 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Understanding: From Geometry and Semantics to Unified Models
Mar 18, 2026Video understanding aims to enable models to perceive, reason about, and interact with the dynamic visual world. In contrast to image understanding, video understanding inherently requires modeling temporal dynamics and evolving visual context, placing stronger demands on spatiotemporal reasoning and making it a foundational problem in computer vision. In this survey, we present a structured overview of video understanding by organizing the literature into three complementary perspectives: low-level video geometry understanding, high-level semantic understanding, and unified video understanding models. We further highlight a broader shift from isolated, task-specific pipelines toward unified modeling paradigms that can be adapted to diverse downstream objectives, enabling a more systematic view of recent progress. By consolidating these perspectives, this survey provides a coherent map of the evolving video understanding landscape, summarizes key modeling trends and design principles, and outlines open challenges toward building robust, scalable, and unified video foundation models.
* A comprehensive survey of video understanding, spanning low-level geometry, high-level semantics, and unified understanding models
CLIMB-3D: Continual Learning for Imbalanced 3D Instance Segmentation
Feb 24, 2025While 3D instance segmentation has made significant progress, current methods struggle to address realistic scenarios where new categories emerge over time with natural class imbalance. This limitation stems from existing datasets, which typically feature few well-balanced classes. Although few datasets include unbalanced class annotations, they lack the diverse incremental scenarios necessary for evaluating methods under incremental settings. Addressing these challenges requires frameworks that handle both incremental learning and class imbalance. However, existing methods for 3D incremental segmentation rely heavily on large exemplar replay, focusing only on incremental learning while neglecting class imbalance. Moreover, frequency-based tuning for balanced learning is impractical in these setups due to the lack of prior class statistics. To overcome these limitations, we propose a framework to tackle both \textbf{C}ontinual \textbf{L}earning and class \textbf{Imb}alance for \textbf{3D} instance segmentation (\textbf{CLIMB-3D}). Our proposed approach combines Exemplar Replay (ER), Knowledge Distillation (KD), and a novel Imbalance Correction (IC) module. Unlike prior methods, our framework minimizes ER usage, with KD preventing forgetting and supporting the IC module in compiling past class statistics to balance learning of rare classes during incremental updates. To evaluate our framework, we design three incremental scenarios based on class frequency, semantic similarity, and random grouping that aim to mirror real-world dynamics in 3D environments. Experimental results show that our proposed framework achieves state-of-the-art performance, with an increase of up to 16.76\% in mAP compared to the baseline. Code will be available at: \href{https://github.com/vgthengane/CLIMB3D}{https://github.com/vgthengane/CLIMB3D}
Foundational Models for 3D Point Clouds: A Survey and Outlook
Jan 30, 2025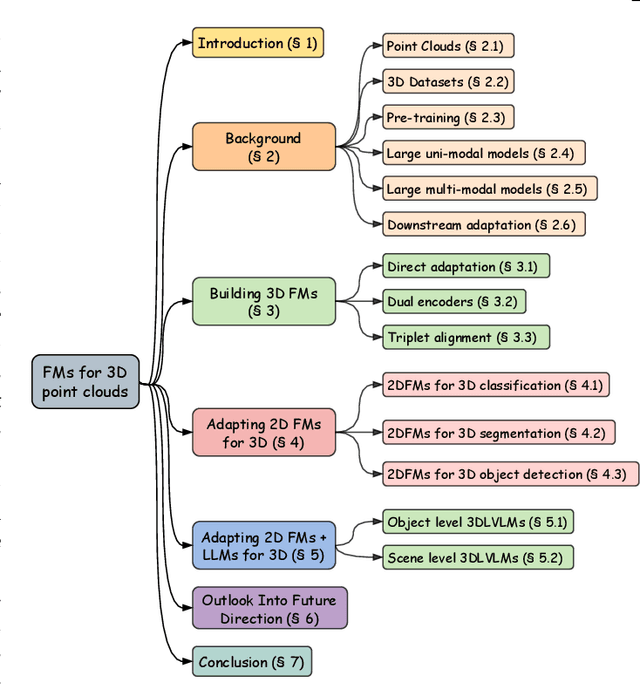
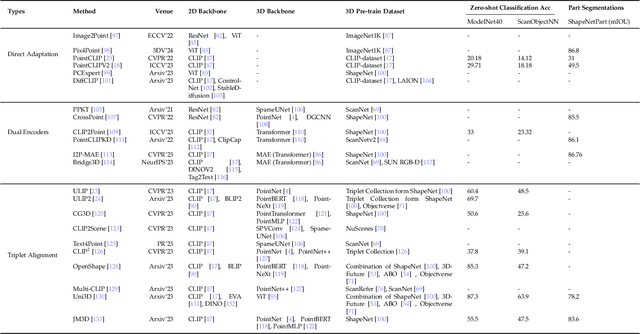
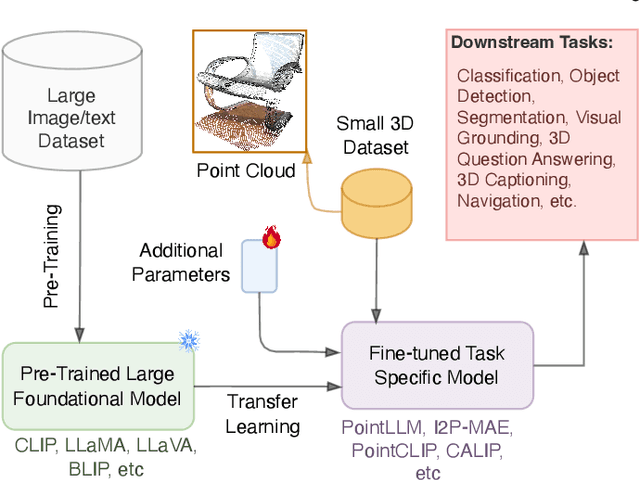

The 3D point cloud representation plays a crucial role in preserving the geometric fidelity of the physical world, enabling more accurate complex 3D environments. While humans naturally comprehend the intricate relationships between objects and variations through a multisensory system, artificial intelligence (AI) systems have yet to fully replicate this capacity. To bridge this gap, it becomes essential to incorporate multiple modalities. Models that can seamlessly integrate and reason across these modalities are known as foundation models (FMs). The development of FMs for 2D modalities, such as images and text, has seen significant progress, driven by the abundant availability of large-scale datasets. However, the 3D domain has lagged due to the scarcity of labelled data and high computational overheads. In response, recent research has begun to explore the potential of applying FMs to 3D tasks, overcoming these challenges by leveraging existing 2D knowledge. Additionally, language, with its capacity for abstract reasoning and description of the environment, offers a promising avenue for enhancing 3D understanding through large pre-trained language models (LLMs). Despite the rapid development and adoption of FMs for 3D vision tasks in recent years, there remains a gap in comprehensive and in-depth literature reviews. This article aims to address this gap by presenting a comprehensive overview of the state-of-the-art methods that utilize FMs for 3D visual understanding. We start by reviewing various strategies employed in the building of various 3D FMs. Then we categorize and summarize use of different FMs for tasks such as perception tasks. Finally, the article offers insights into future directions for research and development in this field. To help reader, we have curated list of relevant papers on the topic: https://github.com/vgthengane/Awesome-FMs-in-3D.
Gradient Correlation Subspace Learning against Catastrophic Forgetting
Mar 04, 2024



Efficient continual learning techniques have been a topic of significant research over the last few years. A fundamental problem with such learning is severe degradation of performance on previously learned tasks, known also as catastrophic forgetting. This paper introduces a novel method to reduce catastrophic forgetting in the context of incremental class learning called Gradient Correlation Subspace Learning (GCSL). The method detects a subspace of the weights that is least affected by previous tasks and projects the weights to train for the new task into said subspace. The method can be applied to one or more layers of a given network architectures and the size of the subspace used can be altered from layer to layer and task to task. Code will be available at \href{https://github.com/vgthengane/GCSL}{https://github.com/vgthengane/GCSL}
Strong Gravitational Lensing Parameter Estimation with Vision Transformer
Oct 09, 2022
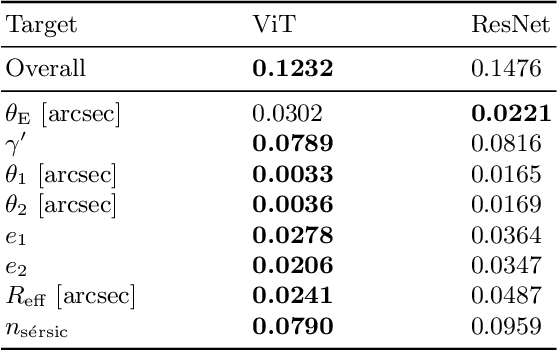
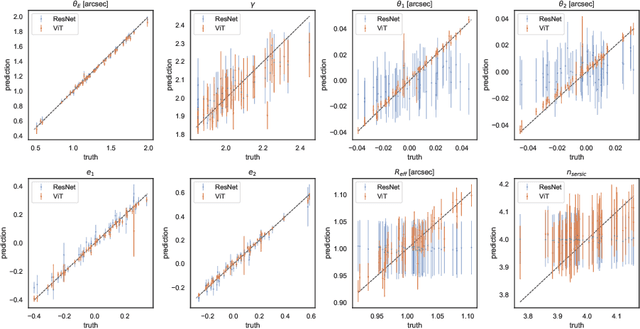
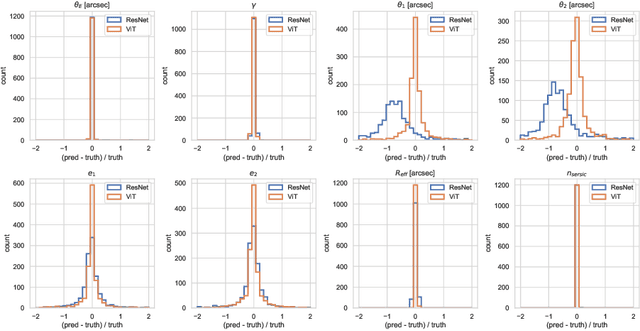
Quantifying the parameters and corresponding uncertainties of hundreds of strongly lensed quasar systems holds the key to resolving one of the most important scientific questions: the Hubble constant ($H_{0}$) tension. The commonly used Markov chain Monte Carlo (MCMC) method has been too time-consuming to achieve this goal, yet recent work has shown that convolution neural networks (CNNs) can be an alternative with seven orders of magnitude improvement in speed. With 31,200 simulated strongly lensed quasar images, we explore the usage of Vision Transformer (ViT) for simulated strong gravitational lensing for the first time. We show that ViT could reach competitive results compared with CNNs, and is specifically good at some lensing parameters, including the most important mass-related parameters such as the center of lens $\theta_{1}$ and $\theta_{2}$, the ellipticities $e_1$ and $e_2$, and the radial power-law slope $\gamma'$. With this promising preliminary result, we believe the ViT (or attention-based) network architecture can be an important tool for strong lensing science for the next generation of surveys. The open source of our code and data is in \url{https://github.com/kuanweih/strong_lensing_vit_resnet}.
CLIP model is an Efficient Continual Learner
Oct 06, 2022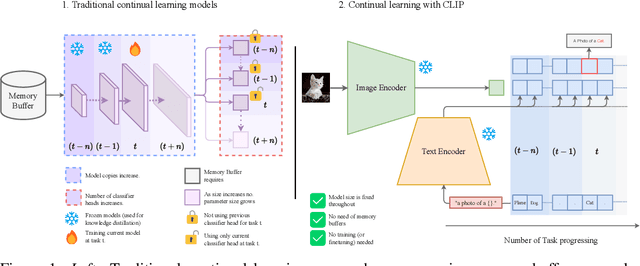
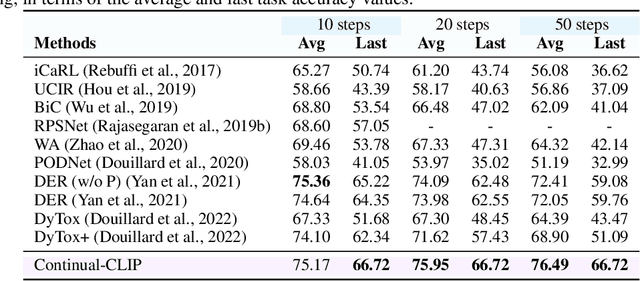
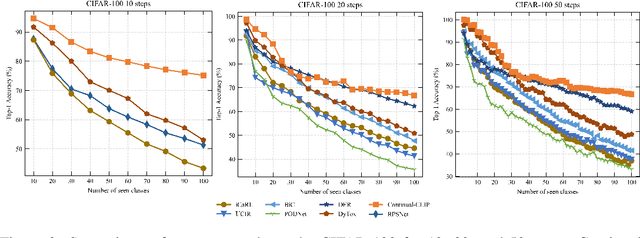
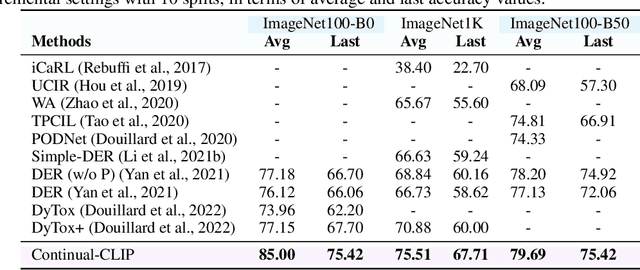
The continual learning setting aims to learn new tasks over time without forgetting the previous ones. The literature reports several significant efforts to tackle this problem with limited or no access to previous task data. Among such efforts, typical solutions offer sophisticated techniques involving memory replay, knowledge distillation, model regularization, and dynamic network expansion. The resulting methods have a retraining cost at each learning task, dedicated memory requirements, and setting-specific design choices. In this work, we show that a frozen CLIP (Contrastive Language-Image Pretraining) model offers astounding continual learning performance without any fine-tuning (zero-shot evaluation). We evaluate CLIP under a variety of settings including class-incremental, domain-incremental and task-agnostic incremental learning on five popular benchmarks (ImageNet-100 & 1K, CORe50, CIFAR-100, and TinyImageNet). Without any bells and whistles, the CLIP model outperforms the state-of-the-art continual learning approaches in the majority of the settings. We show the effect on the CLIP model's performance by varying text inputs with simple prompt templates. To the best of our knowledge, this is the first work to report the CLIP zero-shot performance in a continual setting. We advocate the use of this strong yet embarrassingly simple baseline for future comparisons in the continual learning tasks.