 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark and Agentic Framework for Omni-Modal Reasoning and Tool Use in Long Videos
Dec 18, 2025Long-form multimodal video understanding requires integrating vision, speech, and ambient audio with coherent long-range reasoning. Existing benchmarks emphasize either temporal length or multimodal richness, but rarely both and while some incorporate open-ended questions and advanced metrics, they mostly rely on single-score accuracy, obscuring failure modes. We introduce LongShOTBench, a diagnostic benchmark with open-ended, intent-driven questions; single- and multi-turn dialogues; and tasks requiring multimodal reasoning and agentic tool use across video, audio, and speech. Each item includes a reference answer and graded rubric for interpretable, and traceable evaluation. LongShOTBench is produced via a scalable, human-validated pipeline to ensure coverage and reproducibility. All samples in our LongShOTBench are human-verified and corrected. Furthermore, we present LongShOTAgent, an agentic system that analyzes long videos via preprocessing, search, and iterative refinement. On LongShOTBench, state-of-the-art MLLMs show large gaps: Gemini-2.5-Flash achieves 52.95%, open-source models remain below 30%, and LongShOTAgent attains 44.66%. These results underscore the difficulty of real-world long-form video understanding. LongShOTBench provides a practical, reproducible foundation for evaluating and improving MLLMs. All resources are available on GitHub: https://github.com/mbzuai-oryx/longshot.
How Good are Foundation Models in Step-by-Step Embodied Reasoning?
Sep 18, 2025
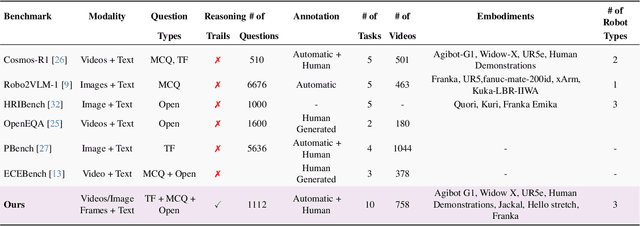

Embodied agents operating in the physical world must make decisions that are not only effective but also safe, spatially coherent, and grounded in context. While recent advances in large multimodal models (LMMs) have shown promising capabilities in visual understanding and language generation, their ability to perform structured reasoning for real-world embodied tasks remains underexplored. In this work, we aim to understand how well foundation models can perform step-by-step reasoning in embodied environments. To this end, we propose the Foundation Model Embodied Reasoning (FoMER) benchmark, designed to evaluate the reasoning capabilities of LMMs in complex embodied decision-making scenarios. Our benchmark spans a diverse set of tasks that require agents to interpret multimodal observations, reason about physical constraints and safety, and generate valid next actions in natural language. We present (i) a large-scale, curated suite of embodied reasoning tasks, (ii) a novel evaluation framework that disentangles perceptual grounding from action reasoning, and (iii) empirical analysis of several leading LMMs under this setting. Our benchmark includes over 1.1k samples with detailed step-by-step reasoning across 10 tasks and 8 embodiments, covering three different robot types. Our results highlight both the potential and current limitations of LMMs in embodied reasoning, pointing towards key challenges and opportunities for future research in robot intelligence. Our data and code will be made publicly available.
InceptionMamba: Efficient Multi-Stage Feature Enhancement with Selective State Space Model for Microscopic Medical Image Segmentation
Jun 13, 2025Accurate microscopic medical image segmentation plays a crucial role in diagnosing various cancerous cells and identifying tumors. Driven by advancements in deep learning, convolutional neural networks (CNNs) and transformer-based models have been extensively studied to enhance receptive fields and improve medical image segmentation task. However, they often struggle to capture complex cellular and tissue structures in challenging scenarios such as background clutter and object overlap. Moreover, their reliance on the availability of large datasets for improved performance, along with the high computational cost, limit their practicality. To address these issues, we propose an efficient framework for the segmentation task, named InceptionMamba, which encodes multi-stage rich features and offers both performance and computational efficiency. Specifically, we exploit semantic cues to capture both low-frequency and high-frequency regions to enrich the multi-stage features to handle the blurred region boundaries (e.g., cell boundaries). These enriched features are input to a hybrid model that combines an Inception depth-wise convolution with a Mamba block, to maintain high efficiency and capture inherent variations in the scales and shapes of the regions of interest. These enriched features along with low-resolution features are fused to get the final segmentation mask. Our model achieves state-of-the-art performance on two challenging microscopic segmentation datasets (SegPC21 and GlaS) and two skin lesion segmentation datasets (ISIC2017 and ISIC2018), while reducing computational cost by about 5 times compared to the previous best performing method.
A Culturally-diverse Multilingual Multimodal Video Benchmark & Model
Jun 08, 2025Large multimodal models (LMMs) have recently gained attention due to their effectiveness to understand and generate descriptions of visual content. Most existing LMMs are in English language. While few recent works explore multilingual image LMMs, to the best of our knowledge, moving beyond the English language for cultural and linguistic inclusivity is yet to be investigated in the context of video LMMs. In pursuit of more inclusive video LMMs, we introduce a multilingual Video LMM benchmark, named ViMUL-Bench, to evaluate Video LMMs across 14 languages, including both low- and high-resource languages: English, Chinese, Spanish, French, German, Hindi, Arabic, Russian, Bengali, Urdu, Sinhala, Tamil, Swedish, and Japanese. Our ViMUL-Bench is designed to rigorously test video LMMs across 15 categories including eight culturally diverse categories, ranging from lifestyles and festivals to foods and rituals and from local landmarks to prominent cultural personalities. ViMUL-Bench comprises both open-ended (short and long-form) and multiple-choice questions spanning various video durations (short, medium, and long) with 8k samples that are manually verified by native language speakers. In addition, we also introduce a machine translated multilingual video training set comprising 1.2 million samples and develop a simple multilingual video LMM, named ViMUL, that is shown to provide a better tradeoff between high-and low-resource languages for video understanding. We hope our ViMUL-Bench and multilingual video LMM along with a large-scale multilingual video training set will help ease future research in developing cultural and linguistic inclusive multilingual video LMMs. Our proposed benchmark, video LMM and training data will be publicly released at https://mbzuai-oryx.github.io/ViMUL/.
Agent-X: Evaluating Deep Multimodal Reasoning in Vision-Centric Agentic Tasks
May 30, 2025Deep reasoning is fundamental for solving complex tasks, especially in vision-centric scenarios that demand sequential, multimodal understanding. However, existing benchmarks typically evaluate agents with fully synthetic, single-turn queries, limited visual modalities, and lack a framework to assess reasoning quality over multiple steps as required in real-world settings. To address this, we introduce Agent-X, a large-scale benchmark for evaluating vision-centric agents multi-step and deep reasoning capabilities in real-world, multimodal settings. Agent- X features 828 agentic tasks with authentic visual contexts, including images, multi-image comparisons, videos, and instructional text. These tasks span six major agentic environments: general visual reasoning, web browsing, security and surveillance, autonomous driving, sports, and math reasoning. Our benchmark requires agents to integrate tool use with explicit, stepwise decision-making in these diverse settings. In addition, we propose a fine-grained, step-level evaluation framework that assesses the correctness and logical coherence of each reasoning step and the effectiveness of tool usage throughout the task. Our results reveal that even the best-performing models, including GPT, Gemini, and Qwen families, struggle to solve multi-step vision tasks, achieving less than 50% full-chain success. These findings highlight key bottlenecks in current LMM reasoning and tool-use capabilities and identify future research directions in vision-centric agentic reasoning models. Our data and code are publicly available at https://github.com/mbzuai-oryx/Agent-X
Open-Set Semi-Supervised Learning for Long-Tailed Medical Datasets
May 20, 2025Many practical medical imaging scenarios include categories that are under-represented but still crucial. The relevance of image recognition models to real-world applications lies in their ability to generalize to these rare classes as well as unseen classes. Real-world generalization requires taking into account the various complexities that can be encountered in the real-world. First, training data is highly imbalanced, which may lead to model exhibiting bias toward the more frequently represented classes. Moreover, real-world data may contain unseen classes that need to be identified, and model performance is affected by the data scarcity. While medical image recognition has been extensively addressed in the literature, current methods do not take into account all the intricacies in the real-world scenarios. To this end, we propose an open-set learning method for highly imbalanced medical datasets using a semi-supervised approach. Understanding the adverse impact of long-tail distribution at the inherent model characteristics, we implement a regularization strategy at the feature level complemented by a classifier normalization technique. We conduct extensive experiments on the publicly available datasets, ISIC2018, ISIC2019, and TissueMNIST with various numbers of labelled samples. Our analysis shows that addressing the impact of long-tail data in classification significantly improves the overall performance of the network in terms of closed-set and open-set accuracies on all datasets. Our code and trained models will be made publicly available at https://github.com/Daniyanaj/OpenLTR.
Tracking Meets Large Multimodal Models for Driving Scenario Understanding
Mar 18, 2025Large Multimodal Models (LMMs) have recently gained prominence in autonomous driving research, showcasing promising capabilities across various emerging benchmarks. LMMs specifically designed for this domain have demonstrated effective perception, planning, and prediction skills. However, many of these methods underutilize 3D spatial and temporal elements, relying mainly on image data. As a result, their effectiveness in dynamic driving environments is limited. We propose to integrate tracking information as an additional input to recover 3D spatial and temporal details that are not effectively captured in the images. We introduce a novel approach for embedding this tracking information into LMMs to enhance their spatiotemporal understanding of driving scenarios. By incorporating 3D tracking data through a track encoder, we enrich visual queries with crucial spatial and temporal cues while avoiding the computational overhead associated with processing lengthy video sequences or extensive 3D inputs. Moreover, we employ a self-supervised approach to pretrain the tracking encoder to provide LMMs with additional contextual information, significantly improving their performance in perception, planning, and prediction tasks for autonomous driving. Experimental results demonstrate the effectiveness of our approach, with a gain of 9.5% in accuracy, an increase of 7.04 points in the ChatGPT score, and 9.4% increase in the overall score over baseline models on DriveLM-nuScenes benchmark, along with a 3.7% final score improvement on DriveLM-CARLA. Our code is available at https://github.com/mbzuai-oryx/TrackingMeetsLMM
DriveLMM-o1: A Step-by-Step Reasoning Dataset and Large Multimodal Model for Driving Scenario Understanding
Mar 13, 2025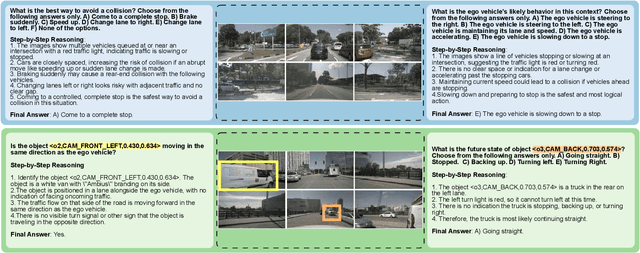
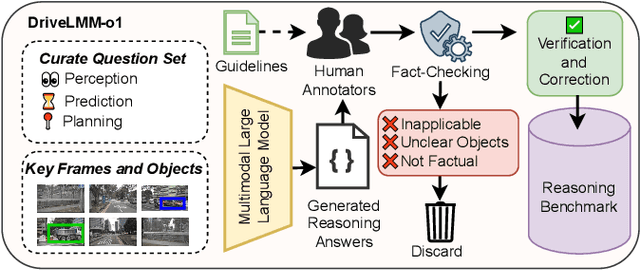
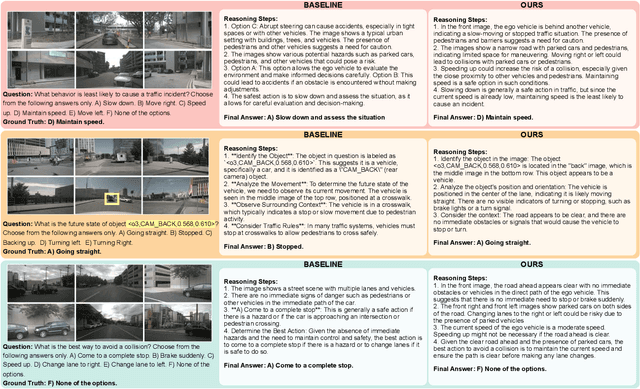
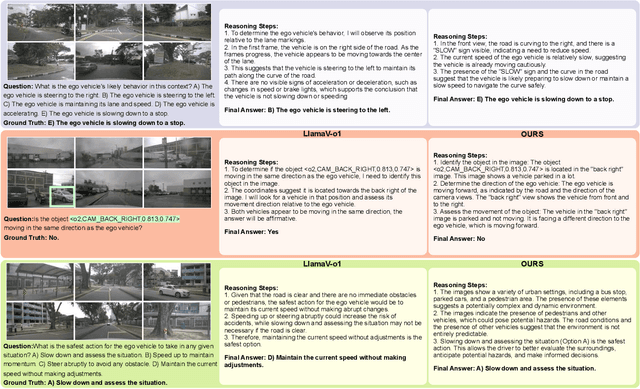
While large multimodal models (LMMs) have demonstrated strong performance across various Visual Question Answering (VQA) tasks, certain challenges require complex multi-step reasoning to reach accurate answers. One particularly challenging task is autonomous driving, which demands thorough cognitive processing before decisions can be made. In this domain, a sequential and interpretive understanding of visual cues is essential for effective perception, prediction, and planning. Nevertheless, common VQA benchmarks often focus on the accuracy of the final answer while overlooking the reasoning process that enables the generation of accurate responses. Moreover, existing methods lack a comprehensive framework for evaluating step-by-step reasoning in realistic driving scenarios. To address this gap, we propose DriveLMM-o1, a new dataset and benchmark specifically designed to advance step-wise visual reasoning for autonomous driving. Our benchmark features over 18k VQA examples in the training set and more than 4k in the test set, covering diverse questions on perception, prediction, and planning, each enriched with step-by-step reasoning to ensure logical inference in autonomous driving scenarios. We further introduce a large multimodal model that is fine-tuned on our reasoning dataset, demonstrating robust performance in complex driving scenarios. In addition, we benchmark various open-source and closed-source methods on our proposed dataset, systematically comparing their reasoning capabilities for autonomous driving tasks. Our model achieves a +7.49% gain in final answer accuracy, along with a 3.62% improvement in reasoning score over the previous best open-source model. Our framework, dataset, and model are available at https://github.com/ayesha-ishaq/DriveLMM-o1.
LLMVoX: Autoregressive Streaming Text-to-Speech Model for Any LLM
Mar 06, 2025Recent advancements in speech-to-speech dialogue systems leverage LLMs for multimodal interactions, yet they remain hindered by fine-tuning requirements, high computational overhead, and text-speech misalignment. Existing speech-enabled LLMs often degrade conversational quality by modifying the LLM, thereby compromising its linguistic capabilities. In contrast, we propose LLMVoX, a lightweight 30M-parameter, LLM-agnostic, autoregressive streaming TTS system that generates high-quality speech with low latency, while fully preserving the capabilities of the base LLM. Our approach achieves a significantly lower Word Error Rate compared to speech-enabled LLMs, while operating at comparable latency and UTMOS score. By decoupling speech synthesis from LLM processing via a multi-queue token streaming system, LLMVoX supports seamless, infinite-length dialogues. Its plug-and-play design also facilitates extension to various tasks with different backbones. Furthermore, LLMVoX generalizes to new languages with only dataset adaptation, attaining a low Character Error Rate on an Arabic speech task. Additionally, we have integrated LLMVoX with a Vision-Language Model to create an omni-model with speech, text, and vision capabilities, without requiring additional multimodal training. Our code base and project page is available at https://mbzuai-oryx.github.io/LLMVoX .
CLIMB-3D: Continual Learning for Imbalanced 3D Instance Segmentation
Feb 24, 2025While 3D instance segmentation has made significant progress, current methods struggle to address realistic scenarios where new categories emerge over time with natural class imbalance. This limitation stems from existing datasets, which typically feature few well-balanced classes. Although few datasets include unbalanced class annotations, they lack the diverse incremental scenarios necessary for evaluating methods under incremental settings. Addressing these challenges requires frameworks that handle both incremental learning and class imbalance. However, existing methods for 3D incremental segmentation rely heavily on large exemplar replay, focusing only on incremental learning while neglecting class imbalance. Moreover, frequency-based tuning for balanced learning is impractical in these setups due to the lack of prior class statistics. To overcome these limitations, we propose a framework to tackle both \textbf{C}ontinual \textbf{L}earning and class \textbf{Imb}alance for \textbf{3D} instance segmentation (\textbf{CLIMB-3D}). Our proposed approach combines Exemplar Replay (ER), Knowledge Distillation (KD), and a novel Imbalance Correction (IC) module. Unlike prior methods, our framework minimizes ER usage, with KD preventing forgetting and supporting the IC module in compiling past class statistics to balance learning of rare classes during incremental updates. To evaluate our framework, we design three incremental scenarios based on class frequency, semantic similarity, and random grouping that aim to mirror real-world dynamics in 3D environments. Experimental results show that our proposed framework achieves state-of-the-art performance, with an increase of up to 16.76\% in mAP compared to the baseline. Code will be available at: \href{https://github.com/vgthengane/CLIMB3D}{https://github.com/vgthengane/CLIMB3D}