 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAero-World: Action-Conditioned Aerial Video Generation from Inertial Controls
May 19, 2026Foundation video models produce visually impressive results, but their use in embodied AI remains limited because they are primarily trained on natural language rather than low-level control signals. This limitation is especially pronounced for aerial flight, where motion occurs in unconstrained 6-DoF space and small errors in ego-motion can produce large trajectory drift. Generating aerial videos that follow fine-grained inertial actions can support scalable training and evaluation of aerial agents by providing a controllable proxy for real-world or expensive simulation data. To address this problem, we propose \textbf{Aero-World}, a method for converting a pretrained image-to-video diffusion model into a controllable aerial video generator. Aero-World injects sequences of translational acceleration and angular velocity into a pretrained latent diffusion transformer through an action-token stream. A frozen latent-space Physics Probe, trained independently on real video--IMU pairs, provides differentiable inertial-consistency supervision during LoRA finetuning while avoiding computationally expensive video decoding. We further propose \textbf{AeroBench}, a benchmark for evaluating whether generated drone videos adhere to low-level action signals. AeroBench uses Action Alignment Score (AAS) to measure agreement with commanded inertial actions and Physical Consistency Rate (PCR) to measure temporal motion stability. On AeroBench, Aero-World improves mean AAS from 57.7 to 63.6 over action-only finetuning and gives a stronger quality-control trade-off than AirScape, with lower FVD (596.5 vs. 1058.6), higher SSIM (0.595 vs. 0.505), and higher Flow-IMU correlation (0.44 vs. 0.20). These results suggest that frozen Physics Probe supervision is a practical mechanism for adapting pretrained video generators toward more action-aligned aerial motion.
PackCache: A Training-Free Acceleration Method for Unified Autoregressive Video Generation via Compact KV-Cache
Jan 07, 2026A unified autoregressive model is a Transformer-based framework that addresses diverse multimodal tasks (e.g., text, image, video) as a single sequence modeling problem under a shared token space. Such models rely on the KV-cache mechanism to reduce attention computation from O(T^2) to O(T); however, KV-cache size grows linearly with the number of generated tokens, and it rapidly becomes the dominant bottleneck limiting inference efficiency and generative length. Unified autoregressive video generation inherits this limitation. Our analysis reveals that KV-cache tokens exhibit distinct spatiotemporal properties: (i) text and conditioning-image tokens act as persistent semantic anchors that consistently receive high attention, and (ii) attention to previous frames naturally decays with temporal distance. Leveraging these observations, we introduce PackCache, a training-free KV-cache management method that dynamically compacts the KV cache through three coordinated mechanisms: condition anchoring that preserves semantic references, cross-frame decay modeling that allocates cache budget according to temporal distance, and spatially preserving position embedding that maintains coherent 3D structure under cache removal. In terms of efficiency, PackCache accelerates end-to-end generation by 1.7-2.2x on 48-frame long sequences, showcasing its strong potential for enabling longer-sequence video generation. Notably, the final four frames - the portion most impacted by the progressively expanding KV-cache and thus the most expensive segment of the clip - PackCache delivers a 2.6x and 3.7x acceleration on A40 and H200, respectively, for 48-frame videos.
GVD: Guiding Video Diffusion Model for Scalable Video Distillation
Jul 30, 2025To address the larger computation and storage requirements associated with large video datasets, video dataset distillation aims to capture spatial and temporal information in a significantly smaller dataset, such that training on the distilled data has comparable performance to training on all of the data. We propose GVD: Guiding Video Diffusion, the first diffusion-based video distillation method. GVD jointly distills spatial and temporal features, ensuring high-fidelity video generation across diverse actions while capturing essential motion information. Our method's diverse yet representative distillations significantly outperform previous state-of-the-art approaches on the MiniUCF and HMDB51 datasets across 5, 10, and 20 Instances Per Class (IPC). Specifically, our method achieves 78.29 percent of the original dataset's performance using only 1.98 percent of the total number of frames in MiniUCF. Additionally, it reaches 73.83 percent of the performance with just 3.30 percent of the frames in HMDB51. Experimental results across benchmark video datasets demonstrate that GVD not only achieves state-of-the-art performance but can also generate higher resolution videos and higher IPC without significantly increasing computational cost.
Robust Lane Detection with Wavelet-Enhanced Context Modeling and Adaptive Sampling
Mar 24, 2025



Lane detection is critical for autonomous driving and ad-vanced driver assistance systems (ADAS). While recent methods like CLRNet achieve strong performance, they struggle under adverse con-ditions such as extreme weather, illumination changes, occlusions, and complex curves. We propose a Wavelet-Enhanced Feature Pyramid Net-work (WE-FPN) to address these challenges. A wavelet-based non-local block is integrated before the feature pyramid to improve global context modeling, especially for occluded and curved lanes. Additionally, we de-sign an adaptive preprocessing module to enhance lane visibility under poor lighting. An attention-guided sampling strategy further reffnes spa-tial features, boosting accuracy on distant and curved lanes. Experiments on CULane and TuSimple demonstrate that our approach signiffcantly outperforms baselines in challenging scenarios, achieving better robust-ness and accuracy in real-world driving conditions.
On the Robustness Tradeoff in Fine-Tuning
Mar 19, 2025Fine-tuning has become the standard practice for adapting pre-trained (upstream) models to downstream tasks. However, the impact on model robustness is not well understood. In this work, we characterize the robustness-accuracy trade-off in fine-tuning. We evaluate the robustness and accuracy of fine-tuned models over 6 benchmark datasets and 7 different fine-tuning strategies. We observe a consistent trade-off between adversarial robustness and accuracy. Peripheral updates such as BitFit are more effective for simple tasks--over 75% above the average measured with area under the Pareto frontiers on CIFAR-10 and CIFAR-100. In contrast, fine-tuning information-heavy layers, such as attention layers via Compacter, achieves a better Pareto frontier on more complex tasks--57.5% and 34.6% above the average on Caltech-256 and CUB-200, respectively. Lastly, we observe that robustness of fine-tuning against out-of-distribution data closely tracks accuracy. These insights emphasize the need for robustness-aware fine-tuning to ensure reliable real-world deployments.
Alignment and Adversarial Robustness: Are More Human-Like Models More Secure?
Feb 17, 2025Representational alignment refers to the extent to which a model's internal representations mirror biological vision, offering insights into both neural similarity and functional correspondence. Recently, some more aligned models have demonstrated higher resiliency to adversarial examples, raising the question of whether more human-aligned models are inherently more secure. In this work, we conduct a large-scale empirical analysis to systematically investigate the relationship between representational alignment and adversarial robustness. We evaluate 118 models spanning diverse architectures and training paradigms, measuring their neural and behavioral alignment and engineering task performance across 106 benchmarks as well as their adversarial robustness via AutoAttack. Our findings reveal that while average alignment and robustness exhibit a weak overall correlation, specific alignment benchmarks serve as strong predictors of adversarial robustness, particularly those that measure selectivity towards texture or shape. These results suggest that different forms of alignment play distinct roles in model robustness, motivating further investigation into how alignment-driven approaches can be leveraged to build more secure and perceptually-grounded vision models.
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.
The Efficacy of Transformer-based Adversarial Attacks in Security Domains
Oct 17, 2023
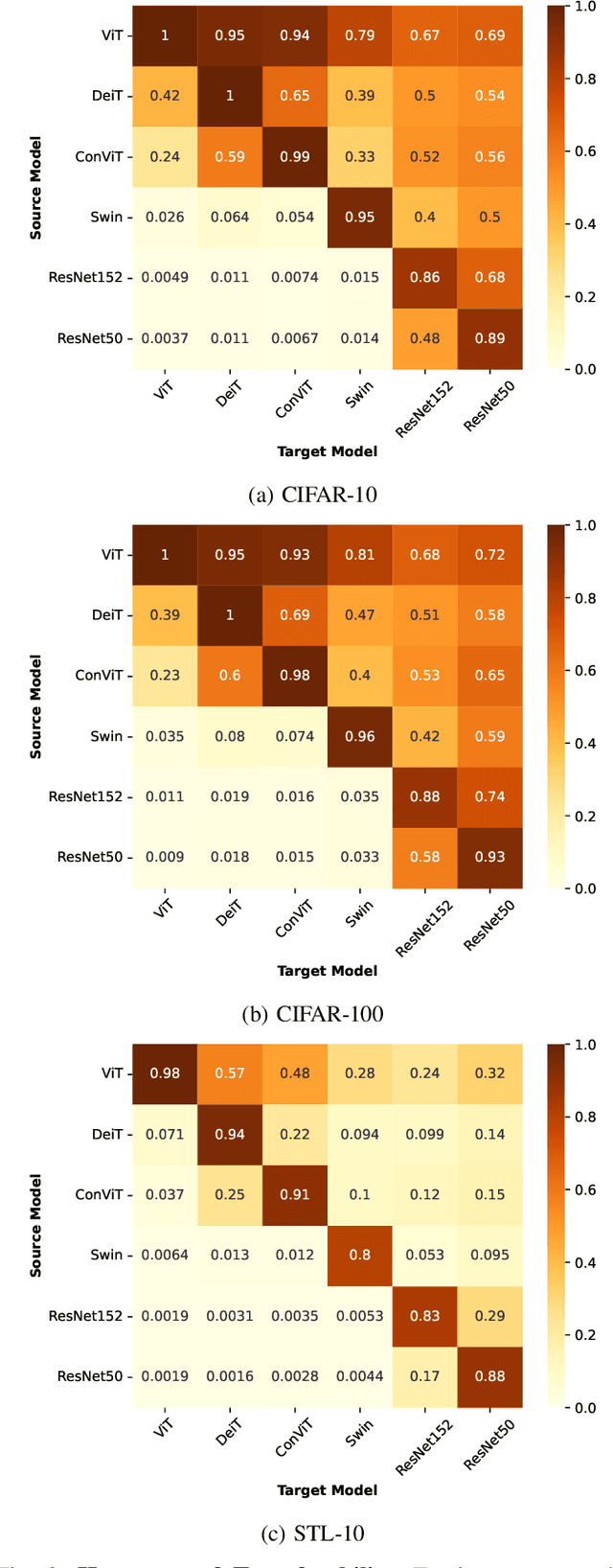
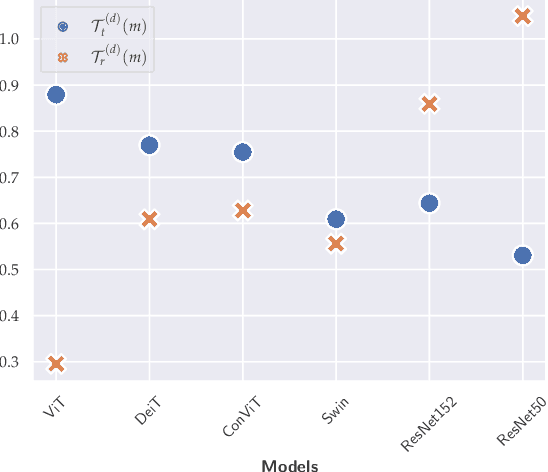
Today, the security of many domains rely on the use of Machine Learning to detect threats, identify vulnerabilities, and safeguard systems from attacks. Recently, transformer architectures have improved the state-of-the-art performance on a wide range of tasks such as malware detection and network intrusion detection. But, before abandoning current approaches to transformers, it is crucial to understand their properties and implications on cybersecurity applications. In this paper, we evaluate the robustness of transformers to adversarial samples for system defenders (i.e., resiliency to adversarial perturbations generated on different types of architectures) and their adversarial strength for system attackers (i.e., transferability of adversarial samples generated by transformers to other target models). To that effect, we first fine-tune a set of pre-trained transformer, Convolutional Neural Network (CNN), and hybrid (an ensemble of transformer and CNN) models to solve different downstream image-based tasks. Then, we use an attack algorithm to craft 19,367 adversarial examples on each model for each task. The transferability of these adversarial examples is measured by evaluating each set on other models to determine which models offer more adversarial strength, and consequently, more robustness against these attacks. We find that the adversarial examples crafted on transformers offer the highest transferability rate (i.e., 25.7% higher than the average) onto other models. Similarly, adversarial examples crafted on other models have the lowest rate of transferability (i.e., 56.7% lower than the average) onto transformers. Our work emphasizes the importance of studying transformer architectures for attacking and defending models in security domains, and suggests using them as the primary architecture in transfer attack settings.
The Trade-off between Universality and Label Efficiency of Representations from Contrastive Learning
Feb 28, 2023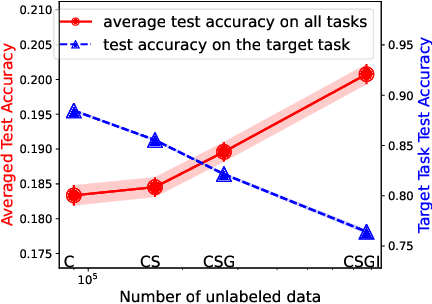
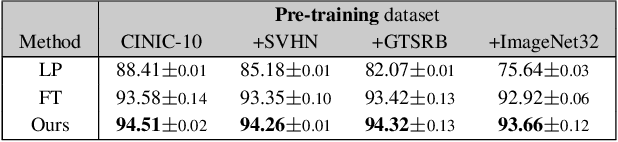

Pre-training representations (a.k.a. foundation models) has recently become a prevalent learning paradigm, where one first pre-trains a representation using large-scale unlabeled data, and then learns simple predictors on top of the representation using small labeled data from the downstream tasks. There are two key desiderata for the representation: label efficiency (the ability to learn an accurate classifier on top of the representation with a small amount of labeled data) and universality (usefulness across a wide range of downstream tasks). In this paper, we focus on one of the most popular instantiations of this paradigm: contrastive learning with linear probing, i.e., learning a linear predictor on the representation pre-trained by contrastive learning. We show that there exists a trade-off between the two desiderata so that one may not be able to achieve both simultaneously. Specifically, we provide analysis using a theoretical data model and show that, while more diverse pre-training data result in more diverse features for different tasks (improving universality), it puts less emphasis on task-specific features, giving rise to larger sample complexity for down-stream supervised tasks, and thus worse prediction performance. Guided by this analysis, we propose a contrastive regularization method to improve the trade-off. We validate our analysis and method empirically with systematic experiments using real-world datasets and foundation models.