 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAURORA: Adaptive Unified Representation for Robust Ultrasound Analysis
Mar 19, 2026Ultrasound images vary widely across scanners, operators, and anatomical targets, which often causes models trained in one setting to generalize poorly to new hospitals and clinical conditions. The Foundation Model Challenge for Ultrasound Image Analysis (FMC-UIA) reflects this difficulty by requiring a single model to handle multiple tasks, including segmentation, detection, classification, and landmark regression across diverse organs and datasets. We propose a unified multi-task framework based on a transformer visual encoder from the Qwen3-VL family. Intermediate token features are projected into spatial feature maps and fused using a lightweight multi-scale feature pyramid, enabling both pixel-level predictions and global reasoning within a shared representation. Each task is handled by a small task-specific prediction head, while training uses task-aware sampling and selective loss balancing to manage heterogeneous supervision and reduce task imbalance. Our method is designed to be simple to optimize and adaptable across a wide range of ultrasound analysis tasks. The performance improved from 67% to 85% on the validation set and achieved an average score of 81.84% on the official test set across all tasks. The code is publicly available at: https://github.com/saitejalekkala33/FMCUIA-ISBI.git
TactileNet: Bridging the Accessibility Gap with AI-Generated Tactile Graphics for Individuals with Vision Impairment
Apr 07, 2025Tactile graphics are essential for providing access to visual information for the 43 million people globally living with vision loss, as estimated by global prevalence data. However, traditional methods for creating these tactile graphics are labor-intensive and struggle to meet demand. We introduce TactileNet, the first comprehensive dataset and AI-driven framework for generating tactile graphics using text-to-image Stable Diffusion (SD) models. By integrating Low-Rank Adaptation (LoRA) and DreamBooth, our method fine-tunes SD models to produce high-fidelity, guideline-compliant tactile graphics while reducing computational costs. Evaluations involving tactile experts show that generated graphics achieve 92.86% adherence to tactile standards and 100% alignment with natural images in posture and features. Our framework also demonstrates scalability, generating 32,000 images (7,050 filtered for quality) across 66 classes, with prompt editing enabling customizable outputs (e.g., adding/removing details). Our work empowers designers to focus on refinement, significantly accelerating accessibility efforts. It underscores the transformative potential of AI for social good, offering a scalable solution to bridge the accessibility gap in education and beyond.
MedPromptX: Grounded Multimodal Prompting for Chest X-ray Diagnosis
Mar 29, 2024Chest X-ray images are commonly used for predicting acute and chronic cardiopulmonary conditions, but efforts to integrate them with structured clinical data face challenges due to incomplete electronic health records (EHR). This paper introduces MedPromptX, the first model to integrate multimodal large language models (MLLMs), few-shot prompting (FP) and visual grounding (VG) to combine imagery with EHR data for chest X-ray diagnosis. A pre-trained MLLM is utilized to complement the missing EHR information, providing a comprehensive understanding of patients' medical history. Additionally, FP reduces the necessity for extensive training of MLLMs while effectively tackling the issue of hallucination. Nevertheless, the process of determining the optimal number of few-shot examples and selecting high-quality candidates can be burdensome, yet it profoundly influences model performance. Hence, we propose a new technique that dynamically refines few-shot data for real-time adjustment to new patient scenarios. Moreover, VG aids in focusing the model's attention on relevant regions of interest in X-ray images, enhancing the identification of abnormalities. We release MedPromptX-VQA, a new in-context visual question answering dataset encompassing interleaved image and EHR data derived from MIMIC-IV and MIMIC-CXR databases. Results demonstrate the SOTA performance of MedPromptX, achieving an 11% improvement in F1-score compared to the baselines. Code and data are available at https://github.com/BioMedIA-MBZUAI/MedPromptX
Fine-Tuned Large Language Models for Symptom Recognition from Spanish Clinical Text
Jan 28, 2024The accurate recognition of symptoms in clinical reports is significantly important in the fields of healthcare and biomedical natural language processing. These entities serve as essential building blocks for clinical information extraction, enabling retrieval of critical medical insights from vast amounts of textual data. Furthermore, the ability to identify and categorize these entities is fundamental for developing advanced clinical decision support systems, aiding healthcare professionals in diagnosis and treatment planning. In this study, we participated in SympTEMIST, a shared task on the detection of symptoms, signs and findings in Spanish medical documents. We combine a set of large language models fine-tuned with the data released by the organizers.
Improving Pseudo-labelling and Enhancing Robustness for Semi-Supervised Domain Generalization
Jan 25, 2024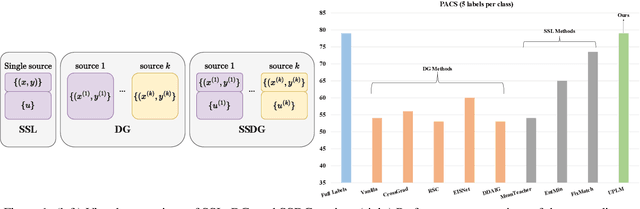
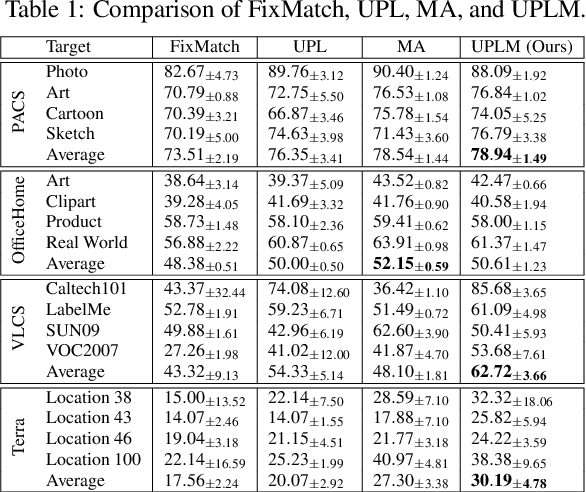
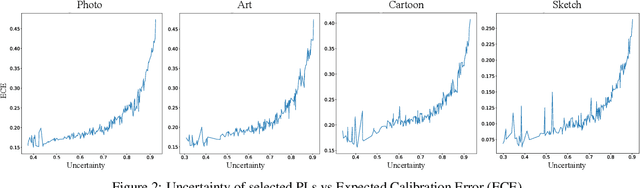
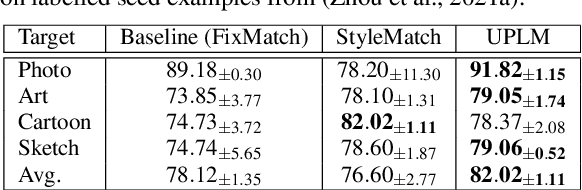
Beyond attaining domain generalization (DG), visual recognition models should also be data-efficient during learning by leveraging limited labels. We study the problem of Semi-Supervised Domain Generalization (SSDG) which is crucial for real-world applications like automated healthcare. SSDG requires learning a cross-domain generalizable model when the given training data is only partially labelled. Empirical investigations reveal that the DG methods tend to underperform in SSDG settings, likely because they are unable to exploit the unlabelled data. Semi-supervised learning (SSL) shows improved but still inferior results compared to fully-supervised learning. A key challenge, faced by the best-performing SSL-based SSDG methods, is selecting accurate pseudo-labels under multiple domain shifts and reducing overfitting to source domains under limited labels. In this work, we propose new SSDG approach, which utilizes a novel uncertainty-guided pseudo-labelling with model averaging (UPLM). Our uncertainty-guided pseudo-labelling (UPL) uses model uncertainty to improve pseudo-labelling selection, addressing poor model calibration under multi-source unlabelled data. The UPL technique, enhanced by our novel model averaging (MA) strategy, mitigates overfitting to source domains with limited labels. Extensive experiments on key representative DG datasets suggest that our method demonstrates effectiveness against existing methods. Our code and chosen labelled data seeds are available on GitHub: https://github.com/Adnan-Khan7/UPLM
PECon: Contrastive Pretraining to Enhance Feature Alignment between CT and EHR Data for Improved Pulmonary Embolism Diagnosis
Aug 27, 2023



Previous deep learning efforts have focused on improving the performance of Pulmonary Embolism(PE) diagnosis from Computed Tomography (CT) scans using Convolutional Neural Networks (CNN). However, the features from CT scans alone are not always sufficient for the diagnosis of PE. CT scans along with electronic heath records (EHR) can provide a better insight into the patients condition and can lead to more accurate PE diagnosis. In this paper, we propose Pulmonary Embolism Detection using Contrastive Learning (PECon), a supervised contrastive pretraining strategy that employs both the patients CT scans as well as the EHR data, aiming to enhance the alignment of feature representations between the two modalities and leverage information to improve the PE diagnosis. In order to achieve this, we make use of the class labels and pull the sample features of the same class together, while pushing away those of the other class. Results show that the proposed work outperforms the existing techniques and achieves state-of-the-art performance on the RadFusion dataset with an F1-score of 0.913, accuracy of 0.90 and an AUROC of 0.943. Furthermore, we also explore the explainability of our approach in comparison to other methods. Our code is publicly available at https://github.com/BioMedIA-MBZUAI/PECon.
Optimizing Deep Learning Model Parameters with the Bees Algorithm for Improved Medical Text Classification
Mar 14, 2023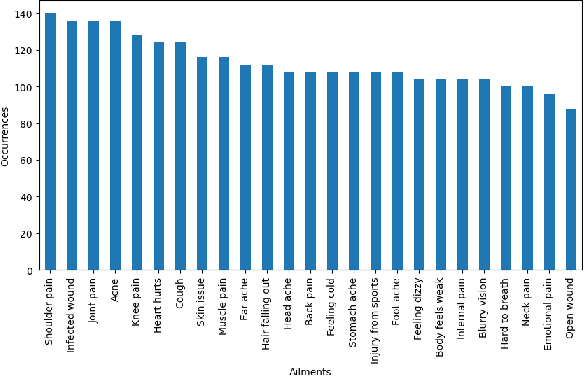
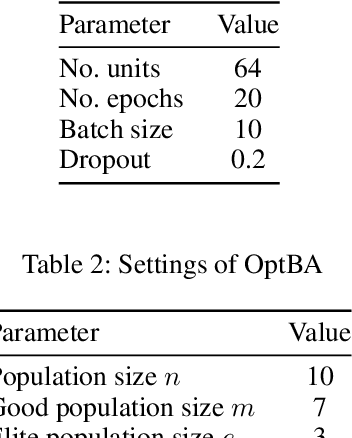
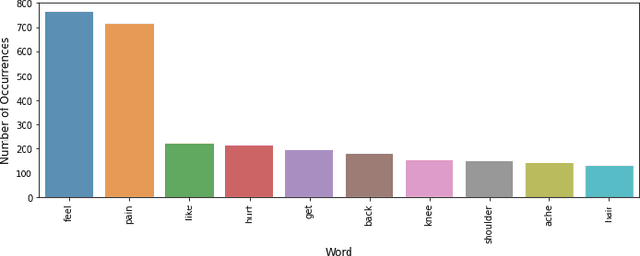

This paper introduces a novel mechanism to obtain the optimal parameters of a deep learning model using the Bees Algorithm, which is a recent promising swarm intelligence algorithm. The optimization problem is to maximize the accuracy of classifying ailments based on medical text given the initial hyper-parameters to be adjusted throughout a definite number of iterations. Experiments included two different datasets: English and Arabic. The highest accuracy achieved is 99.63% on the English dataset using Long Short-Term Memory (LSTM) along with the Bees Algorithm, and 88% on the Arabic dataset using AraBERT.
Deep convolutional forest: a dynamic deep ensemble approach for spam detection in text
Oct 10, 2021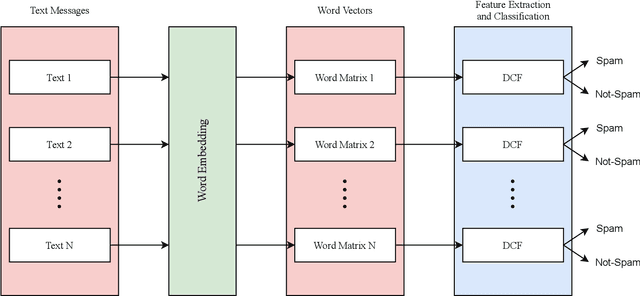

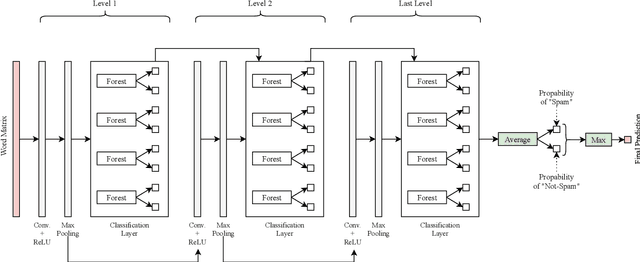

The increase in people's use of mobile messaging services has led to the spread of social engineering attacks like phishing, considering that spam text is one of the main factors in the dissemination of phishing attacks to steal sensitive data such as credit cards and passwords. In addition, rumors and incorrect medical information regarding the COVID-19 pandemic are widely shared on social media leading to people's fear and confusion. Thus, filtering spam content is vital to reduce risks and threats. Previous studies relied on machine learning and deep learning approaches for spam classification, but these approaches have two limitations. Machine learning models require manual feature engineering, whereas deep neural networks require a high computational cost. This paper introduces a dynamic deep ensemble model for spam detection that adjusts its complexity and extracts features automatically. The proposed model utilizes convolutional and pooling layers for feature extraction along with base classifiers such as random forests and extremely randomized trees for classifying texts into spam or legitimate ones. Moreover, the model employs ensemble learning procedures like boosting and bagging. As a result, the model achieved high precision, recall, f1-score and accuracy of 98.38%.