 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldCache: Content-Aware Caching for Accelerated Video World Models
Mar 23, 2026Diffusion Transformers (DiTs) power high-fidelity video world models but remain computationally expensive due to sequential denoising and costly spatio-temporal attention. Training-free feature caching accelerates inference by reusing intermediate activations across denoising steps; however, existing methods largely rely on a Zero-Order Hold assumption i.e., reusing cached features as static snapshots when global drift is small. This often leads to ghosting artifacts, blur, and motion inconsistencies in dynamic scenes. We propose \textbf{WorldCache}, a Perception-Constrained Dynamical Caching framework that improves both when and how to reuse features. WorldCache introduces motion-adaptive thresholds, saliency-weighted drift estimation, optimal approximation via blending and warping, and phase-aware threshold scheduling across diffusion steps. Our cohesive approach enables adaptive, motion-consistent feature reuse without retraining. On Cosmos-Predict2.5-2B evaluated on PAI-Bench, WorldCache achieves \textbf{2.3$\times$} inference speedup while preserving \textbf{99.4\%} of baseline quality, substantially outperforming prior training-free caching approaches. Our code can be accessed on \href{https://umair1221.github.io/World-Cache/}{World-Cache}.
Latent-DARM: Bridging Discrete Diffusion And Autoregressive Models For Reasoning
Mar 10, 2026Most multi-agent systems rely exclusively on autoregressive language models (ARMs) that are based on sequential generation. Although effective for fluent text, ARMs limit global reasoning and plan revision. On the other hand, Discrete Diffusion Language Models (DDLMs) enable non-sequential, globally revisable generation and have shown strong planning capabilities, but their limited text fluency hinders direct collaboration with ARMs. We introduce Latent-DARM, a latent-space communication framework bridging DDLM (planners) and ARM (executors), maximizing collaborative benefits. Across mathematical, scientific, and commonsense reasoning benchmarks, Latent-DARM outperforms text-based interfaces on average, improving accuracy from 27.0% to 36.0% on DART-5 and from 0.0% to 14.0% on AIME2024. Latent-DARM approaches the results of state-of-the-art reasoning models while using less than 2.2% of its token budget. This work advances multi-agent collaboration among agents with heterogeneous models.
MASEval: Extending Multi-Agent Evaluation from Models to Systems
Mar 09, 2026The rapid adoption of LLM-based agentic systems has produced a rich ecosystem of frameworks (smolagents, LangGraph, AutoGen, CAMEL, LlamaIndex, i.a.). Yet existing benchmarks are model-centric: they fix the agentic setup and do not compare other system components. We argue that implementation decisions substantially impact performance, including choices such as topology, orchestration logic, and error handling. MASEval addresses this evaluation gap with a framework-agnostic library that treats the entire system as the unit of analysis. Through a systematic system-level comparison across 3 benchmarks, 3 models, and 3 frameworks, we find that framework choice matters as much as model choice. MASEval allows researchers to explore all components of agentic systems, opening new avenues for principled system design, and practitioners to identify the best implementation for their use case. MASEval is available under the MIT licence https://github.com/parameterlab/MASEval.
Mobile-O: Unified Multimodal Understanding and Generation on Mobile Device
Feb 24, 2026Unified multimodal models can both understand and generate visual content within a single architecture. Existing models, however, remain data-hungry and too heavy for deployment on edge devices. We present Mobile-O, a compact vision-language-diffusion model that brings unified multimodal intelligence to a mobile device. Its core module, the Mobile Conditioning Projector (MCP), fuses vision-language features with a diffusion generator using depthwise-separable convolutions and layerwise alignment. This design enables efficient cross-modal conditioning with minimal computational cost. Trained on only a few million samples and post-trained in a novel quadruplet format (generation prompt, image, question, answer), Mobile-O jointly enhances both visual understanding and generation capabilities. Despite its efficiency, Mobile-O attains competitive or superior performance compared to other unified models, achieving 74% on GenEval and outperforming Show-O and JanusFlow by 5% and 11%, while running 6x and 11x faster, respectively. For visual understanding, Mobile-O surpasses them by 15.3% and 5.1% averaged across seven benchmarks. Running in only ~3s per 512x512 image on an iPhone, Mobile-O establishes the first practical framework for real-time unified multimodal understanding and generation on edge devices. We hope Mobile-O will ease future research in real-time unified multimodal intelligence running entirely on-device with no cloud dependency. Our code, models, datasets, and mobile application are publicly available at https://amshaker.github.io/Mobile-O/
Dr.LLM: Dynamic Layer Routing in LLMs
Oct 14, 2025Large Language Models (LLMs) process every token through all layers of a transformer stack, causing wasted computation on simple queries and insufficient flexibility for harder ones that need deeper reasoning. Adaptive-depth methods can improve efficiency, but prior approaches rely on costly inference-time search, architectural changes, or large-scale retraining, and in practice often degrade accuracy despite efficiency gains. We introduce Dr.LLM, Dynamic routing of Layers for LLMs, a retrofittable framework that equips pretrained models with lightweight per-layer routers deciding to skip, execute, or repeat a block. Routers are trained with explicit supervision: using Monte Carlo Tree Search (MCTS), we derive high-quality layer configurations that preserve or improve accuracy under a compute budget. Our design, windowed pooling for stable routing, focal loss with class balancing, and bottleneck MLP routers, ensures robustness under class imbalance and long sequences. On ARC (logic) and DART (math), Dr.LLM improves accuracy by up to +3.4%p while saving 5 layers per example on average. Routers generalize to out-of-domain tasks (MMLU, GSM8k, AIME, TruthfulQA, SQuADv2, GPQA, PIQA, AGIEval) with only 0.85% accuracy drop while retaining efficiency, and outperform prior routing methods by up to +7.7%p. Overall, Dr.LLM shows that explicitly supervised routers retrofit frozen LLMs for budget-aware, accuracy-driven inference without altering base weights.
How Good are Foundation Models in Step-by-Step Embodied Reasoning?
Sep 18, 2025
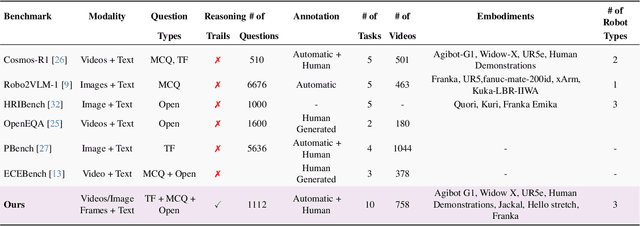
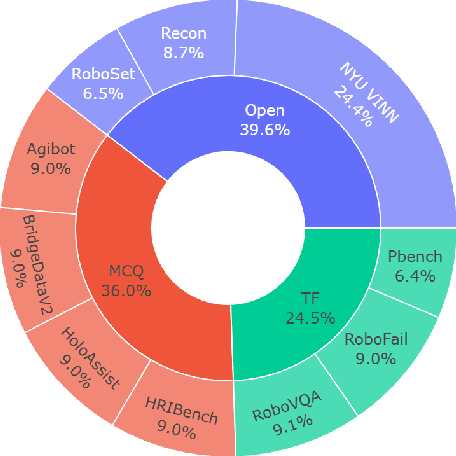

Embodied agents operating in the physical world must make decisions that are not only effective but also safe, spatially coherent, and grounded in context. While recent advances in large multimodal models (LMMs) have shown promising capabilities in visual understanding and language generation, their ability to perform structured reasoning for real-world embodied tasks remains underexplored. In this work, we aim to understand how well foundation models can perform step-by-step reasoning in embodied environments. To this end, we propose the Foundation Model Embodied Reasoning (FoMER) benchmark, designed to evaluate the reasoning capabilities of LMMs in complex embodied decision-making scenarios. Our benchmark spans a diverse set of tasks that require agents to interpret multimodal observations, reason about physical constraints and safety, and generate valid next actions in natural language. We present (i) a large-scale, curated suite of embodied reasoning tasks, (ii) a novel evaluation framework that disentangles perceptual grounding from action reasoning, and (iii) empirical analysis of several leading LMMs under this setting. Our benchmark includes over 1.1k samples with detailed step-by-step reasoning across 10 tasks and 8 embodiments, covering three different robot types. Our results highlight both the potential and current limitations of LMMs in embodied reasoning, pointing towards key challenges and opportunities for future research in robot intelligence. Our data and code will be made publicly available.
Guaranteed Guess: A Language Modeling Approach for CISC-to-RISC Transpilation with Testing Guarantees
Jun 17, 2025



The hardware ecosystem is rapidly evolving, with increasing interest in translating low-level programs across different instruction set architectures (ISAs) in a quick, flexible, and correct way to enhance the portability and longevity of existing code. A particularly challenging class of this transpilation problem is translating between complex- (CISC) and reduced- (RISC) hardware architectures, due to fundamental differences in instruction complexity, memory models, and execution paradigms. In this work, we introduce GG (Guaranteed Guess), an ISA-centric transpilation pipeline that combines the translation power of pre-trained large language models (LLMs) with the rigor of established software testing constructs. Our method generates candidate translations using an LLM from one ISA to another, and embeds such translations within a software-testing framework to build quantifiable confidence in the translation. We evaluate our GG approach over two diverse datasets, enforce high code coverage (>98%) across unit tests, and achieve functional/semantic correctness of 99% on HumanEval programs and 49% on BringupBench programs, respectively. Further, we compare our approach to the state-of-the-art Rosetta 2 framework on Apple Silicon, showcasing 1.73x faster runtime performance, 1.47x better energy efficiency, and 2.41x better memory usage for our transpiled code, demonstrating the effectiveness of GG for real-world CISC-to-RISC translation tasks. We will open-source our codes, data, models, and benchmarks to establish a common foundation for ISA-level code translation research.
VideoMolmo: Spatio-Temporal Grounding Meets Pointing
Jun 05, 2025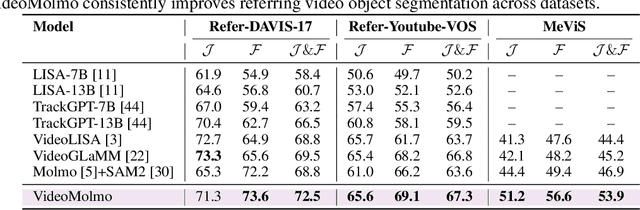
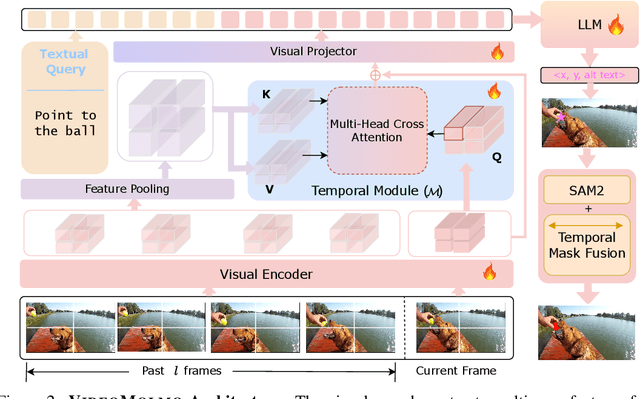

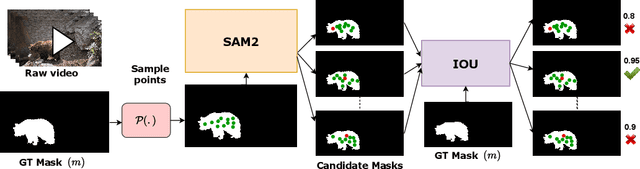
Spatio-temporal localization is vital for precise interactions across diverse domains, from biological research to autonomous navigation and interactive interfaces. Current video-based approaches, while proficient in tracking, lack the sophisticated reasoning capabilities of large language models, limiting their contextual understanding and generalization. We introduce VideoMolmo, a large multimodal model tailored for fine-grained spatio-temporal pointing conditioned on textual descriptions. Building upon the Molmo architecture, VideoMolmo incorporates a temporal module utilizing an attention mechanism to condition each frame on preceding frames, ensuring temporal consistency. Additionally, our novel temporal mask fusion pipeline employs SAM2 for bidirectional point propagation, significantly enhancing coherence across video sequences. This two-step decomposition, i.e., first using the LLM to generate precise pointing coordinates, then relying on a sequential mask-fusion module to produce coherent segmentation, not only simplifies the task for the language model but also enhances interpretability. Due to the lack of suitable datasets, we curate a comprehensive dataset comprising 72k video-caption pairs annotated with 100k object points. To evaluate the generalization of VideoMolmo, we introduce VPoS-Bench, a challenging out-of-distribution benchmark spanning five real-world scenarios: Cell Tracking, Egocentric Vision, Autonomous Driving, Video-GUI Interaction, and Robotics. We also evaluate our model on Referring Video Object Segmentation (Refer-VOS) and Reasoning VOS tasks. In comparison to existing models, VideoMolmo substantially improves spatio-temporal pointing accuracy and reasoning capability. Our code and models are publicly available at https://github.com/mbzuai-oryx/VideoMolmo.
SVRPBench: A Realistic Benchmark for Stochastic Vehicle Routing Problem
May 29, 2025



Robust routing under uncertainty is central to real-world logistics, yet most benchmarks assume static, idealized settings. We present SVRPBench, the first open benchmark to capture high-fidelity stochastic dynamics in vehicle routing at urban scale. Spanning more than 500 instances with up to 1000 customers, it simulates realistic delivery conditions: time-dependent congestion, log-normal delays, probabilistic accidents, and empirically grounded time windows for residential and commercial clients. Our pipeline generates diverse, constraint-rich scenarios, including multi-depot and multi-vehicle setups. Benchmarking reveals that state-of-the-art RL solvers like POMO and AM degrade by over 20% under distributional shift, while classical and metaheuristic methods remain robust. To enable reproducible research, we release the dataset and evaluation suite. SVRPBench challenges the community to design solvers that generalize beyond synthetic assumptions and adapt to real-world uncertainty.
CASS: Nvidia to AMD Transpilation with Data, Models, and Benchmark
May 22, 2025



We introduce \texttt{CASS}, the first large-scale dataset and model suite for cross-architecture GPU code transpilation, targeting both source-level (CUDA~$\leftrightarrow$~HIP) and assembly-level (Nvidia SASS~$\leftrightarrow$~AMD RDNA3) translation. The dataset comprises 70k verified code pairs across host and device, addressing a critical gap in low-level GPU code portability. Leveraging this resource, we train the \texttt{CASS} family of domain-specific language models, achieving 95\% source translation accuracy and 37.5\% assembly translation accuracy, substantially outperforming commercial baselines such as GPT-4o, Claude, and Hipify. Our generated code matches native performance in over 85\% of test cases, preserving runtime and memory behavior. To support rigorous evaluation, we introduce \texttt{CASS-Bench}, a curated benchmark spanning 16 GPU domains with ground-truth execution. All data, models, and evaluation tools are released as open source to foster progress in GPU compiler tooling, binary compatibility, and LLM-guided hardware translation. Dataset and benchmark are on \href{https://huggingface.co/datasets/MBZUAI/cass}{\textcolor{blue}{HuggingFace}}, with code at \href{https://github.com/GustavoStahl/CASS}{\textcolor{blue}{GitHub}}.