 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness Tradeoff in Fine-Tuning
Mar 19, 2025Fine-tuning has become the standard practice for adapting pre-trained (upstream) models to downstream tasks. However, the impact on model robustness is not well understood. In this work, we characterize the robustness-accuracy trade-off in fine-tuning. We evaluate the robustness and accuracy of fine-tuned models over 6 benchmark datasets and 7 different fine-tuning strategies. We observe a consistent trade-off between adversarial robustness and accuracy. Peripheral updates such as BitFit are more effective for simple tasks--over 75% above the average measured with area under the Pareto frontiers on CIFAR-10 and CIFAR-100. In contrast, fine-tuning information-heavy layers, such as attention layers via Compacter, achieves a better Pareto frontier on more complex tasks--57.5% and 34.6% above the average on Caltech-256 and CUB-200, respectively. Lastly, we observe that robustness of fine-tuning against out-of-distribution data closely tracks accuracy. These insights emphasize the need for robustness-aware fine-tuning to ensure reliable real-world deployments.
Adversarial Agents: Black-Box Evasion Attacks with Reinforcement Learning
Mar 03, 2025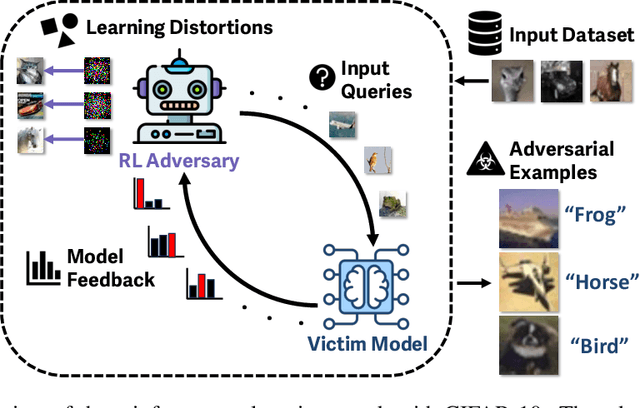

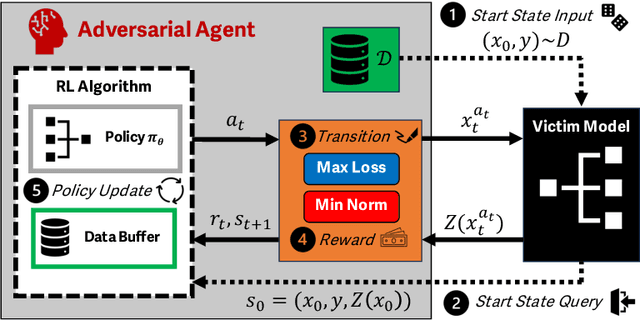

Reinforcement learning (RL) offers powerful techniques for solving complex sequential decision-making tasks from experience. In this paper, we demonstrate how RL can be applied to adversarial machine learning (AML) to develop a new class of attacks that learn to generate adversarial examples: inputs designed to fool machine learning models. Unlike traditional AML methods that craft adversarial examples independently, our RL-based approach retains and exploits past attack experience to improve future attacks. We formulate adversarial example generation as a Markov Decision Process and evaluate RL's ability to (a) learn effective and efficient attack strategies and (b) compete with state-of-the-art AML. On CIFAR-10, our agent increases the success rate of adversarial examples by 19.4% and decreases the median number of victim model queries per adversarial example by 53.2% from the start to the end of training. In a head-to-head comparison with a state-of-the-art image attack, SquareAttack, our approach enables an adversary to generate adversarial examples with 13.1% more success after 5000 episodes of training. From a security perspective, this work demonstrates a powerful new attack vector that uses RL to attack ML models efficiently and at scale.
Targeting Alignment: Extracting Safety Classifiers of Aligned LLMs
Jan 27, 2025



Alignment in large language models (LLMs) is used to enforce guidelines such as safety. Yet, alignment fails in the face of jailbreak attacks that modify inputs to induce unsafe outputs. In this paper, we present and evaluate a method to assess the robustness of LLM alignment. We observe that alignment embeds a safety classifier in the target model that is responsible for deciding between refusal and compliance. We seek to extract an approximation of this classifier, called a surrogate classifier, from the LLM. We develop an algorithm for identifying candidate classifiers from subsets of the LLM model. We evaluate the degree to which the candidate classifiers approximate the model's embedded classifier in benign (F1 score) and adversarial (using surrogates in a white-box attack) settings. Our evaluation shows that the best candidates achieve accurate agreement (an F1 score above 80%) using as little as 20% of the model architecture. Further, we find attacks mounted on the surrogate models can be transferred with high accuracy. For example, a surrogate using only 50% of the Llama 2 model achieved an attack success rate (ASR) of 70%, a substantial improvement over attacking the LLM directly, where we only observed a 22% ASR. These results show that extracting surrogate classifiers is a viable (and highly effective) means for modeling (and therein addressing) the vulnerability of aligned models to jailbreaking attacks.
The Efficacy of Transformer-based Adversarial Attacks in Security Domains
Oct 17, 2023Today, the security of many domains rely on the use of Machine Learning to detect threats, identify vulnerabilities, and safeguard systems from attacks. Recently, transformer architectures have improved the state-of-the-art performance on a wide range of tasks such as malware detection and network intrusion detection. But, before abandoning current approaches to transformers, it is crucial to understand their properties and implications on cybersecurity applications. In this paper, we evaluate the robustness of transformers to adversarial samples for system defenders (i.e., resiliency to adversarial perturbations generated on different types of architectures) and their adversarial strength for system attackers (i.e., transferability of adversarial samples generated by transformers to other target models). To that effect, we first fine-tune a set of pre-trained transformer, Convolutional Neural Network (CNN), and hybrid (an ensemble of transformer and CNN) models to solve different downstream image-based tasks. Then, we use an attack algorithm to craft 19,367 adversarial examples on each model for each task. The transferability of these adversarial examples is measured by evaluating each set on other models to determine which models offer more adversarial strength, and consequently, more robustness against these attacks. We find that the adversarial examples crafted on transformers offer the highest transferability rate (i.e., 25.7% higher than the average) onto other models. Similarly, adversarial examples crafted on other models have the lowest rate of transferability (i.e., 56.7% lower than the average) onto transformers. Our work emphasizes the importance of studying transformer architectures for attacking and defending models in security domains, and suggests using them as the primary architecture in transfer attack settings.