 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperation-Guided Progressive Human-to-AI Text Transformation Benchmark for Multi-Granularity AI-Text Detection
Jun 04, 2026As AI writing assistants become increasingly integrated into real-world drafting and revision workflows, many documents are no longer purely human-written or AI-generated, but instead result from progressive human-AI co-editing. However, existing AI-text detection benchmarks largely focus on final outputs and provide limited understanding of how AI authorship signals emerge, accumulate, or disappear throughout the revision process. We introduce OpAI-Bench, an operation-guided benchmark for studying progressive human-to-AI text transformation across document, sentence, token, and span granularities. Starting from human-written documents, OpAI-Bench constructs nine sequentially revised versions for each sample under predefined AI coverage levels and five representative AI edit operations, covering four domains while preserving complete authorship provenance at multiple granularities. The benchmark supports comprehensive evaluation with 8 document-level detectors, 7 sentence-level detectors, and 2 fine-grained token/span-level detectors. Experiments reveal that AI-text detectability is governed not only by the proportion of AI-edited content, but also by edit operation, domain, and cumulative revision history. Interestingly, we notice that mixed-authorship intermediate versions are often harder to detect than both fully human and heavily AI-edited endpoints, exposing non-monotonic detection patterns missed by existing benchmarks. OpAI-Bench provides a controlled testbed for analyzing whether, when, and how AI-assisted writing becomes detectable under realistic progressive editing scenarios. Our code and benchmark are available at https://github.com/VILA-Lab/OpAI-Bench.
From Masks to Pixels and Meaning: A New Taxonomy, Benchmark, and Metrics for VLM Image Tampering
Mar 20, 2026Existing tampering detection benchmarks largely rely on object masks, which severely misalign with the true edit signal: many pixels inside a mask are untouched or only trivially modified, while subtle yet consequential edits outside the mask are treated as natural. We reformulate VLM image tampering from coarse region labels to a pixel-grounded, meaning and language-aware task. First, we introduce a taxonomy spanning edit primitives (replace/remove/splice/inpaint/attribute/colorization, etc.) and their semantic class of tampered object, linking low-level changes to high-level understanding. Second, we release a new benchmark with per-pixel tamper maps and paired category supervision to evaluate detection and classification within a unified protocol. Third, we propose a training framework and evaluation metrics that quantify pixel-level correctness with localization to assess confidence or prediction on true edit intensity, and further measure tamper meaning understanding via semantics-aware classification and natural language descriptions for the predicted regions. We also re-evaluate the existing strong segmentation/localization baselines on recent strong tamper detectors and reveal substantial over- and under-scoring using mask-only metrics, and expose failure modes on micro-edits and off-mask changes. Our framework advances the field from masks to pixels, meanings and language descriptions, establishing a rigorous standard for tamper localization, semantic classification and description. Code and benchmark data are available at https://github.com/VILA-Lab/PIXAR.
3D Indoor Instance Segmentation in an Open-World
Sep 25, 2023
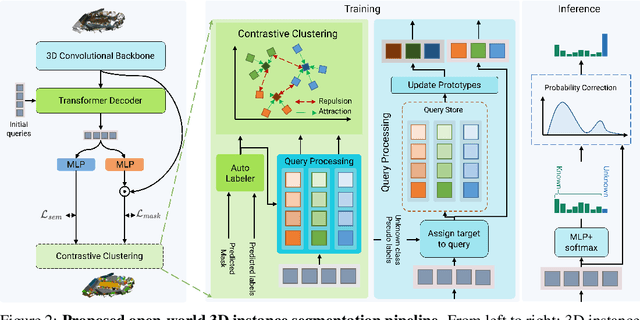
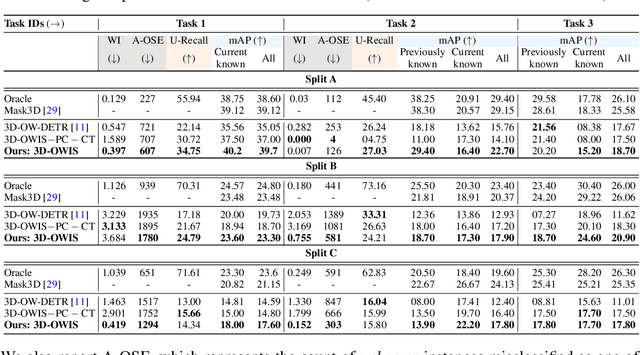
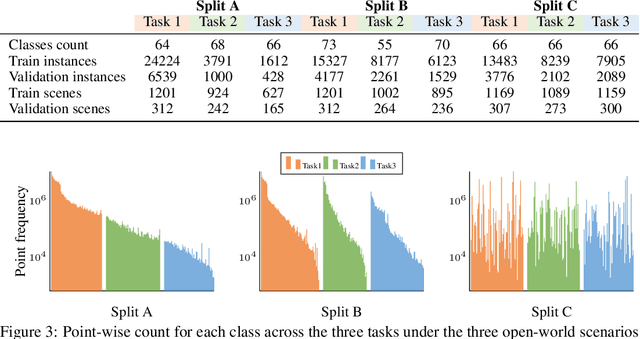
Existing 3D instance segmentation methods typically assume that all semantic classes to be segmented would be available during training and only seen categories are segmented at inference. We argue that such a closed-world assumption is restrictive and explore for the first time 3D indoor instance segmentation in an open-world setting, where the model is allowed to distinguish a set of known classes as well as identify an unknown object as unknown and then later incrementally learning the semantic category of the unknown when the corresponding category labels are available. To this end, we introduce an open-world 3D indoor instance segmentation method, where an auto-labeling scheme is employed to produce pseudo-labels during training and induce separation to separate known and unknown category labels. We further improve the pseudo-labels quality at inference by adjusting the unknown class probability based on the objectness score distribution. We also introduce carefully curated open-world splits leveraging realistic scenarios based on inherent object distribution, region-based indoor scene exploration and randomness aspect of open-world classes. Extensive experiments reveal the efficacy of the proposed contributions leading to promising open-world 3D instance segmentation performance.
PECon: Contrastive Pretraining to Enhance Feature Alignment between CT and EHR Data for Improved Pulmonary Embolism Diagnosis
Aug 27, 2023



Previous deep learning efforts have focused on improving the performance of Pulmonary Embolism(PE) diagnosis from Computed Tomography (CT) scans using Convolutional Neural Networks (CNN). However, the features from CT scans alone are not always sufficient for the diagnosis of PE. CT scans along with electronic heath records (EHR) can provide a better insight into the patients condition and can lead to more accurate PE diagnosis. In this paper, we propose Pulmonary Embolism Detection using Contrastive Learning (PECon), a supervised contrastive pretraining strategy that employs both the patients CT scans as well as the EHR data, aiming to enhance the alignment of feature representations between the two modalities and leverage information to improve the PE diagnosis. In order to achieve this, we make use of the class labels and pull the sample features of the same class together, while pushing away those of the other class. Results show that the proposed work outperforms the existing techniques and achieves state-of-the-art performance on the RadFusion dataset with an F1-score of 0.913, accuracy of 0.90 and an AUROC of 0.943. Furthermore, we also explore the explainability of our approach in comparison to other methods. Our code is publicly available at https://github.com/BioMedIA-MBZUAI/PECon.
To Perceive or Not to Perceive: Lightweight Stacked Hourglass Network
Feb 09, 2023



Human pose estimation (HPE) is a classical task in computer vision that focuses on representing the orientation of a person by identifying the positions of their joints. We design a lighterversion of the stacked hourglass network with minimal loss in performance of the model. The lightweight 2-stacked hourglass has a reduced number of channels with depthwise separable convolutions, residual connections with concatenation, and residual connections between the necks of the hourglasses. The final model has a marginal drop in performance with 79% reduction in the number of parameters and a similar drop in MAdds