 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Good are Foundation Models in Step-by-Step Embodied Reasoning?
Sep 18, 2025
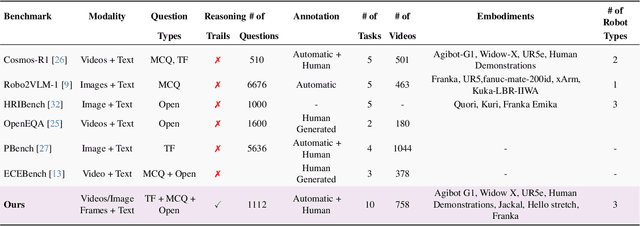

Embodied agents operating in the physical world must make decisions that are not only effective but also safe, spatially coherent, and grounded in context. While recent advances in large multimodal models (LMMs) have shown promising capabilities in visual understanding and language generation, their ability to perform structured reasoning for real-world embodied tasks remains underexplored. In this work, we aim to understand how well foundation models can perform step-by-step reasoning in embodied environments. To this end, we propose the Foundation Model Embodied Reasoning (FoMER) benchmark, designed to evaluate the reasoning capabilities of LMMs in complex embodied decision-making scenarios. Our benchmark spans a diverse set of tasks that require agents to interpret multimodal observations, reason about physical constraints and safety, and generate valid next actions in natural language. We present (i) a large-scale, curated suite of embodied reasoning tasks, (ii) a novel evaluation framework that disentangles perceptual grounding from action reasoning, and (iii) empirical analysis of several leading LMMs under this setting. Our benchmark includes over 1.1k samples with detailed step-by-step reasoning across 10 tasks and 8 embodiments, covering three different robot types. Our results highlight both the potential and current limitations of LMMs in embodied reasoning, pointing towards key challenges and opportunities for future research in robot intelligence. Our data and code will be made publicly available.
A Culturally-diverse Multilingual Multimodal Video Benchmark & Model
Jun 08, 2025Large multimodal models (LMMs) have recently gained attention due to their effectiveness to understand and generate descriptions of visual content. Most existing LMMs are in English language. While few recent works explore multilingual image LMMs, to the best of our knowledge, moving beyond the English language for cultural and linguistic inclusivity is yet to be investigated in the context of video LMMs. In pursuit of more inclusive video LMMs, we introduce a multilingual Video LMM benchmark, named ViMUL-Bench, to evaluate Video LMMs across 14 languages, including both low- and high-resource languages: English, Chinese, Spanish, French, German, Hindi, Arabic, Russian, Bengali, Urdu, Sinhala, Tamil, Swedish, and Japanese. Our ViMUL-Bench is designed to rigorously test video LMMs across 15 categories including eight culturally diverse categories, ranging from lifestyles and festivals to foods and rituals and from local landmarks to prominent cultural personalities. ViMUL-Bench comprises both open-ended (short and long-form) and multiple-choice questions spanning various video durations (short, medium, and long) with 8k samples that are manually verified by native language speakers. In addition, we also introduce a machine translated multilingual video training set comprising 1.2 million samples and develop a simple multilingual video LMM, named ViMUL, that is shown to provide a better tradeoff between high-and low-resource languages for video understanding. We hope our ViMUL-Bench and multilingual video LMM along with a large-scale multilingual video training set will help ease future research in developing cultural and linguistic inclusive multilingual video LMMs. Our proposed benchmark, video LMM and training data will be publicly released at https://mbzuai-oryx.github.io/ViMUL/.
DriveLMM-o1: A Step-by-Step Reasoning Dataset and Large Multimodal Model for Driving Scenario Understanding
Mar 13, 2025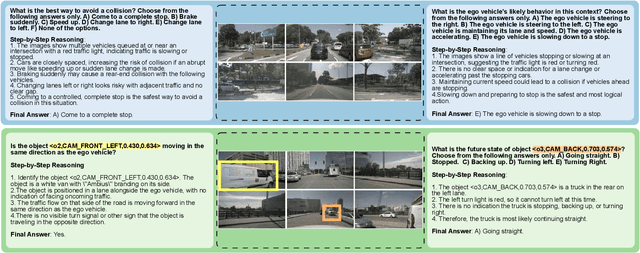
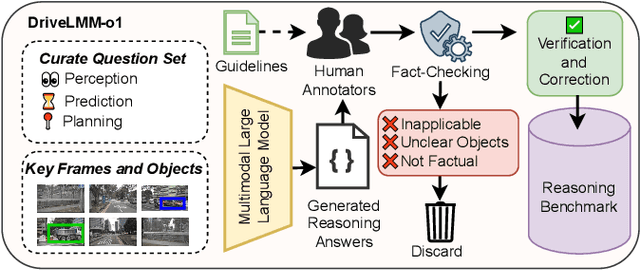
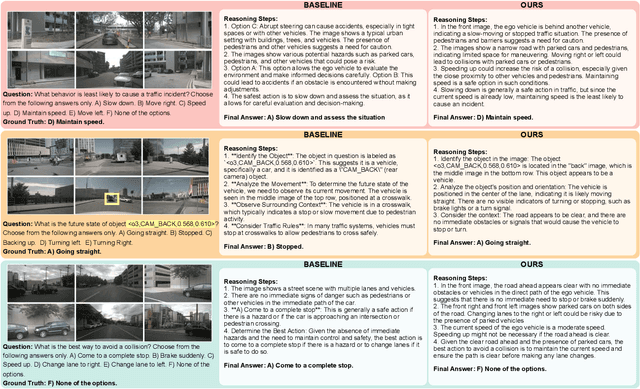
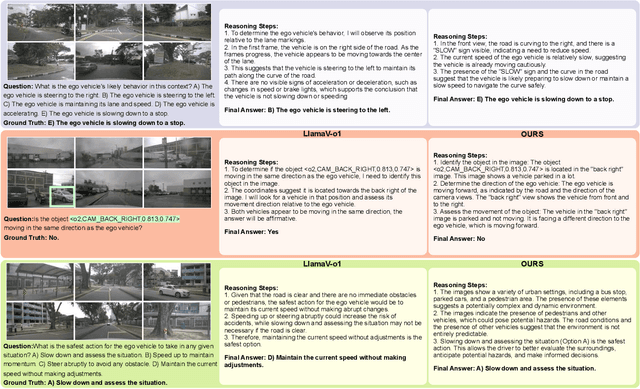
While large multimodal models (LMMs) have demonstrated strong performance across various Visual Question Answering (VQA) tasks, certain challenges require complex multi-step reasoning to reach accurate answers. One particularly challenging task is autonomous driving, which demands thorough cognitive processing before decisions can be made. In this domain, a sequential and interpretive understanding of visual cues is essential for effective perception, prediction, and planning. Nevertheless, common VQA benchmarks often focus on the accuracy of the final answer while overlooking the reasoning process that enables the generation of accurate responses. Moreover, existing methods lack a comprehensive framework for evaluating step-by-step reasoning in realistic driving scenarios. To address this gap, we propose DriveLMM-o1, a new dataset and benchmark specifically designed to advance step-wise visual reasoning for autonomous driving. Our benchmark features over 18k VQA examples in the training set and more than 4k in the test set, covering diverse questions on perception, prediction, and planning, each enriched with step-by-step reasoning to ensure logical inference in autonomous driving scenarios. We further introduce a large multimodal model that is fine-tuned on our reasoning dataset, demonstrating robust performance in complex driving scenarios. In addition, we benchmark various open-source and closed-source methods on our proposed dataset, systematically comparing their reasoning capabilities for autonomous driving tasks. Our model achieves a +7.49% gain in final answer accuracy, along with a 3.62% improvement in reasoning score over the previous best open-source model. Our framework, dataset, and model are available at https://github.com/ayesha-ishaq/DriveLMM-o1.
LlamaV-o1: Rethinking Step-by-step Visual Reasoning in LLMs
Jan 10, 2025



Reasoning is a fundamental capability for solving complex multi-step problems, particularly in visual contexts where sequential step-wise understanding is essential. Existing approaches lack a comprehensive framework for evaluating visual reasoning and do not emphasize step-wise problem-solving. To this end, we propose a comprehensive framework for advancing step-by-step visual reasoning in large language models (LMMs) through three key contributions. First, we introduce a visual reasoning benchmark specifically designed to evaluate multi-step reasoning tasks. The benchmark presents a diverse set of challenges with eight different categories ranging from complex visual perception to scientific reasoning with over 4k reasoning steps in total, enabling robust evaluation of LLMs' abilities to perform accurate and interpretable visual reasoning across multiple steps. Second, we propose a novel metric that assesses visual reasoning quality at the granularity of individual steps, emphasizing both correctness and logical coherence. The proposed metric offers deeper insights into reasoning performance compared to traditional end-task accuracy metrics. Third, we present a new multimodal visual reasoning model, named LlamaV-o1, trained using a multi-step curriculum learning approach, where tasks are progressively organized to facilitate incremental skill acquisition and problem-solving. The proposed LlamaV-o1 is designed for multi-step reasoning and learns step-by-step through a structured training paradigm. Extensive experiments show that our LlamaV-o1 outperforms existing open-source models and performs favorably against close-source proprietary models. Compared to the recent Llava-CoT, our LlamaV-o1 achieves an average score of 67.3 with an absolute gain of 3.8\% across six benchmarks while being 5 times faster during inference scaling. Our benchmark, model, and code are publicly available.
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.