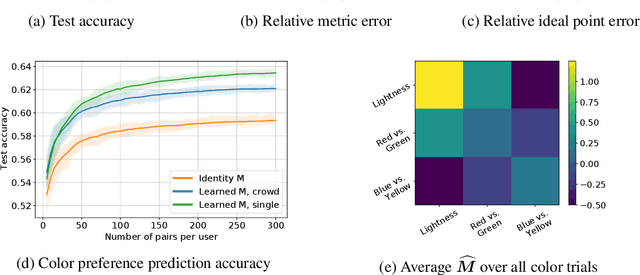
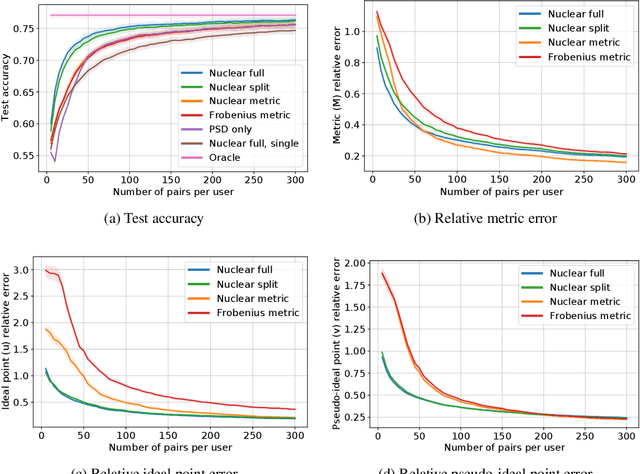
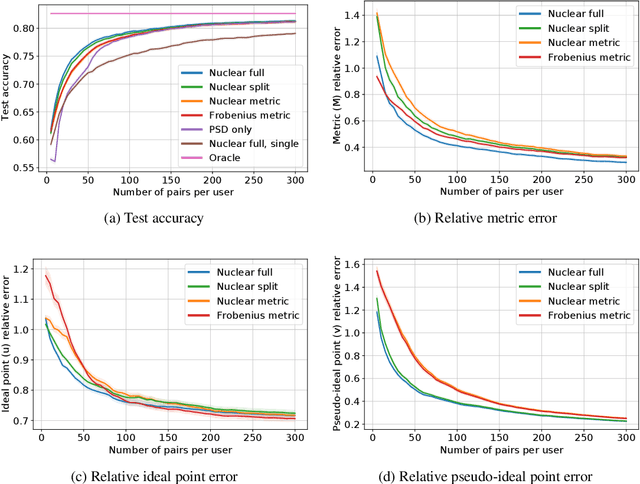
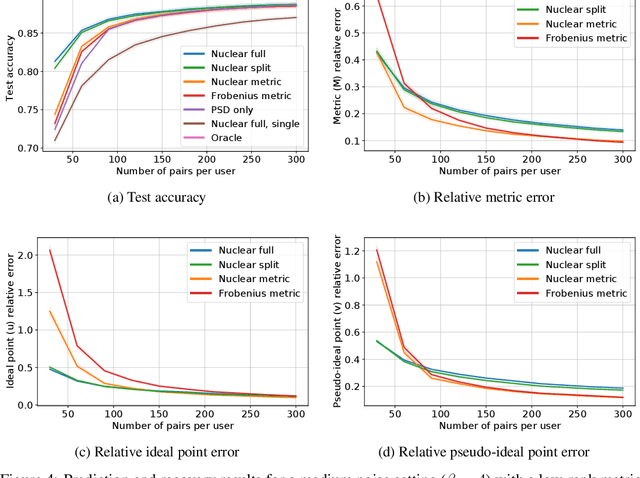
This paper investigates simultaneous preference and metric learning from a crowd of respondents. A set of items represented by $d$-dimensional feature vectors and paired comparisons of the form ``item $i$ is preferable to item $j$'' made by each user is given. Our model jointly learns a distance metric that characterizes the crowd's general measure of item similarities along with a latent ideal point for each user reflecting their individual preferences. This model has the flexibility to capture individual preferences, while enjoying a metric learning sample cost that is amortized over the crowd. We first study this problem in a noiseless, continuous response setting (i.e., responses equal to differences of item distances) to understand the fundamental limits of learning. Next, we establish prediction error guarantees for noisy, binary measurements such as may be collected from human respondents, and show how the sample complexity improves when the underlying metric is low-rank. Finally, we establish recovery guarantees under assumptions on the response distribution. We demonstrate the performance of our model on both simulated data and on a dataset of color preference judgements across a large number of users.
A Low-complexity Brain-computer Interface for High-complexity Robot Swarm Control
May 27, 2022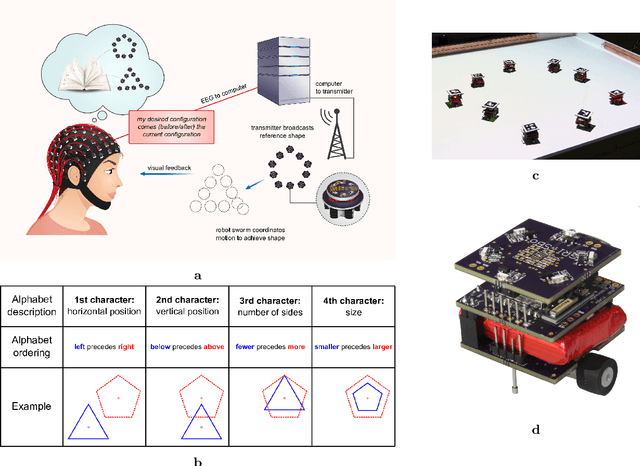
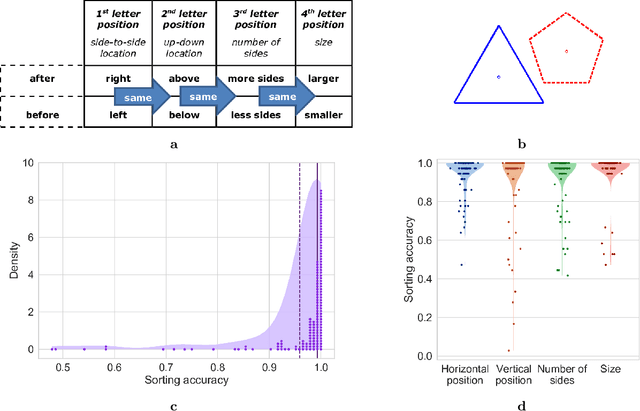
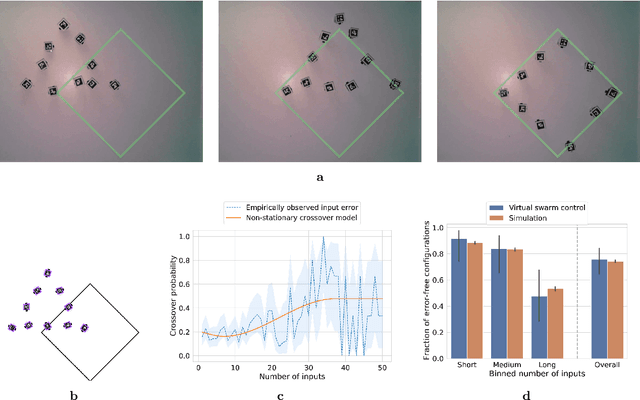
A brain-computer interface (BCI) is a system that allows a human operator to use only mental commands in controlling end effectors that interact with the world around them. Such a system consists of a measurement device to record the human user's brain activity, which is then processed into commands that drive a system end effector. BCIs involve either invasive measurements which allow for high-complexity control but are generally infeasible, or noninvasive measurements which offer lower quality signals but are more practical to use. In general, BCI systems have not been developed that efficiently, robustly, and scalably perform high-complexity control while retaining the practicality of noninvasive measurements. Here we leverage recent results from feedback information theory to fill this gap by modeling BCIs as a communications system and deploying a human-implementable interaction algorithm for noninvasive control of a high-complexity robot swarm. We construct a scalable dictionary of robotic behaviors that can be searched simply and efficiently by a BCI user, as we demonstrate through a large-scale user study testing the feasibility of our interaction algorithm, a user test of the full BCI system on (virtual and real) robot swarms, and simulations that verify our results against theoretical models. Our results provide a proof of concept for how a large class of high-complexity effectors (even beyond robotics) can be effectively controlled by a BCI system with low-complexity and noisy inputs.
Feedback Coding for Active Learning
Feb 28, 2021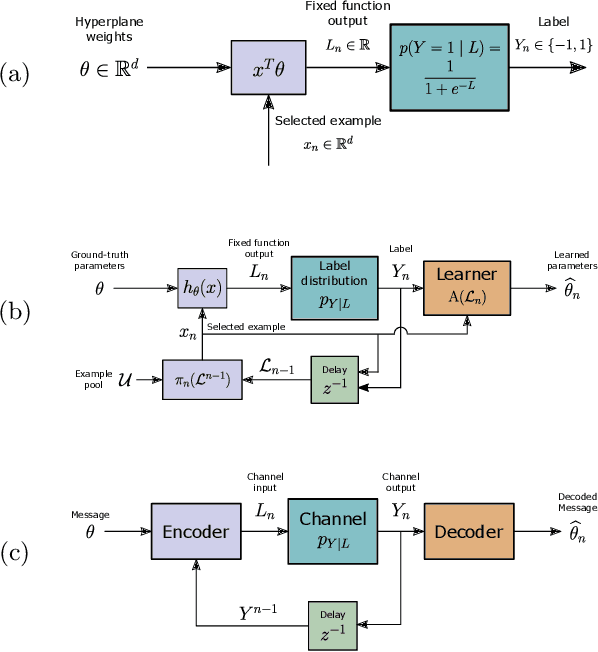
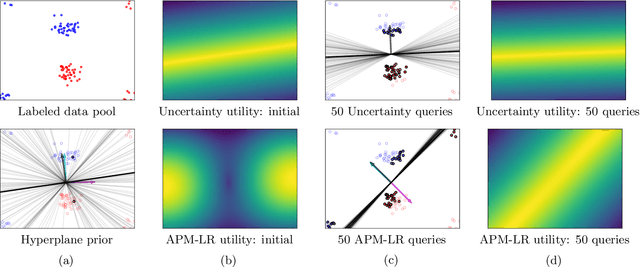
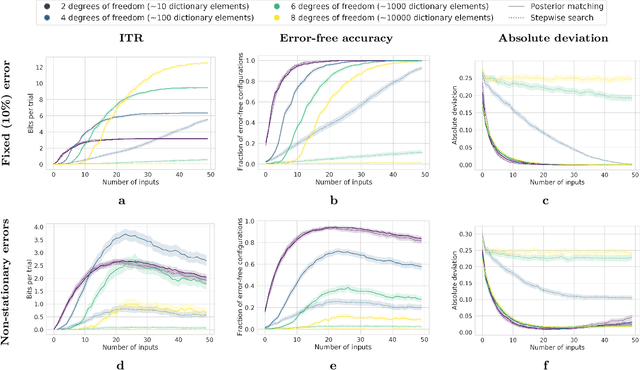
The iterative selection of examples for labeling in active machine learning is conceptually similar to feedback channel coding in information theory: in both tasks, the objective is to seek a minimal sequence of actions to encode information in the presence of noise. While this high-level overlap has been previously noted, there remain open questions on how to best formulate active learning as a communications system to leverage existing analysis and algorithms in feedback coding. In this work, we formally identify and leverage the structural commonalities between the two problems, including the characterization of encoder and noisy channel components, to design a new algorithm. Specifically, we develop an optimal transport-based feedback coding scheme called Approximate Posterior Matching (APM) for the task of active example selection and explore its application to Bayesian logistic regression, a popular model in active learning. We evaluate APM on a variety of datasets and demonstrate learning performance comparable to existing active learning methods, at a reduced computational cost. These results demonstrate the potential of directly deploying concepts from feedback channel coding to design efficient active learning strategies.
Generative causal explanations of black-box classifiers
Jun 24, 2020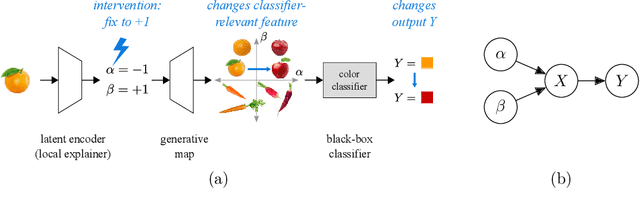

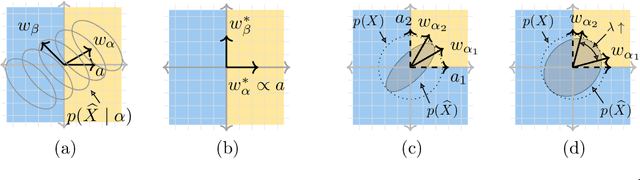

We develop a method for generating causal post-hoc explanations of black-box classifiers based on a learned low-dimensional representation of the data. The explanation is causal in the sense that changing learned latent factors produces a change in the classifier output statistics. To construct these explanations, we design a learning framework that leverages a generative model and information-theoretic measures of causal influence. Our objective function encourages both the generative model to faithfully represent the data distribution and the latent factors to have a large causal influence on the classifier output. Our method learns both global and local explanations, is compatible with any classifier that admits class probabilities and a gradient, and does not require labeled attributes or knowledge of causal structure. Using carefully controlled test cases, we provide intuition that illuminates the function of our causal objective. We then demonstrate the practical utility of our method on image recognition tasks.
Active Ordinal Querying for Tuplewise Similarity Learning
Oct 16, 2019
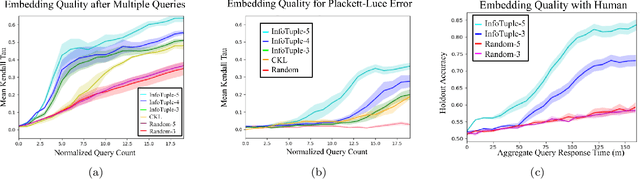
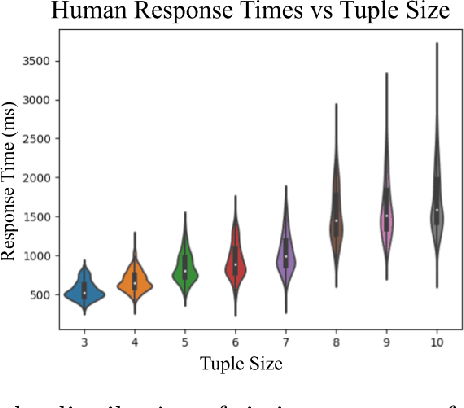
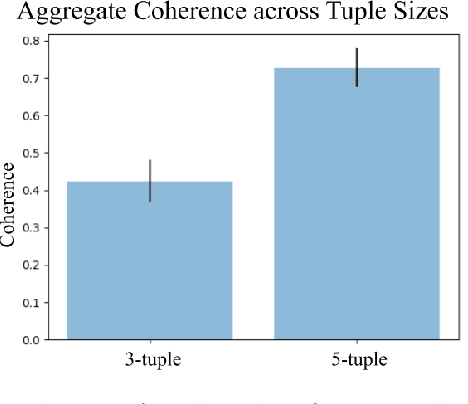
Many machine learning tasks such as clustering, classification, and dataset search benefit from embedding data points in a space where distances reflect notions of relative similarity as perceived by humans. A common way to construct such an embedding is to request triplet similarity queries to an oracle, comparing two objects with respect to a reference. This work generalizes triplet queries to tuple queries of arbitrary size that ask an oracle to rank multiple objects against a reference, and introduces an efficient and robust adaptive selection method called InfoTuple that uses a novel approach to mutual information maximization. We show that the performance of InfoTuple at various tuple sizes exceeds that of the state-of-the-art adaptive triplet selection method on synthetic tests and new human response datasets, and empirically demonstrate the significant gains in efficiency and query consistency achieved by querying larger tuples instead of triplets.