 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImbalanced Gradients in RL Post-Training of Multi-Task LLMs
Oct 22, 2025Multi-task post-training of large language models (LLMs) is typically performed by mixing datasets from different tasks and optimizing them jointly. This approach implicitly assumes that all tasks contribute gradients of similar magnitudes; when this assumption fails, optimization becomes biased toward large-gradient tasks. In this paper, however, we show that this assumption fails in RL post-training: certain tasks produce significantly larger gradients, thus biasing updates toward those tasks. Such gradient imbalance would be justified only if larger gradients implied larger learning gains on the tasks (i.e., larger performance improvements) -- but we find this is not true. Large-gradient tasks can achieve similar or even much lower learning gains than small-gradient ones. Further analyses reveal that these gradient imbalances cannot be explained by typical training statistics such as training rewards or advantages, suggesting that they arise from the inherent differences between tasks. This cautions against naive dataset mixing and calls for future work on principled gradient-level corrections for LLMs.
A Classification View on Meta Learning Bandits
Apr 06, 2025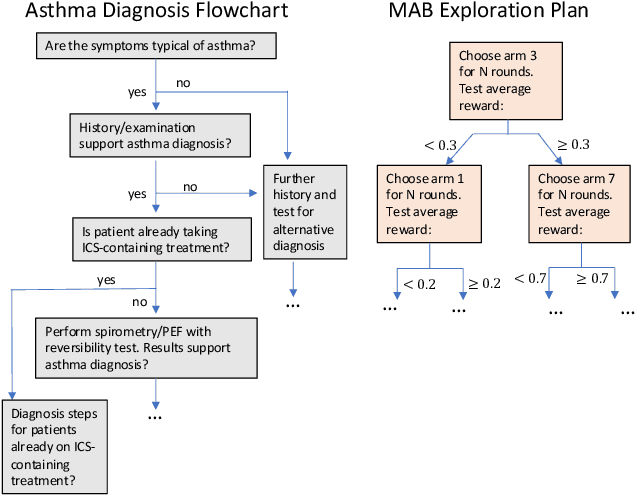
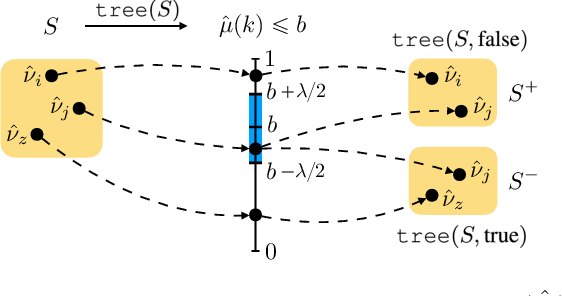
Contextual multi-armed bandits are a popular choice to model sequential decision-making. E.g., in a healthcare application we may perform various tests to asses a patient condition (exploration) and then decide on the best treatment to give (exploitation). When humans design strategies, they aim for the exploration to be fast, since the patient's health is at stake, and easy to interpret for a physician overseeing the process. However, common bandit algorithms are nothing like that: The regret caused by exploration scales with $\sqrt{H}$ over $H$ rounds and decision strategies are based on opaque statistical considerations. In this paper, we use an original classification view to meta learn interpretable and fast exploration plans for a fixed collection of bandits $\mathbb{M}$. The plan is prescribed by an interpretable decision tree probing decisions' payoff to classify the test bandit. The test regret of the plan in the stochastic and contextual setting scales with $O (\lambda^{-2} C_{\lambda} (\mathbb{M}) \log^2 (MH))$, being $M$ the size of $\mathbb{M}$, $\lambda$ a separation parameter over the bandits, and $C_\lambda (\mathbb{M})$ a novel classification-coefficient that fundamentally links meta learning bandits with classification. Through a nearly matching lower bound, we show that $C_\lambda (\mathbb{M})$ inherently captures the complexity of the setting.
Two-Timescale Linear Stochastic Approximation: Constant Stepsizes Go a Long Way
Oct 16, 2024
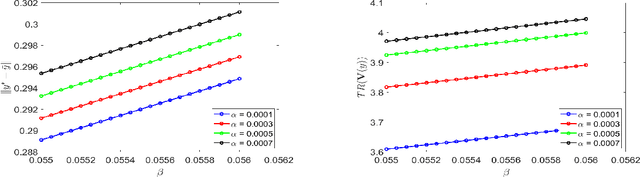
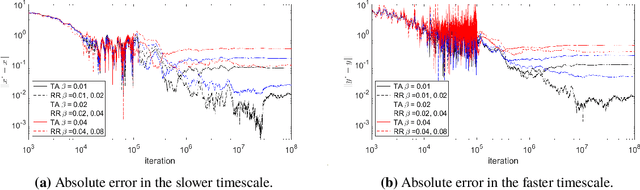
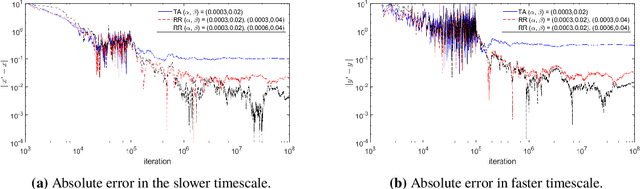
Previous studies on two-timescale stochastic approximation (SA) mainly focused on bounding mean-squared errors under diminishing stepsize schemes. In this work, we investigate {\it constant} stpesize schemes through the lens of Markov processes, proving that the iterates of both timescales converge to a unique joint stationary distribution in Wasserstein metric. We derive explicit geometric and non-asymptotic convergence rates, as well as the variance and bias introduced by constant stepsizes in the presence of Markovian noise. Specifically, with two constant stepsizes $\alpha < \beta$, we show that the biases scale linearly with both stepsizes as $\Theta(\alpha)+\Theta(\beta)$ up to higher-order terms, while the variance of the slower iterate (resp., faster iterate) scales only with its own stepsize as $O(\alpha)$ (resp., $O(\beta)$). Unlike previous work, our results require no additional assumptions such as $\beta^2 \ll \alpha$ nor extra dependence on dimensions. These fine-grained characterizations allow tail-averaging and extrapolation techniques to reduce variance and bias, improving mean-squared error bound to $O(\beta^4 + \frac{1}{t})$ for both iterates.
RL in Latent MDPs is Tractable: Online Guarantees via Off-Policy Evaluation
Jun 03, 2024
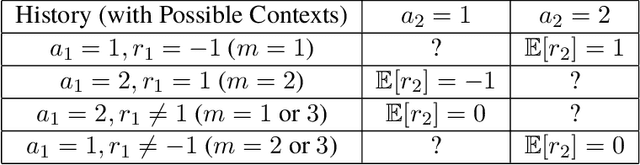
In many real-world decision problems there is partially observed, hidden or latent information that remains fixed throughout an interaction. Such decision problems can be modeled as Latent Markov Decision Processes (LMDPs), where a latent variable is selected at the beginning of an interaction and is not disclosed to the agent. In the last decade, there has been significant progress in solving LMDPs under different structural assumptions. However, for general LMDPs, there is no known learning algorithm that provably matches the existing lower bound~\cite{kwon2021rl}. We introduce the first sample-efficient algorithm for LMDPs without any additional structural assumptions. Our result builds off a new perspective on the role of off-policy evaluation guarantees and coverage coefficients in LMDPs, a perspective, that has been overlooked in the context of exploration in partially observed environments. Specifically, we establish a novel off-policy evaluation lemma and introduce a new coverage coefficient for LMDPs. Then, we show how these can be used to derive near-optimal guarantees of an optimistic exploration algorithm. These results, we believe, can be valuable for a wide range of interactive learning problems beyond LMDPs, and especially, for partially observed environments.
Future Prediction Can be a Strong Evidence of Good History Representation in Partially Observable Environments
Feb 11, 2024



Learning a good history representation is one of the core challenges of reinforcement learning (RL) in partially observable environments. Recent works have shown the advantages of various auxiliary tasks for facilitating representation learning. However, the effectiveness of such auxiliary tasks has not been fully convincing, especially in partially observable environments that require long-term memorization and inference. In this empirical study, we investigate the effectiveness of future prediction for learning the representations of histories, possibly of extensive length, in partially observable environments. We first introduce an approach that decouples the task of learning history representations from policy optimization via future prediction. Then, our main contributions are two-fold: (a) we demonstrate that the performance of reinforcement learning is strongly correlated with the prediction accuracy of future observations in partially observable environments, and (b) our approach can significantly improve the overall end-to-end approach by preventing high-variance noisy signals from reinforcement learning objectives to influence the representation learning. We illustrate our claims on three types of benchmarks that necessitate the ability to process long histories for high returns.
On the Complexity of First-Order Methods in Stochastic Bilevel Optimization
Feb 11, 2024We consider the problem of finding stationary points in Bilevel optimization when the lower-level problem is unconstrained and strongly convex. The problem has been extensively studied in recent years; the main technical challenge is to keep track of lower-level solutions $y^*(x)$ in response to the changes in the upper-level variables $x$. Subsequently, all existing approaches tie their analyses to a genie algorithm that knows lower-level solutions and, therefore, need not query any points far from them. We consider a dual question to such approaches: suppose we have an oracle, which we call $y^*$-aware, that returns an $O(\epsilon)$-estimate of the lower-level solution, in addition to first-order gradient estimators {\it locally unbiased} within the $\Theta(\epsilon)$-ball around $y^*(x)$. We study the complexity of finding stationary points with such an $y^*$-aware oracle: we propose a simple first-order method that converges to an $\epsilon$ stationary point using $O(\epsilon^{-6}), O(\epsilon^{-4})$ access to first-order $y^*$-aware oracles. Our upper bounds also apply to standard unbiased first-order oracles, improving the best-known complexity of first-order methods by $O(\epsilon)$ with minimal assumptions. We then provide the matching $\Omega(\epsilon^{-6})$, $\Omega(\epsilon^{-4})$ lower bounds without and with an additional smoothness assumption on $y^*$-aware oracles, respectively. Our results imply that any approach that simulates an algorithm with an $y^*$-aware oracle must suffer the same lower bounds.
Prospective Side Information for Latent MDPs
Oct 11, 2023

In many interactive decision-making settings, there is latent and unobserved information that remains fixed. Consider, for example, a dialogue system, where complete information about a user, such as the user's preferences, is not given. In such an environment, the latent information remains fixed throughout each episode, since the identity of the user does not change during an interaction. This type of environment can be modeled as a Latent Markov Decision Process (LMDP), a special instance of Partially Observed Markov Decision Processes (POMDPs). Previous work established exponential lower bounds in the number of latent contexts for the LMDP class. This puts forward a question: under which natural assumptions a near-optimal policy of an LMDP can be efficiently learned? In this work, we study the class of LMDPs with {\em prospective side information}, when an agent receives additional, weakly revealing, information on the latent context at the beginning of each episode. We show that, surprisingly, this problem is not captured by contemporary settings and algorithms designed for partially observed environments. We then establish that any sample efficient algorithm must suffer at least $\Omega(K^{2/3})$-regret, as opposed to standard $\Omega(\sqrt{K})$ lower bounds, and design an algorithm with a matching upper bound.
On Penalty Methods for Nonconvex Bilevel Optimization and First-Order Stochastic Approximation
Sep 04, 2023In this work, we study first-order algorithms for solving Bilevel Optimization (BO) where the objective functions are smooth but possibly nonconvex in both levels and the variables are restricted to closed convex sets. As a first step, we study the landscape of BO through the lens of penalty methods, in which the upper- and lower-level objectives are combined in a weighted sum with penalty parameter $\sigma > 0$. In particular, we establish a strong connection between the penalty function and the hyper-objective by explicitly characterizing the conditions under which the values and derivatives of the two must be $O(\sigma)$-close. A by-product of our analysis is the explicit formula for the gradient of hyper-objective when the lower-level problem has multiple solutions under minimal conditions, which could be of independent interest. Next, viewing the penalty formulation as $O(\sigma)$-approximation of the original BO, we propose first-order algorithms that find an $\epsilon$-stationary solution by optimizing the penalty formulation with $\sigma = O(\epsilon)$. When the perturbed lower-level problem uniformly satisfies the small-error proximal error-bound (EB) condition, we propose a first-order algorithm that converges to an $\epsilon$-stationary point of the penalty function, using in total $O(\epsilon^{-3})$ and $O(\epsilon^{-7})$ accesses to first-order (stochastic) gradient oracles when the oracle is deterministic and oracles are noisy, respectively. Under an additional assumption on stochastic oracles, we show that the algorithm can be implemented in a fully {\it single-loop} manner, i.e., with $O(1)$ samples per iteration, and achieves the improved oracle-complexity of $O(\epsilon^{-3})$ and $O(\epsilon^{-5})$, respectively.
Feed Two Birds with One Scone: Exploiting Wild Data for Both Out-of-Distribution Generalization and Detection
Jun 15, 2023Modern machine learning models deployed in the wild can encounter both covariate and semantic shifts, giving rise to the problems of out-of-distribution (OOD) generalization and OOD detection respectively. While both problems have received significant research attention lately, they have been pursued independently. This may not be surprising, since the two tasks have seemingly conflicting goals. This paper provides a new unified approach that is capable of simultaneously generalizing to covariate shifts while robustly detecting semantic shifts. We propose a margin-based learning framework that exploits freely available unlabeled data in the wild that captures the environmental test-time OOD distributions under both covariate and semantic shifts. We show both empirically and theoretically that the proposed margin constraint is the key to achieving both OOD generalization and detection. Extensive experiments show the superiority of our framework, outperforming competitive baselines that specialize in either OOD generalization or OOD detection. Code is publicly available at https://github.com/deeplearning-wisc/scone.
A Fully First-Order Method for Stochastic Bilevel Optimization
Jan 26, 2023


We consider stochastic unconstrained bilevel optimization problems when only the first-order gradient oracles are available. While numerous optimization methods have been proposed for tackling bilevel problems, existing methods either tend to require possibly expensive calculations regarding Hessians of lower-level objectives, or lack rigorous finite-time performance guarantees. In this work, we propose a Fully First-order Stochastic Approximation (F2SA) method, and study its non-asymptotic convergence properties. Specifically, we show that F2SA converges to an $\epsilon$-stationary solution of the bilevel problem after $\epsilon^{-7/2}, \epsilon^{-5/2}$, and $\epsilon^{-3/2}$ iterations (each iteration using $O(1)$ samples) when stochastic noises are in both level objectives, only in the upper-level objective, and not present (deterministic settings), respectively. We further show that if we employ momentum-assisted gradient estimators, the iteration complexities can be improved to $\epsilon^{-5/2}, \epsilon^{-4/2}$, and $\epsilon^{-3/2}$, respectively. We demonstrate even superior practical performance of the proposed method over existing second-order based approaches on MNIST data-hypercleaning experiments.