 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness Tradeoff in Fine-Tuning
Mar 19, 2025Fine-tuning has become the standard practice for adapting pre-trained (upstream) models to downstream tasks. However, the impact on model robustness is not well understood. In this work, we characterize the robustness-accuracy trade-off in fine-tuning. We evaluate the robustness and accuracy of fine-tuned models over 6 benchmark datasets and 7 different fine-tuning strategies. We observe a consistent trade-off between adversarial robustness and accuracy. Peripheral updates such as BitFit are more effective for simple tasks--over 75% above the average measured with area under the Pareto frontiers on CIFAR-10 and CIFAR-100. In contrast, fine-tuning information-heavy layers, such as attention layers via Compacter, achieves a better Pareto frontier on more complex tasks--57.5% and 34.6% above the average on Caltech-256 and CUB-200, respectively. Lastly, we observe that robustness of fine-tuning against out-of-distribution data closely tracks accuracy. These insights emphasize the need for robustness-aware fine-tuning to ensure reliable real-world deployments.
Adversarial Agents: Black-Box Evasion Attacks with Reinforcement Learning
Mar 03, 2025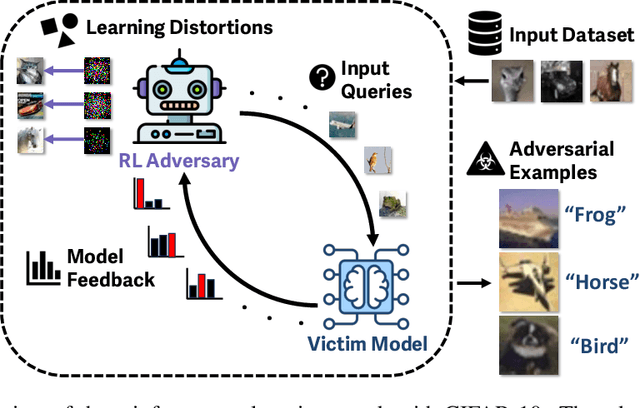

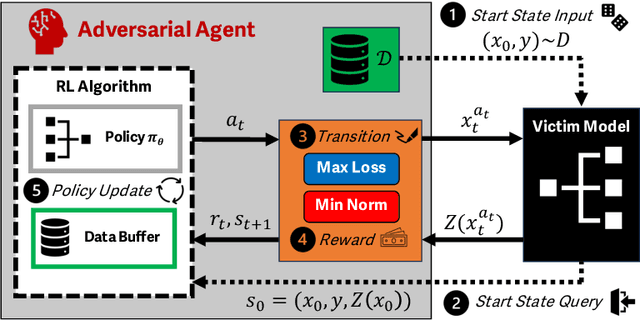

Reinforcement learning (RL) offers powerful techniques for solving complex sequential decision-making tasks from experience. In this paper, we demonstrate how RL can be applied to adversarial machine learning (AML) to develop a new class of attacks that learn to generate adversarial examples: inputs designed to fool machine learning models. Unlike traditional AML methods that craft adversarial examples independently, our RL-based approach retains and exploits past attack experience to improve future attacks. We formulate adversarial example generation as a Markov Decision Process and evaluate RL's ability to (a) learn effective and efficient attack strategies and (b) compete with state-of-the-art AML. On CIFAR-10, our agent increases the success rate of adversarial examples by 19.4% and decreases the median number of victim model queries per adversarial example by 53.2% from the start to the end of training. In a head-to-head comparison with a state-of-the-art image attack, SquareAttack, our approach enables an adversary to generate adversarial examples with 13.1% more success after 5000 episodes of training. From a security perspective, this work demonstrates a powerful new attack vector that uses RL to attack ML models efficiently and at scale.
Targeting Alignment: Extracting Safety Classifiers of Aligned LLMs
Jan 27, 2025



Alignment in large language models (LLMs) is used to enforce guidelines such as safety. Yet, alignment fails in the face of jailbreak attacks that modify inputs to induce unsafe outputs. In this paper, we present and evaluate a method to assess the robustness of LLM alignment. We observe that alignment embeds a safety classifier in the target model that is responsible for deciding between refusal and compliance. We seek to extract an approximation of this classifier, called a surrogate classifier, from the LLM. We develop an algorithm for identifying candidate classifiers from subsets of the LLM model. We evaluate the degree to which the candidate classifiers approximate the model's embedded classifier in benign (F1 score) and adversarial (using surrogates in a white-box attack) settings. Our evaluation shows that the best candidates achieve accurate agreement (an F1 score above 80%) using as little as 20% of the model architecture. Further, we find attacks mounted on the surrogate models can be transferred with high accuracy. For example, a surrogate using only 50% of the Llama 2 model achieved an attack success rate (ASR) of 70%, a substantial improvement over attacking the LLM directly, where we only observed a 22% ASR. These results show that extracting surrogate classifiers is a viable (and highly effective) means for modeling (and therein addressing) the vulnerability of aligned models to jailbreaking attacks.
The Space of Adversarial Strategies
Sep 09, 2022
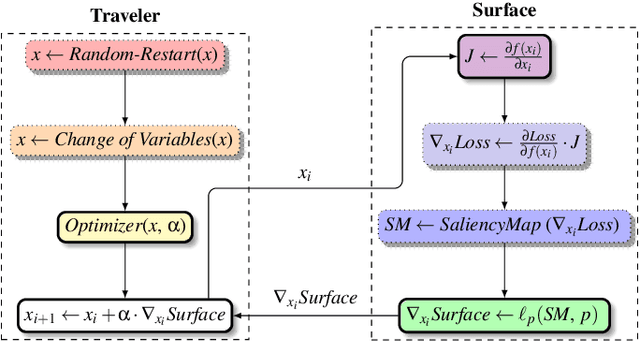
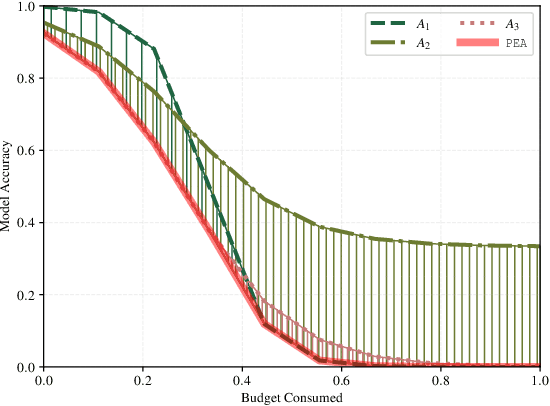

Adversarial examples, inputs designed to induce worst-case behavior in machine learning models, have been extensively studied over the past decade. Yet, our understanding of this phenomenon stems from a rather fragmented pool of knowledge; at present, there are a handful of attacks, each with disparate assumptions in threat models and incomparable definitions of optimality. In this paper, we propose a systematic approach to characterize worst-case (i.e., optimal) adversaries. We first introduce an extensible decomposition of attacks in adversarial machine learning by atomizing attack components into surfaces and travelers. With our decomposition, we enumerate over components to create 576 attacks (568 of which were previously unexplored). Next, we propose the Pareto Ensemble Attack (PEA): a theoretical attack that upper-bounds attack performance. With our new attacks, we measure performance relative to the PEA on: both robust and non-robust models, seven datasets, and three extended lp-based threat models incorporating compute costs, formalizing the Space of Adversarial Strategies. From our evaluation we find that attack performance to be highly contextual: the domain, model robustness, and threat model can have a profound influence on attack efficacy. Our investigation suggests that future studies measuring the security of machine learning should: (1) be contextualized to the domain & threat models, and (2) go beyond the handful of known attacks used today.
On the Robustness of Domain Constraints
May 18, 2021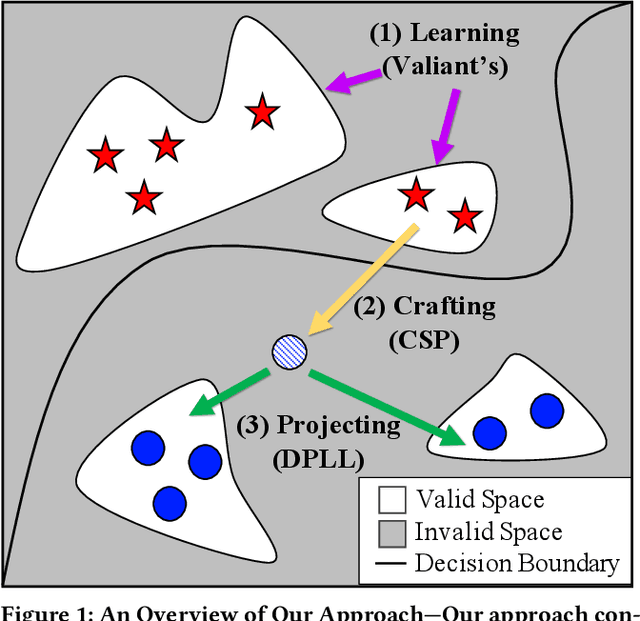

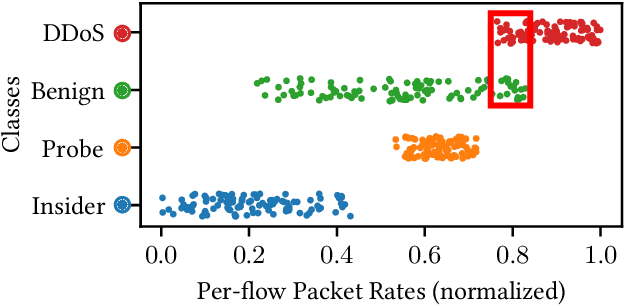
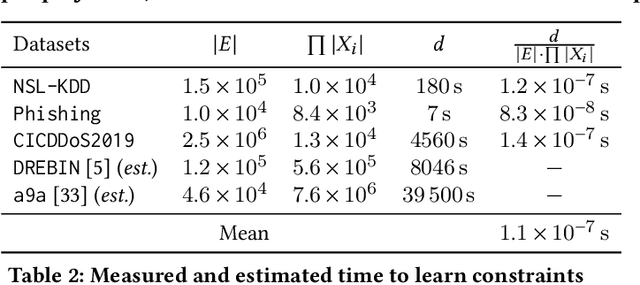
Machine learning is vulnerable to adversarial examples-inputs designed to cause models to perform poorly. However, it is unclear if adversarial examples represent realistic inputs in the modeled domains. Diverse domains such as networks and phishing have domain constraints-complex relationships between features that an adversary must satisfy for an attack to be realized (in addition to any adversary-specific goals). In this paper, we explore how domain constraints limit adversarial capabilities and how adversaries can adapt their strategies to create realistic (constraint-compliant) examples. In this, we develop techniques to learn domain constraints from data, and show how the learned constraints can be integrated into the adversarial crafting process. We evaluate the efficacy of our approach in network intrusion and phishing datasets and find: (1) up to 82% of adversarial examples produced by state-of-the-art crafting algorithms violate domain constraints, (2) domain constraints are robust to adversarial examples; enforcing constraints yields an increase in model accuracy by up to 34%. We observe not only that adversaries must alter inputs to satisfy domain constraints, but that these constraints make the generation of valid adversarial examples far more challenging.