 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Versatile Quadrupedal Skating: Optimal Co-design via Reinforcement Learning and Bayesian Optimization
Mar 19, 2026In this paper, we present a hardware-control co-design approach that enables efficient and versatile roller skating on quadrupedal robots equipped with passive wheels. Passive-wheel skating reduces leg inertia and improves energy efficiency, particularly at high speeds. However, the absence of direct wheel actuation tightly couples mechanical design and control. To unlock the full potential of this modality, we formulate a bilevel optimization framework: an upper-level Bayesian Optimization searches the mechanical design space, while a lower-level Reinforcement Learning trains a motor control policy for each candidate design. The resulting design-policy pairs not only outperform human-engineered baselines, but also exhibit versatile behaviors such as hockey stop (rapid braking by turning sideways to maximize friction) and self-aligning motion (automatic reorientation to improve energy efficiency in the direction of travel), offering the first system-level study of dynamic skating motion on quadrupedal robots.
Articulated-Body Dynamics Network: Dynamics-Grounded Prior for Robot Learning
Mar 19, 2026Recent work in reinforcement learning has shown that incorporating structural priors for articulated robots, such as link connectivity, into policy networks improves learning efficiency. However, dynamics properties, despite their fundamental role in determining how forces and motion propagate through the body, remain largely underexplored as an inductive bias for policy learning. To address this gap, we present the Articulated-Body Dynamics Network (ABD-Net), a novel graph neural network architecture grounded in the computational structure of forward dynamics. Specifically, we adapt the inertia propagation mechanism from the Articulated Body Algorithm, systematically aggregating inertial quantities from child to parent links in a tree-structured manner, while replacing physical quantities with learnable parameters. Embedding ABD-NET into the policy actor enables dynamics-informed representations that capture how actions propagate through the body, leading to efficient and robust policy learning. Through experiments with simulated humanoid, quadruped, and hopper robots, our approach demonstrates increased sample efficiency and generalization to dynamics shifts compared to transformer-based and GNN baselines. We further validate the learned policy on real Unitree G1 and Go2 robots, state-of-the-art humanoid and quadruped platforms, generating dynamic, versatile and robust locomotion behaviors through sim-to-real transfer with real-time inference.
Adversarial Agents: Black-Box Evasion Attacks with Reinforcement Learning
Mar 03, 2025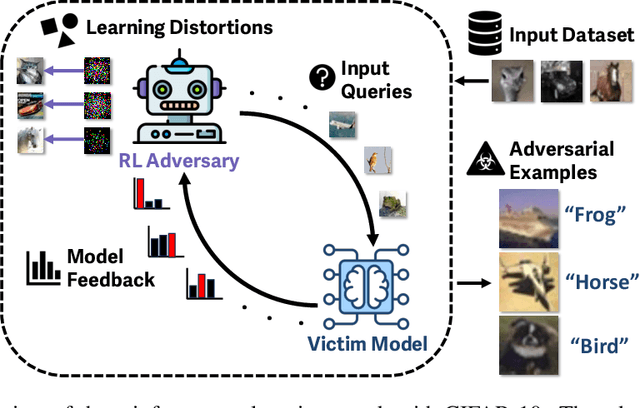

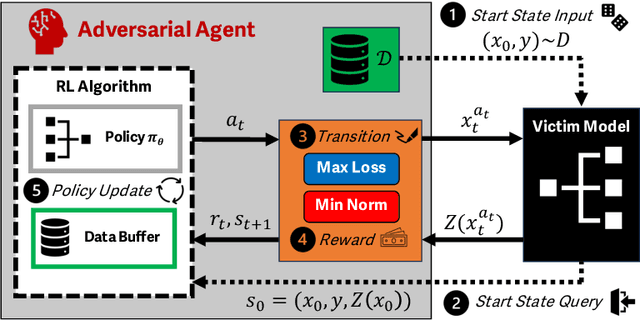

Reinforcement learning (RL) offers powerful techniques for solving complex sequential decision-making tasks from experience. In this paper, we demonstrate how RL can be applied to adversarial machine learning (AML) to develop a new class of attacks that learn to generate adversarial examples: inputs designed to fool machine learning models. Unlike traditional AML methods that craft adversarial examples independently, our RL-based approach retains and exploits past attack experience to improve future attacks. We formulate adversarial example generation as a Markov Decision Process and evaluate RL's ability to (a) learn effective and efficient attack strategies and (b) compete with state-of-the-art AML. On CIFAR-10, our agent increases the success rate of adversarial examples by 19.4% and decreases the median number of victim model queries per adversarial example by 53.2% from the start to the end of training. In a head-to-head comparison with a state-of-the-art image attack, SquareAttack, our approach enables an adversary to generate adversarial examples with 13.1% more success after 5000 episodes of training. From a security perspective, this work demonstrates a powerful new attack vector that uses RL to attack ML models efficiently and at scale.
Future Prediction Can be a Strong Evidence of Good History Representation in Partially Observable Environments
Feb 11, 2024



Learning a good history representation is one of the core challenges of reinforcement learning (RL) in partially observable environments. Recent works have shown the advantages of various auxiliary tasks for facilitating representation learning. However, the effectiveness of such auxiliary tasks has not been fully convincing, especially in partially observable environments that require long-term memorization and inference. In this empirical study, we investigate the effectiveness of future prediction for learning the representations of histories, possibly of extensive length, in partially observable environments. We first introduce an approach that decouples the task of learning history representations from policy optimization via future prediction. Then, our main contributions are two-fold: (a) we demonstrate that the performance of reinforcement learning is strongly correlated with the prediction accuracy of future observations in partially observable environments, and (b) our approach can significantly improve the overall end-to-end approach by preventing high-variance noisy signals from reinforcement learning objectives to influence the representation learning. We illustrate our claims on three types of benchmarks that necessitate the ability to process long histories for high returns.
SPEED: Experimental Design for Policy Evaluation in Linear Heteroscedastic Bandits
Jan 29, 2023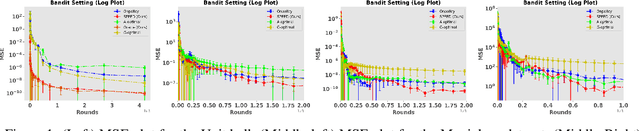

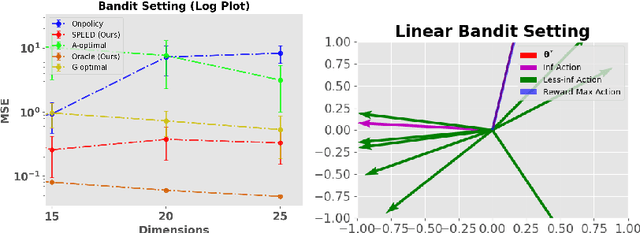
In this paper, we study the problem of optimal data collection for policy evaluation in linear bandits. In policy evaluation, we are given a target policy and asked to estimate the expected cumulative reward it will obtain when executed in an environment formalized as a multi-armed bandit. In this paper, we focus on linear bandit setting with heteroscedastic reward noise. This is the first work that focuses on such an optimal data collection strategy for policy evaluation involving heteroscedastic reward noise in the linear bandit setting. We first formulate an optimal design for weighted least squares estimates in the heteroscedastic linear bandit setting that reduces the MSE of the target policy. We term this as policy-weighted least square estimation and use this formulation to derive the optimal behavior policy for data collection. We then propose a novel algorithm SPEED (Structured Policy Evaluation Experimental Design) that tracks the optimal behavior policy and derive its regret with respect to the optimal behavior policy. Finally, we empirically validate that SPEED leads to policy evaluation with mean squared error comparable to the oracle strategy and significantly lower than simply running the target policy.
Temporal Disentanglement of Representations for Improved Generalisation in Reinforcement Learning
Jul 12, 2022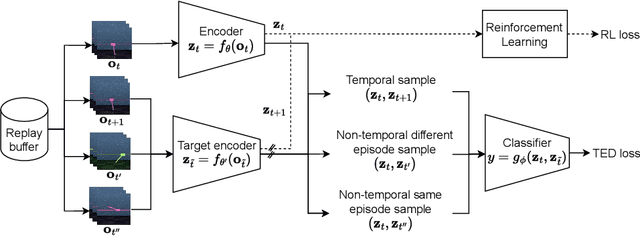

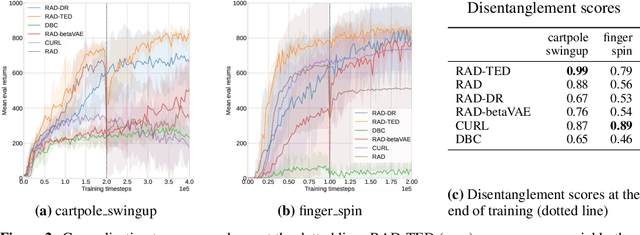
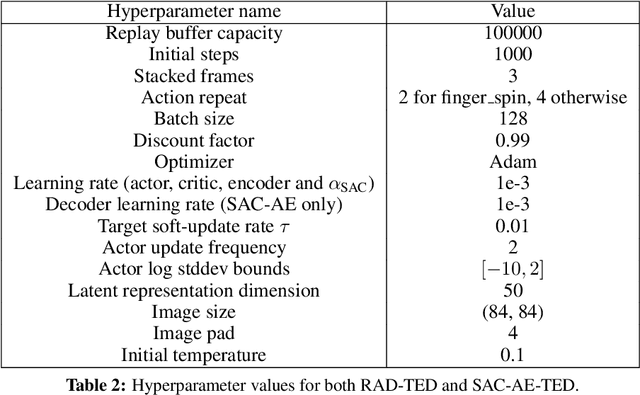
In real-world robotics applications, Reinforcement Learning (RL) agents are often unable to generalise to environment variations that were not observed during training. This issue is intensified for image-based RL where a change in one variable, such as the background colour, can change many pixels in the image, and in turn can change all values in the agent's internal representation of the image. To learn more robust representations, we introduce TEmporal Disentanglement (TED), a self-supervised auxiliary task that leads to disentangled representations using the sequential nature of RL observations. We find empirically that RL algorithms with TED as an auxiliary task adapt more quickly to changes in environment variables with continued training compared to state-of-the-art representation learning methods. Due to the disentangled structure of the representation, we also find that policies trained with TED generalise better to unseen values of variables irrelevant to the task (e.g. background colour) as well as unseen values of variables that affect the optimal policy (e.g. goal positions).
Multi-agent Databases via Independent Learning
May 28, 2022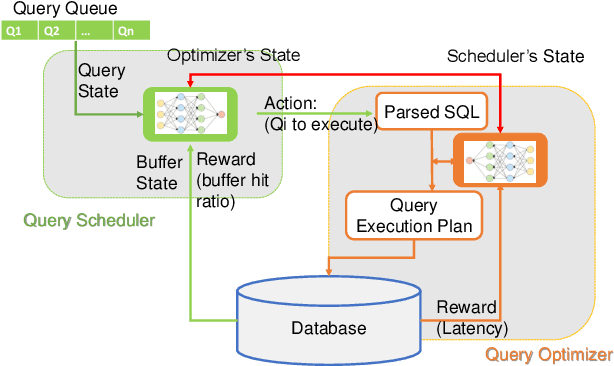

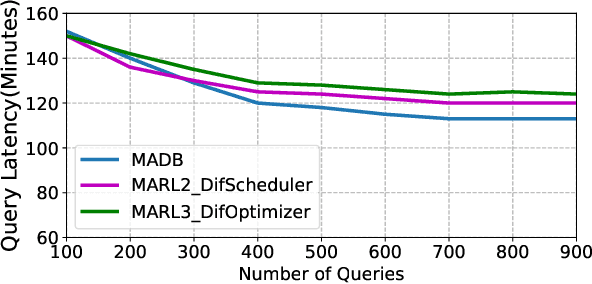
Machine learning is rapidly being used in database research to improve the effectiveness of numerous tasks included but not limited to query optimization, workload scheduling, physical design, etc. essential database components, such as the optimizer, scheduler, and physical designer. Currently, the research focus has been on replacing a single database component responsible for one task by its learning-based counterpart. However, query performance is not simply determined by the performance of a single component, but by the cooperation of multiple ones. As such, learned based database components need to collaborate during both training and execution in order to develop policies that meet end performance goals. Thus, the paper attempts to address the question "Is it possible to design a database consisting of various learned components that cooperatively work to improve end-to-end query latency?". To answer this question, we introduce MADB (Multi-Agent DB), a proof-of-concept system that incorporates a learned query scheduler and a learned query optimizer. MADB leverages a cooperative multi-agent reinforcement learning approach that allows the two components to exchange the context of their decisions with each other and collaboratively work towards reducing the query latency. Preliminary results demonstrate that MADB can outperform the non-cooperative integration of learned components.
Decoupling Exploration and Exploitation in Reinforcement Learning
Jul 22, 2021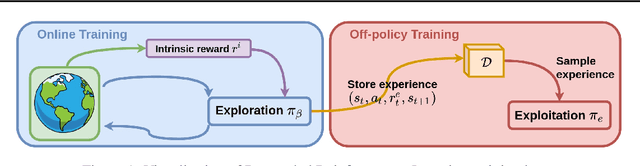

Intrinsic rewards are commonly applied to improve exploration in reinforcement learning. However, these approaches suffer from instability caused by non-stationary reward shaping and strong dependency on hyperparameters. In this work, we propose Decoupled RL (DeRL) which trains separate policies for exploration and exploitation. DeRL can be applied with on-policy and off-policy RL algorithms. We evaluate DeRL algorithms in two sparse-reward environments with multiple types of intrinsic rewards. We show that DeRL is more robust to scaling and speed of decay of intrinsic rewards and converges to the same evaluation returns than intrinsically motivated baselines in fewer interactions.
Reducing Sampling Error in Batch Temporal Difference Learning
Aug 15, 2020Temporal difference (TD) learning is one of the main foundations of modern reinforcement learning. This paper studies the use of TD(0), a canonical TD algorithm, to estimate the value function of a given policy from a batch of data. In this batch setting, we show that TD(0) may converge to an inaccurate value function because the update following an action is weighted according to the number of times that action occurred in the batch -- not the true probability of the action under the given policy. To address this limitation, we introduce \textit{policy sampling error corrected}-TD(0) (PSEC-TD(0)). PSEC-TD(0) first estimates the empirical distribution of actions in each state in the batch and then uses importance sampling to correct for the mismatch between the empirical weighting and the correct weighting for updates following each action. We refine the concept of a certainty-equivalence estimate and argue that PSEC-TD(0) is a more data efficient estimator than TD(0) for a fixed batch of data. Finally, we conduct an empirical evaluation of PSEC-TD(0) on three batch value function learning tasks, with a hyperparameter sensitivity analysis, and show that PSEC-TD(0) produces value function estimates with lower mean squared error than TD(0).
An Imitation from Observation Approach to Sim-to-Real Transfer
Aug 04, 2020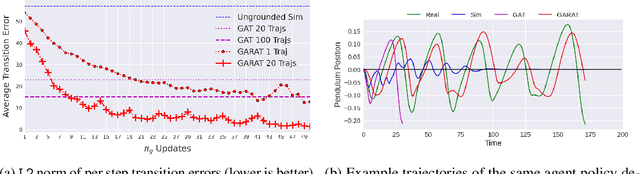

The sim to real transfer problem deals with leveraging large amounts of inexpensive simulation experience to help artificial agents learn behaviors intended for the real world more efficiently. One approach to sim-to-real transfer is using interactions with the real world to make the simulator more realistic, called grounded sim to-real transfer. In this paper, we show that a particular grounded sim-to-real approach, grounded action transformation, is closely related to the problem of imitation from observation IfO, learning behaviors that mimic the observations of behavior demonstrations. After establishing this relationship, we hypothesize that recent state-of-the-art approaches from the IfO literature can be effectively repurposed for such grounded sim-to-real transfer. To validate our hypothesis we derive a new sim-to-real transfer algorithm - generative adversarial reinforced action transformation (GARAT) - based on adversarial imitation from observation techniques. We run experiments in several simulation domains with mismatched dynamics, and find that agents trained with GARAT achieve higher returns in the real world compared to existing black-box sim-to-real methods