 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen3DTrack: Towards Open-Vocabulary 3D Multi-Object Tracking
Oct 02, 20243D multi-object tracking plays a critical role in autonomous driving by enabling the real-time monitoring and prediction of multiple objects' movements. Traditional 3D tracking systems are typically constrained by predefined object categories, limiting their adaptability to novel, unseen objects in dynamic environments. To address this limitation, we introduce open-vocabulary 3D tracking, which extends the scope of 3D tracking to include objects beyond predefined categories. We formulate the problem of open-vocabulary 3D tracking and introduce dataset splits designed to represent various open-vocabulary scenarios. We propose a novel approach that integrates open-vocabulary capabilities into a 3D tracking framework, allowing for generalization to unseen object classes. Our method effectively reduces the performance gap between tracking known and novel objects through strategic adaptation. Experimental results demonstrate the robustness and adaptability of our method in diverse outdoor driving scenarios. To the best of our knowledge, this work is the first to address open-vocabulary 3D tracking, presenting a significant advancement for autonomous systems in real-world settings. Code, trained models, and dataset splits are available publicly.
Open-YOLO 3D: Towards Fast and Accurate Open-Vocabulary 3D Instance Segmentation
Jun 04, 2024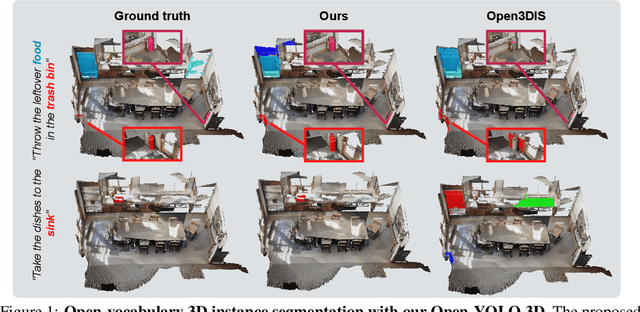
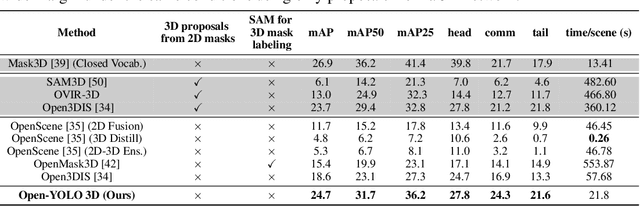
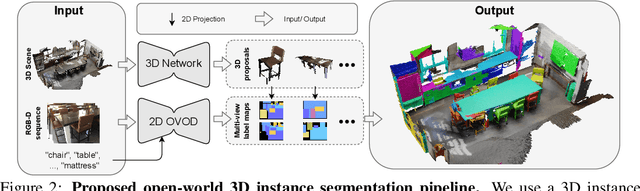
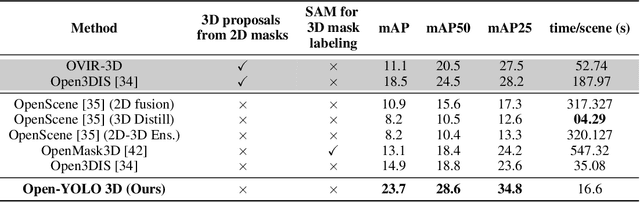
Recent works on open-vocabulary 3D instance segmentation show strong promise, but at the cost of slow inference speed and high computation requirements. This high computation cost is typically due to their heavy reliance on 3D clip features, which require computationally expensive 2D foundation models like Segment Anything (SAM) and CLIP for multi-view aggregation into 3D. As a consequence, this hampers their applicability in many real-world applications that require both fast and accurate predictions. To this end, we propose a fast yet accurate open-vocabulary 3D instance segmentation approach, named Open-YOLO 3D, that effectively leverages only 2D object detection from multi-view RGB images for open-vocabulary 3D instance segmentation. We address this task by generating class-agnostic 3D masks for objects in the scene and associating them with text prompts. We observe that the projection of class-agnostic 3D point cloud instances already holds instance information; thus, using SAM might only result in redundancy that unnecessarily increases the inference time. We empirically find that a better performance of matching text prompts to 3D masks can be achieved in a faster fashion with a 2D object detector. We validate our Open-YOLO 3D on two benchmarks, ScanNet200 and Replica, under two scenarios: (i) with ground truth masks, where labels are required for given object proposals, and (ii) with class-agnostic 3D proposals generated from a 3D proposal network. Our Open-YOLO 3D achieves state-of-the-art performance on both datasets while obtaining up to $\sim$16$\times$ speedup compared to the best existing method in literature. On ScanNet200 val. set, our Open-YOLO 3D achieves mean average precision (mAP) of 24.7\% while operating at 22 seconds per scene. Code and model are available at github.com/aminebdj/OpenYOLO3D.
3D Indoor Instance Segmentation in an Open-World
Sep 25, 2023
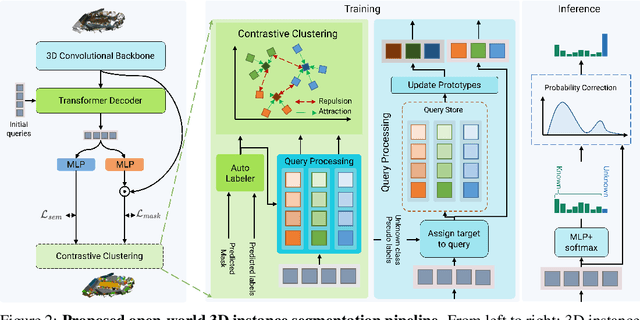
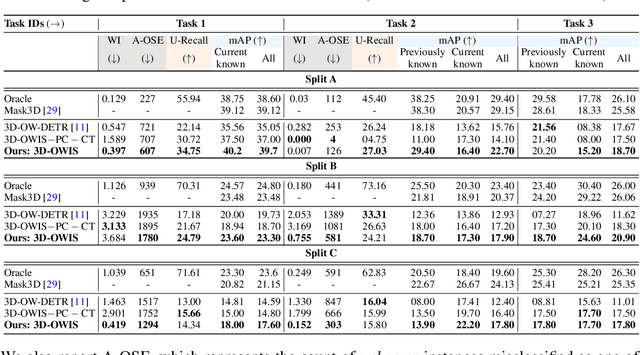
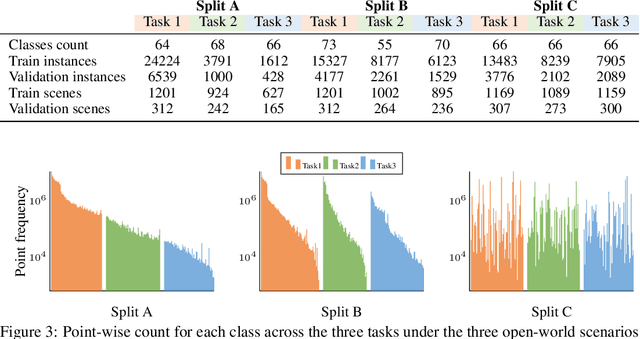
Existing 3D instance segmentation methods typically assume that all semantic classes to be segmented would be available during training and only seen categories are segmented at inference. We argue that such a closed-world assumption is restrictive and explore for the first time 3D indoor instance segmentation in an open-world setting, where the model is allowed to distinguish a set of known classes as well as identify an unknown object as unknown and then later incrementally learning the semantic category of the unknown when the corresponding category labels are available. To this end, we introduce an open-world 3D indoor instance segmentation method, where an auto-labeling scheme is employed to produce pseudo-labels during training and induce separation to separate known and unknown category labels. We further improve the pseudo-labels quality at inference by adjusting the unknown class probability based on the objectness score distribution. We also introduce carefully curated open-world splits leveraging realistic scenarios based on inherent object distribution, region-based indoor scene exploration and randomness aspect of open-world classes. Extensive experiments reveal the efficacy of the proposed contributions leading to promising open-world 3D instance segmentation performance.
Drawing Attention to Detail: Pose Alignment through Self-Attention for Fine-Grained Object Classification
Feb 09, 2023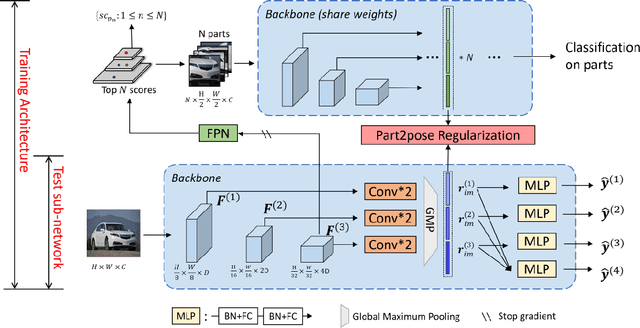


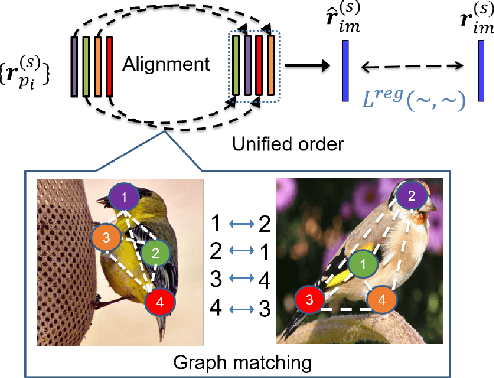
Intra-class variations in the open world lead to various challenges in classification tasks. To overcome these challenges, fine-grained classification was introduced, and many approaches were proposed. Some rely on locating and using distinguishable local parts within images to achieve invariance to viewpoint changes, intra-class differences, and local part deformations. Our approach, which is inspired by P2P-Net, offers an end-to-end trainable attention-based parts alignment module, where we replace the graph-matching component used in it with a self-attention mechanism. The attention module is able to learn the optimal arrangement of parts while attending to each other, before contributing to the global loss.